Comparative Analysis of Modality Fusion Approaches for Audio-Visual Person Identification and Verification

0

Sign in to get full access
Overview
- This paper presents a comparative analysis of different approaches for fusing audio and visual modalities for the tasks of person identification and verification.
- The researchers evaluate the performance of several modality fusion techniques, including early fusion, late fusion, and recursive fusion.
- The study is conducted on two popular audio-visual datasets, and the results provide insights into the strengths and weaknesses of each fusion method.
Plain English Explanation
The paper explores different ways of combining audio and visual information to identify and verify individuals. Imagine you're trying to recognize someone based on their face and voice. The researchers tested various techniques for merging these two sources of data, such as:
- Early fusion: Combining the audio and visual data right at the beginning, before any processing.
- Late fusion: Processing the audio and visual data separately, then combining the results.
- Recursive fusion: Repeatedly refining the combination of audio and visual information.
The team evaluated these fusion approaches on two standard audio-visual datasets to see which ones work best for identifying and verifying people. The findings provide insights into the strengths and limitations of each fusion method, which can help guide future research in this area.
Technical Explanation
The paper explores several modality fusion techniques for audio-visual person identification and verification:
- Early fusion: The audio and visual features are concatenated at the input level, and a single network is trained to learn the joint representation.
- Late fusion: The audio and visual features are processed separately, and their outputs are combined at the decision level using techniques like weighted averaging or learnable fusion.
- Recursive fusion: The audio and visual features are fused recursively, with the fused representation being refined in an iterative manner.
The researchers evaluate these approaches on two publicly available audio-visual datasets: RAVDESS and VoxCeleb2. They report identification and verification performance metrics, such as accuracy, equal error rate, and F1-score, to compare the effectiveness of the different fusion methods.
Critical Analysis
The paper provides a comprehensive evaluation of several modality fusion techniques for audio-visual person identification and verification. However, the researchers acknowledge some limitations of their study:
- The experiments are conducted on relatively constrained datasets, and the performance may vary on more diverse or challenging real-world scenarios.
- The paper does not explore the impact of different audio and visual feature extraction techniques on the fusion performance.
- The analysis does not delve into the computational complexity and resource requirements of the various fusion approaches, which could be an important consideration for practical applications.
Additionally, the study could be further strengthened by:
- Investigating the robustness of the fusion techniques to noisy or partial input data (e.g., occluded faces or noisy audio).
- Exploring the potential of more advanced fusion methods, such as attention-based or cross-modal approaches.
- Analyzing the interpretability and explainability of the fusion models to better understand the decision-making process.
Conclusion
This paper provides a comparative analysis of different modality fusion approaches for audio-visual person identification and verification. The researchers evaluate the performance of early fusion, late fusion, and recursive fusion techniques on two popular datasets, offering insights into the strengths and weaknesses of each method.
The findings from this study can inform the development of more robust and effective audio-visual biometric systems, which have applications in areas such as security, surveillance, and human-computer interaction. The researchers' acknowledgment of the limitations and potential future directions suggests that this is an active and evolving field of research, with room for further advancements and practical deployments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Comparative Analysis of Modality Fusion Approaches for Audio-Visual Person Identification and Verification
Aref Farhadipour, Masoumeh Chapariniya, Teodora Vukovic, Volker Dellwo
Multimodal learning involves integrating information from various modalities to enhance learning and comprehension. We compare three modality fusion strategies in person identification and verification by processing two modalities: voice and face. In this paper, a one-dimensional convolutional neural network is employed for x-vector extraction from voice, while the pre-trained VGGFace2 network and transfer learning are utilized for face modality. In addition, gammatonegram is used as speech representation in engagement with the Darknet19 pre-trained network. The proposed systems are evaluated using the K-fold cross-validation technique on the 118 speakers of the test set of the VoxCeleb2 dataset. The comparative evaluations are done for single-modality and three proposed multimodal strategies in equal situations. Results demonstrate that the feature fusion strategy of gammatonegram and facial features achieves the highest performance, with an accuracy of 98.37% in the person identification task. However, concatenating facial features with the x-vector reaches 0.62% for EER in verification tasks.
Read more9/4/2024

