Combining Automated Optimisation of Hyperparameters and Reward Shape

0
Sign in to get full access
Overview
- This paper explores a novel approach to combining automated optimization of hyperparameters and reward shaping in reinforcement learning (RL) agents.
- The authors propose a hybrid framework that integrates hyperparameter optimization and reward function design, aiming to improve the performance and generalization of RL agents.
- They demonstrate the effectiveness of their approach on several RL tasks, showing that it can outperform traditional methods in terms of sample efficiency and final performance.
Plain English Explanation
In the world of reinforcement learning (RL), where agents learn to make decisions by interacting with their environment and receiving rewards, there are two critical elements that can greatly impact the agents' performance: hyperparameters and reward functions.
Hyperparameters are the settings or variables that are not learned by the agent during training but are instead set by the researcher or developer. These include things like the learning rate, the number of hidden layers in the neural network, and the discount factor for future rewards. Choosing the right hyperparameters can be a time-consuming and challenging task, as they can have a significant impact on the agent's ability to learn and perform well.
Reward functions, on the other hand, define the objective that the agent is trying to optimize. In other words, they determine what the agent should be trying to achieve. Designing a good reward function can be just as important as tuning the hyperparameters, as it can shape the agent's behavior and influence the skills it develops.
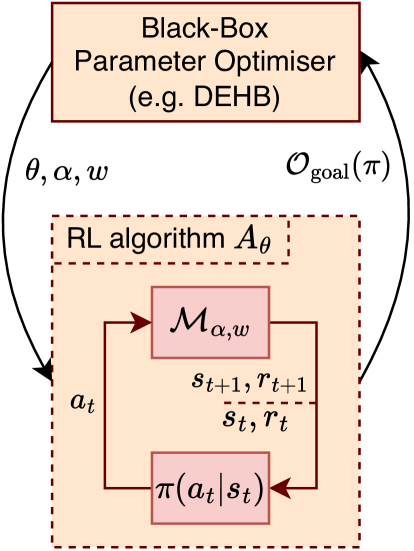
The key innovation in this paper is the idea of combining automated optimization of hyperparameters and reward shaping in a single, integrated framework. The authors argue that by optimizing these two elements together, rather than treating them as separate concerns, they can create RL agents that are more efficient and effective at learning and performing tasks.
Reward shaping is the process of modifying the reward function to provide the agent with more informative or useful feedback during training. This can help the agent learn more quickly and avoid getting stuck in local optima.
By automating the optimization of both hyperparameters and reward functions, the authors believe they can create RL agents that are more robust and adaptable, capable of performing well across a wide range of tasks and environments.
Technical Explanation
The authors propose a hybrid reinforcement learning framework that combines automated optimization of hyperparameters and reward shaping. Their approach involves the following key elements:
- Hyperparameter Optimization: The authors use a Bayesian optimization technique to efficiently explore the hyperparameter space and find the optimal settings for a given RL task.
- Reward Shaping: The authors incorporate a reward shaping mechanism that dynamically adjusts the reward function during training, based on the agent's performance and exploration of the environment.
- Integrated Optimization: The hyperparameter optimization and reward shaping components are tightly coupled, with each informing and updating the other in an iterative process.
The authors evaluate their approach on a range of RL tasks, including continuous control problems and discrete decision-making problems. They compare their hybrid framework to traditional RL methods, as well as to approaches that optimize either hyperparameters or reward functions in isolation.
The results show that the hybrid framework can outperform these alternative methods in terms of sample efficiency and final performance. The authors attribute this to the synergistic effects of optimizing hyperparameters and reward functions together, allowing the agent to learn more effectively and generalize better to new situations.
Critical Analysis
The paper presents a promising approach to improving the performance and generalization of RL agents, but it also raises some important questions and potential concerns:
-
Computational Complexity: The authors' hybrid framework involves a relatively complex optimization process, which could lead to increased computational requirements and training times. It's important to carefully consider the trade-offs between the potential performance gains and the computational resources required.
-
Generalizability: While the authors demonstrate the effectiveness of their approach on several RL tasks, it's unclear how well it would scale or generalize to more complex, real-world problems. Further research and evaluation on a wider range of tasks would be needed to assess the broader applicability of the framework.
-
Interpretability: The integration of hyperparameter optimization and reward shaping can make the overall system more opaque and difficult to interpret. This could be a concern, particularly in domains where transparency and explainability are important, such as in safety-critical applications.
-
Practical Considerations: The authors do not extensively discuss the practical challenges of implementing their framework, such as the need for suitable exploration strategies, the impact of stochasticity in the environment, or the potential need for domain-specific adaptations.
Overall, the paper presents an innovative and promising approach to improving RL agent performance, but further research and investigation would be needed to fully understand its limitations and potential real-world implications.
Conclusion
This paper introduces a novel hybrid reinforcement learning framework that combines automated optimization of hyperparameters and reward shaping. By integrating these two critical elements, the authors demonstrate that RL agents can achieve superior performance and generalization across a range of tasks.
The key insights from this research could have far-reaching implications for the development of more capable and adaptable RL systems, with potential applications in areas such as robotics, game AI, and decision-making systems. However, the authors also highlight the need for further investigation into the practical challenges and potential limitations of their approach.
As the field of reinforcement learning continues to evolve, the integration of advanced optimization techniques and reward engineering is likely to be an important area of focus. This paper provides a valuable contribution to this ongoing research, offering a new perspective on how to design more effective and efficient RL agents.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Combining Automated Optimisation of Hyperparameters and Reward Shape
Julian Dierkes, Emma Cramer, Holger H. Hoos, Sebastian Trimpe
There has been significant progress in deep reinforcement learning (RL) in recent years. Nevertheless, finding suitable hyperparameter configurations and reward functions remains challenging even for experts, and performance heavily relies on these design choices. Also, most RL research is conducted on known benchmarks where knowledge about these choices already exists. However, novel practical applications often pose complex tasks for which no prior knowledge about good hyperparameters and reward functions is available, thus necessitating their derivation from scratch. Prior work has examined automatically tuning either hyperparameters or reward functions individually. We demonstrate empirically that an RL algorithm's hyperparameter configurations and reward function are often mutually dependent, meaning neither can be fully optimised without appropriate values for the other. We then propose a methodology for the combined optimisation of hyperparameters and the reward function. Furthermore, we include a variance penalty as an optimisation objective to improve the stability of learned policies. We conducted extensive experiments using Proximal Policy Optimisation and Soft Actor-Critic on four environments. Our results show that combined optimisation significantly improves over baseline performance in half of the environments and achieves competitive performance in the others, with only a minor increase in computational costs. This suggests that combined optimisation should be best practice.
Read more6/27/2024

