Fourier Prompt Tuning for Modality-Incomplete Scene Segmentation
2401.16923
0
1
🧪
Abstract
Integrating information from multiple modalities enhances the robustness of scene perception systems in autonomous vehicles, providing a more comprehensive and reliable sensory framework. However, the modality incompleteness in multi-modal segmentation remains under-explored. In this work, we establish a task called Modality-Incomplete Scene Segmentation (MISS), which encompasses both system-level modality absence and sensor-level modality errors. To avoid the predominant modality reliance in multi-modal fusion, we introduce a Missing-aware Modal Switch (MMS) strategy to proactively manage missing modalities during training. Utilizing bit-level batch-wise sampling enhances the model's performance in both complete and incomplete testing scenarios. Furthermore, we introduce the Fourier Prompt Tuning (FPT) method to incorporate representative spectral information into a limited number of learnable prompts that maintain robustness against all MISS scenarios. Akin to fine-tuning effects but with fewer tunable parameters (1.1%). Extensive experiments prove the efficacy of our proposed approach, showcasing an improvement of 5.84% mIoU over the prior state-of-the-art parameter-efficient methods in modality missing. The source code is publicly available at https://github.com/RuipingL/MISS.
Create account to get full access
Overview
- The paper explores the problem of "Modality-Incomplete Scene Segmentation (MISS)" in autonomous vehicles, which involves both system-level modality absence and sensor-level modality errors.
- To address this challenge, the researchers introduce a "Missing-aware Modal Switch (MMS)" strategy to manage missing modalities during training, and a "Fourier Prompt Tuning (FPT)" method to incorporate representative spectral information into a limited number of learnable prompts.
- The proposed approach demonstrates significant improvements in segmentation performance compared to previous state-of-the-art parameter-efficient methods, particularly in scenarios with missing modalities.
Plain English Explanation
Autonomous vehicles rely on various sensors, such as cameras, LiDAR, and radar, to perceive their surroundings and make decisions. Integrating information from multiple sensors can enhance the robustness of these scene perception systems, providing a more comprehensive and reliable sensory framework. However, there can be issues with "modality incompleteness," where some sensors may not work properly or be unavailable.
The researchers in this paper have established a new task called "Modality-Incomplete Scene Segmentation (MISS)," which considers both system-level modality absence (e.g., a sensor failure) and sensor-level modality errors (e.g., sensor malfunction). To address this challenge, they have introduced two key strategies:
-
Missing-aware Modal Switch (MMS): This technique proactively manages missing modalities during the training process, preventing the model from becoming overly reliant on any single modality. This helps the model perform well even when some sensors are not working correctly.
-
Fourier Prompt Tuning (FPT): This method incorporates representative spectral information into a limited number of learnable prompts, which helps maintain the model's robustness against all MISS scenarios. This is similar to fine-tuning, but with fewer tunable parameters (only 1.1%), making it more efficient.
Through extensive experiments, the researchers have shown that their approach can significantly outperform previous state-of-the-art parameter-efficient methods in scenarios with missing modalities, with an improvement of 5.84% in mean Intersection over Union (mIoU) performance. This demonstrates the effectiveness of their techniques in enhancing the robustness and reliability of autonomous vehicle scene perception systems, even when some sensors are not functioning properly.
Technical Explanation
The paper establishes a new task called "Modality-Incomplete Scene Segmentation (MISS)," which encompasses both system-level modality absence (e.g., a sensor failure) and sensor-level modality errors (e.g., sensor malfunction). To address this challenge, the researchers introduce two key strategies:
-
Missing-aware Modal Switch (MMS): This technique proactively manages missing modalities during the training process. Instead of relying on a predominant modality, the MMS strategy dynamically adjusts the fusion weights based on the presence or absence of different modalities. This helps the model perform well even when some sensors are not working correctly.
-
Fourier Prompt Tuning (FPT): This method incorporates representative spectral information into a limited number of learnable prompts. The FPT approach leverages the Fourier transform to capture the spectral characteristics of the input data, which are then used to initialize the learnable prompts. This helps maintain the model's robustness against all MISS scenarios, similar to fine-tuning but with fewer tunable parameters (only 1.1%), making it more efficient.
The researchers conduct extensive experiments to evaluate the efficacy of their proposed approach. They demonstrate that their method outperforms previous state-of-the-art parameter-efficient methods in scenarios with missing modalities, with an improvement of 5.84% in mean Intersection over Union (mIoU) performance.