0
Audio-Visual Person Verification based on Recursive Fusion of Joint Cross-Attention
R. Gnana Praveen, Jahangir Alam
Person or identity verification has been recently gaining a lot of attention using audio-visual fusion as faces and voices share close associations with each other. Conventional approaches based on audio-visual fusion rely on score-level or early feature-level fusion techniques. Though existing approaches showed improvement over unimodal systems, the potential of audio-visual fusion for person verification is not fully exploited. In this paper, we have investigated the prospect of effectively capturing both the intra- and inter-modal relationships across audio and visual modalities, which can play a crucial role in significantly improving the fusion performance over unimodal systems. In particular, we introduce a recursive fusion of a joint cross-attentional model, where a joint audio-visual feature representation is employed in the cross-attention framework in a recursive fashion to progressively refine the feature representations that can efficiently capture the intra-and inter-modal relationships. To further enhance the audio-visual feature representations, we have also explored BLSTMs to improve the temporal modeling of audio-visual feature representations. Extensive experiments are conducted on the Voxceleb1 dataset to evaluate the proposed model. Results indicate that the proposed model shows promising improvement in fusion performance by adeptly capturing the intra-and inter-modal relationships across audio and visual modalities.
Read more4/29/2024
👁️
0
Cross Attentional Audio-Visual Fusion for Dimensional Emotion Recognition
R. Gnana Praveen, Eric Granger, Patrick Cardinal
Multimodal analysis has recently drawn much interest in affective computing, since it can improve the overall accuracy of emotion recognition over isolated uni-modal approaches. The most effective techniques for multimodal emotion recognition efficiently leverage diverse and complimentary sources of information, such as facial, vocal, and physiological modalities, to provide comprehensive feature representations. In this paper, we focus on dimensional emotion recognition based on the fusion of facial and vocal modalities extracted from videos, where complex spatiotemporal relationships may be captured. Most of the existing fusion techniques rely on recurrent networks or conventional attention mechanisms that do not effectively leverage the complimentary nature of audio-visual (A-V) modalities. We introduce a cross-attentional fusion approach to extract the salient features across A-V modalities, allowing for accurate prediction of continuous values of valence and arousal. Our new cross-attentional A-V fusion model efficiently leverages the inter-modal relationships. In particular, it computes cross-attention weights to focus on the more contributive features across individual modalities, and thereby combine contributive feature representations, which are then fed to fully connected layers for the prediction of valence and arousal. The effectiveness of the proposed approach is validated experimentally on videos from the RECOLA and Fatigue (private) data-sets. Results indicate that our cross-attentional A-V fusion model is a cost-effective approach that outperforms state-of-the-art fusion approaches. Code is available: url{https://github.com/praveena2j/Cross-Attentional-AV-Fusion}
Read more7/9/2024
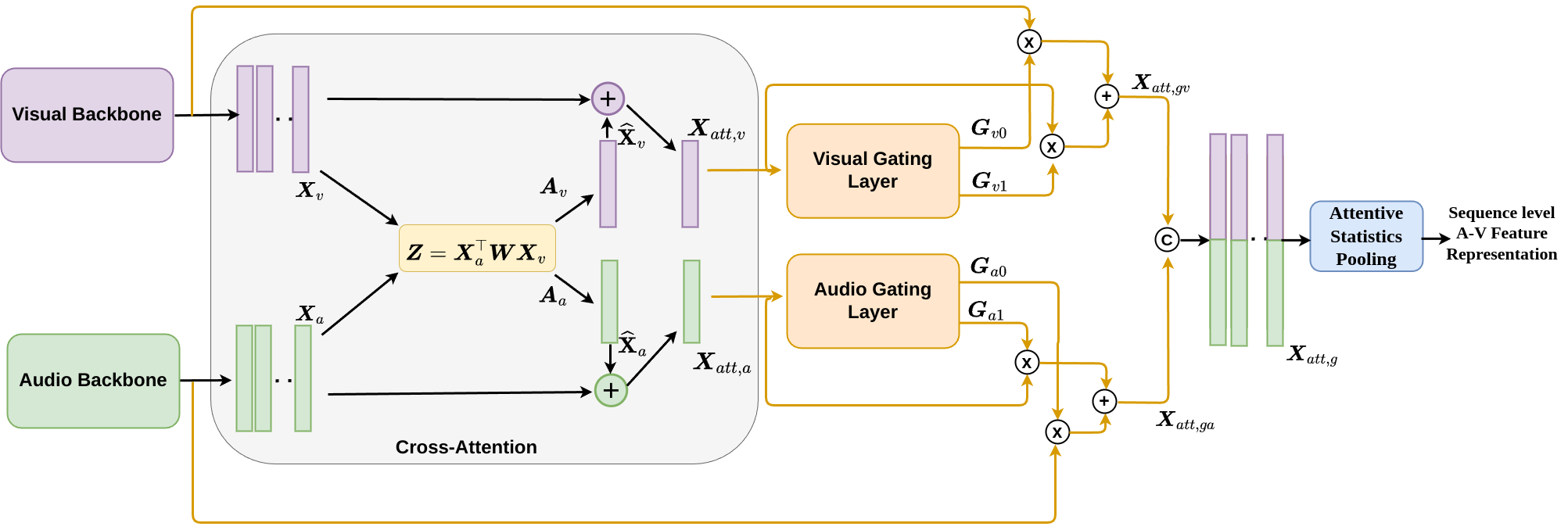
0
Dynamic Cross Attention for Audio-Visual Person Verification
R. Gnana Praveen, Jahangir Alam
Although person or identity verification has been predominantly explored using individual modalities such as face and voice, audio-visual fusion has recently shown immense potential to outperform unimodal approaches. Audio and visual modalities are often expected to pose strong complementary relationships, which plays a crucial role in effective audio-visual fusion. However, they may not always strongly complement each other, they may also exhibit weak complementary relationships, resulting in poor audio-visual feature representations. In this paper, we propose a Dynamic Cross-Attention (DCA) model that can dynamically select the cross-attended or unattended features on the fly based on the strong or weak complementary relationships, respectively, across audio and visual modalities. In particular, a conditional gating layer is designed to evaluate the contribution of the cross-attention mechanism and choose cross-attended features only when they exhibit strong complementary relationships, otherwise unattended features. Extensive experiments are conducted on the Voxceleb1 dataset to demonstrate the robustness of the proposed model. Results indicate that the proposed model consistently improves the performance on multiple variants of cross-attention while outperforming the state-of-the-art methods.
Read more4/23/2024