0
Hyperparameter Optimization for Driving Strategies Based on Reinforcement Learning
Nihal Acharya Adde, Hanno Gottschalk, Andreas Ebert
This paper focuses on hyperparameter optimization for autonomous driving strategies based on Reinforcement Learning. We provide a detailed description of training the RL agent in a simulation environment. Subsequently, we employ Efficient Global Optimization algorithm that uses Gaussian Process fitting for hyperparameter optimization in RL. Before this optimization phase, Gaussian process interpolation is applied to fit the surrogate model, for which the hyperparameter set is generated using Latin hypercube sampling. To accelerate the evaluation, parallelization techniques are employed. Following the hyperparameter optimization procedure, a set of hyperparameters is identified, resulting in a noteworthy enhancement in overall driving performance. There is a substantial increase of 4% when compared to existing manually tuned parameters and the hyperparameters discovered during the initialization process using Latin hypercube sampling. After the optimization, we analyze the obtained results thoroughly and conduct a sensitivity analysis to assess the robustness and generalization capabilities of the learned autonomous driving strategies. The findings from this study contribute to the advancement of Gaussian process based Bayesian optimization to optimize the hyperparameters for autonomous driving in RL, providing valuable insights for the development of efficient and reliable autonomous driving systems.
Read more7/22/2024

0
Generating and Evolving Reward Functions for Highway Driving with Large Language Models
Xu Han, Qiannan Yang, Xianda Chen, Xiaowen Chu, Meixin Zhu
Reinforcement Learning (RL) plays a crucial role in advancing autonomous driving technologies by maximizing reward functions to achieve the optimal policy. However, crafting these reward functions has been a complex, manual process in many practices. To reduce this complexity, we introduce a novel framework that integrates Large Language Models (LLMs) with RL to improve reward function design in autonomous driving. This framework utilizes the coding capabilities of LLMs, proven in other areas, to generate and evolve reward functions for highway scenarios. The framework starts with instructing LLMs to create an initial reward function code based on the driving environment and task descriptions. This code is then refined through iterative cycles involving RL training and LLMs' reflection, which benefits from their ability to review and improve the output. We have also developed a specific prompt template to improve LLMs' understanding of complex driving simulations, ensuring the generation of effective and error-free code. Our experiments in a highway driving simulator across three traffic configurations show that our method surpasses expert handcrafted reward functions, achieving a 22% higher average success rate. This not only indicates safer driving but also suggests significant gains in development productivity.
Read more6/18/2024

0
Hybrid Reinforcement Learning Framework for Mixed-Variable Problems
Haoyan Zhai, Qianli Hu, Jiangning Chen
Optimization problems characterized by both discrete and continuous variables are common across various disciplines, presenting unique challenges due to their complex solution landscapes and the difficulty of navigating mixed-variable spaces effectively. To Address these challenges, we introduce a hybrid Reinforcement Learning (RL) framework that synergizes RL for discrete variable selection with Bayesian Optimization for continuous variable adjustment. This framework stands out by its strategic integration of RL and continuous optimization techniques, enabling it to dynamically adapt to the problem's mixed-variable nature. By employing RL for exploring discrete decision spaces and Bayesian Optimization to refine continuous parameters, our approach not only demonstrates flexibility but also enhances optimization performance. Our experiments on synthetic functions and real-world machine learning hyperparameter tuning tasks reveal that our method consistently outperforms traditional RL, random search, and standalone Bayesian optimization in terms of effectiveness and efficiency.
Read more6/3/2024