Critical Analysis
The paper presents a thoughtful approach to addressing the challenge of "Modality-Incomplete Scene Segmentation (MISS)" in autonomous vehicle perception systems. The researchers' introduction of the MMS strategy and the FPT method are valuable contributions to the field.
One potential limitation of the study is the reliance on specific datasets and scenarios for evaluation. It would be beneficial to see how the proposed techniques perform in a wider range of real-world situations, including situations with more complex or variable missing modalities.
Additionally, the paper could have explored the computational and memory efficiency of the proposed methods in more depth, as this is a crucial consideration for deployment in resource-constrained autonomous vehicle systems.
Overall, the paper presents a solid technical approach and demonstrates the potential of the researchers' strategies to enhance the robustness of scene perception systems in autonomous vehicles. Further research and validation in diverse real-world scenarios would help strengthen the impact of this work.
Conclusion
This paper tackles the critical problem of "Modality-Incomplete Scene Segmentation (MISS)" in autonomous vehicle perception systems. The researchers have introduced two key strategies – the Missing-aware Modal Switch (MMS) and the Fourier Prompt Tuning (FPT) – to address the challenges of system-level modality absence and sensor-level modality errors.
The proposed approach has shown significant improvements in segmentation performance, outperforming previous state-of-the-art parameter-efficient methods by 5.84% in mean Intersection over Union (mIoU). This demonstrates the effectiveness of the researchers' techniques in enhancing the robustness and reliability of autonomous vehicle scene perception, even in the presence of missing or malfunctioning sensors.
The findings of this paper have important implications for the development of more robust and reliable autonomous vehicle systems, which is crucial for ensuring the safety and widespread adoption of this technology. The researchers' work provides a valuable contribution to the field and paves the way for further advancements in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
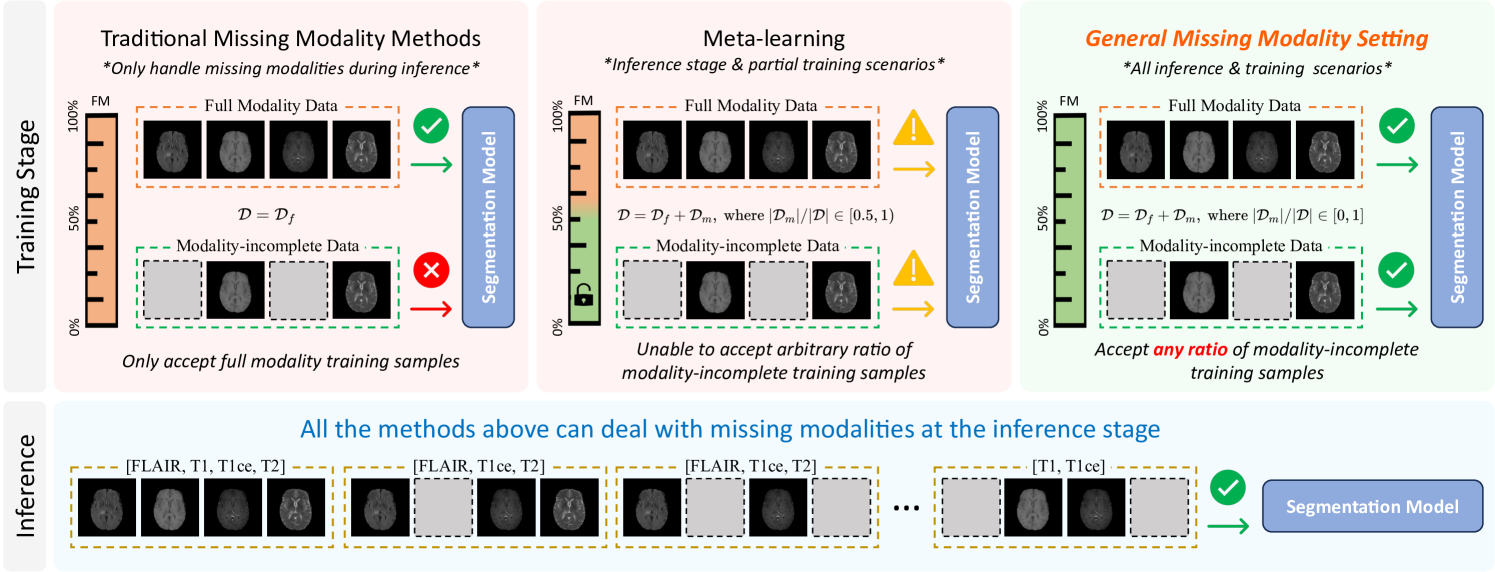
Dealing with All-stage Missing Modality: Towards A Universal Model with Robust Reconstruction and Personalization
Yunpeng Zhao, Cheng Chen, Qing You Pang, Quanzheng Li, Carol Tang, Beng-Ti Ang, Yueming Jin
0
0
Addressing missing modalities presents a critical challenge in multimodal learning. Current approaches focus on developing models that can handle modality-incomplete inputs during inference, assuming that the full set of modalities are available for all the data during training. This reliance on full-modality data for training limits the use of abundant modality-incomplete samples that are often encountered in practical settings. In this paper, we propose a robust universal model with modality reconstruction and model personalization, which can effectively tackle the missing modality at both training and testing stages. Our method leverages a multimodal masked autoencoder to reconstruct the missing modality and masked patches simultaneously, incorporating an innovative distribution approximation mechanism to fully utilize both modality-complete and modality-incomplete data. The reconstructed modalities then contributes to our designed data-model co-distillation scheme to guide the model learning in the presence of missing modalities. Moreover, we propose a CLIP-driven hyper-network to personalize partial model parameters, enabling the model to adapt to each distinct missing modality scenario. Our method has been extensively validated on two brain tumor segmentation benchmarks. Experimental results demonstrate the promising performance of our method, which consistently exceeds previous state-of-the-art approaches under the all-stage missing modality settings with different missing ratios. Code will be available.
6/5/2024
✨
A Multimodal Feature Distillation with CNN-Transformer Network for Brain Tumor Segmentation with Incomplete Modalities
Ming Kang, Fung Fung Ting, Raphael C. -W. Phan, Zongyuan Ge, Chee-Ming Ting
0
0
Existing brain tumor segmentation methods usually utilize multiple Magnetic Resonance Imaging (MRI) modalities in brain tumor images for segmentation, which can achieve better segmentation performance. However, in clinical applications, some modalities are missing due to resource constraints, leading to severe degradation in the performance of methods applying complete modality segmentation. In this paper, we propose a Multimodal feature distillation with Convolutional Neural Network (CNN)-Transformer hybrid network (MCTSeg) for accurate brain tumor segmentation with missing modalities. We first design a Multimodal Feature Distillation (MFD) module to distill feature-level multimodal knowledge into different unimodality to extract complete modality information. We further develop a Unimodal Feature Enhancement (UFE) module to model the relationship between global and local information semantically. Finally, we build a Cross-Modal Fusion (CMF) module to explicitly align the global correlations among different modalities even when some modalities are missing. Complementary features within and across different modalities are refined via the CNN-Transformer hybrid architectures in both the UFE and CMF modules, where local and global dependencies are both captured. Our ablation study demonstrates the importance of the proposed modules with CNN-Transformer networks and the convolutional blocks in Transformer for improving the performance of brain tumor segmentation with missing modalities. Extensive experiments on the BraTS2018 and BraTS2020 datasets show that the proposed MCTSeg framework outperforms the state-of-the-art methods in missing modalities cases. Our code is available at: https://github.com/mkang315/MCTSeg.
4/23/2024
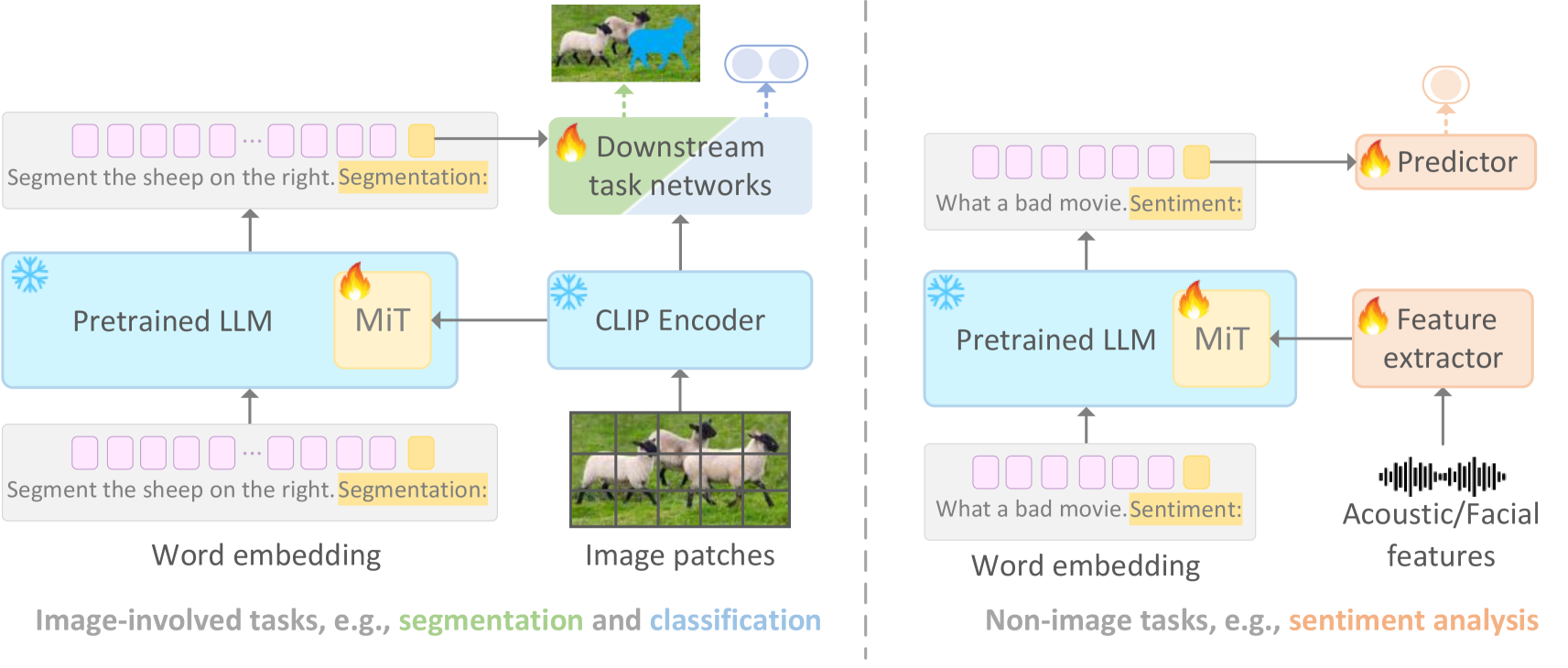
Multimodal Infusion Tuning for Large Models
Hao Sun, Yu Song, Jihong Hu, Xinyao Yu, Jiaqing Liu, Yen-Wei Chen, Lanfen Lin
0
0
Recent advancements in large-scale models have showcased remarkable generalization capabilities in various tasks. However, integrating multimodal processing into these models presents a significant challenge, as it often comes with a high computational burden. To address this challenge, we introduce a new parameter-efficient multimodal tuning strategy for large models in this paper, referred to as Multimodal Infusion Tuning (MiT). MiT leverages decoupled self-attention mechanisms within large language models to effectively integrate information from diverse modalities such as images and acoustics. In MiT, we also design a novel adaptive rescaling strategy at the attention head level, which optimizes the representation of infused multimodal features. Notably, all foundation models are kept frozen during the tuning process to reduce the computational burden and only 2.5% parameters are tunable. We conduct experiments across a range of multimodal tasks, including image-related tasks like referring segmentation and non-image tasks such as sentiment analysis. Our results showcase that MiT achieves state-of-the-art performance in multimodal understanding while significantly reducing computational overhead(10% of previous methods). Moreover, our tuned model exhibits robust reasoning abilities even in complex scenarios.
6/18/2024

Unveiling Incomplete Modality Brain Tumor Segmentation: Leveraging Masked Predicted Auto-Encoder and Divergence Learning
Zhongao Sun, Jiameng Li, Yuhan Wang, Jiarong Cheng, Qing Zhou, Chun Li
0
0
Brain tumor segmentation remains a significant challenge, particularly in the context of multi-modal magnetic resonance imaging (MRI) where missing modality images are common in clinical settings, leading to reduced segmentation accuracy. To address this issue, we propose a novel strategy, which is called masked predicted pre-training, enabling robust feature learning from incomplete modality data. Additionally, in the fine-tuning phase, we utilize a knowledge distillation technique to align features between complete and missing modality data, simultaneously enhancing model robustness. Notably, we leverage the Holder pseudo-divergence instead of the KLD for distillation loss, offering improve mathematical interpretability and properties. Extensive experiments on the BRATS2018 and BRATS2020 datasets demonstrate significant performance enhancements compared to existing state-of-the-art methods.
6/14/2024