Comparing Two Model Designs for Clinical Note Generation; Is an LLM a Useful Evaluator of Consistency?

0

Sign in to get full access
Overview
- This paper compares two different model designs for generating clinical notes from medical data.
- It investigates whether a large language model (LLM) can be a useful tool for evaluating the consistency of the generated notes.
Plain English Explanation
This research paper looks at different ways to create clinical notes, which are detailed reports about a patient's medical condition and treatment, using artificial intelligence (AI) models. The researchers tested two different model designs to see which one could generate more consistent and reliable clinical notes.
They also explored whether a type of AI model called a large language model (LLM) could be used to evaluate the quality and consistency of the generated notes. LLMs are powerful AI systems that can understand and generate human-like text. The researchers wanted to see if an LLM could be a helpful tool for assessing the coherence and accuracy of the clinical notes produced by the other AI models.
Technical Explanation
The paper compares two model designs for generating clinical notes from structured medical data:
- Enhancing Clinical Efficiency through LLM Discharge Note - an approach that uses an LLM to generate the notes
- Continued Pretrained LLM Approach for Automatic Medical Note - a method that fine-tunes a pre-trained LLM on medical data to generate the notes
The researchers evaluate the consistency of the notes produced by these two models using both human raters and an LLM-based evaluation system. The LLM-based system assesses the coherence, factual accuracy, and overall quality of the generated notes.
Critical Analysis
The paper acknowledges some limitations of the research, such as the relatively small size of the dataset used for training and evaluating the models. The authors also note that further work is needed to better understand the strengths and weaknesses of using LLMs as evaluators of clinical note consistency.
While the results suggest that LLMs can be a useful tool for assessing note quality, the researchers caution that LLMs may not always be reliable, especially when evaluating subtle aspects of medical documentation. Additional research is needed to further explore the potential and limitations of this approach.
Conclusion
This paper presents a comparative study of two model designs for generating clinical notes from medical data. It also investigates the use of a large language model (LLM) as a tool for evaluating the consistency and quality of the generated notes.
The findings indicate that LLMs can be a helpful mechanism for assessing the coherence and accuracy of clinical notes, but more research is needed to fully understand their capabilities and limitations in this domain. The paper provides valuable insights for researchers and practitioners working on developing AI systems for healthcare documentation and record-keeping.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Comparing Two Model Designs for Clinical Note Generation; Is an LLM a Useful Evaluator of Consistency?
Nathan Brake, Thomas Schaaf
Following an interaction with a patient, physicians are responsible for the submission of clinical documentation, often organized as a SOAP note. A clinical note is not simply a summary of the conversation but requires the use of appropriate medical terminology. The relevant information can then be extracted and organized according to the structure of the SOAP note. In this paper we analyze two different approaches to generate the different sections of a SOAP note based on the audio recording of the conversation, and specifically examine them in terms of note consistency. The first approach generates the sections independently, while the second method generates them all together. In this work we make use of PEGASUS-X Transformer models and observe that both methods lead to similar ROUGE values (less than 1% difference) and have no difference in terms of the Factuality metric. We perform a human evaluation to measure aspects of consistency and demonstrate that LLMs like Llama2 can be used to perform the same tasks with roughly the same agreement as the human annotators. Between the Llama2 analysis and the human reviewers we observe a Cohen Kappa inter-rater reliability of 0.79, 1.00, and 0.32 for consistency of age, gender, and body part injury, respectively. With this we demonstrate the usefulness of leveraging an LLM to measure quality indicators that can be identified by humans but are not currently captured by automatic metrics. This allows scaling evaluation to larger data sets, and we find that clinical note consistency improves by generating each new section conditioned on the output of all previously generated sections.
Read more4/10/2024

0
Improving Clinical Note Generation from Complex Doctor-Patient Conversation
Yizhan Li, Sifan Wu, Christopher Smith, Thomas Lo, Bang Liu
Writing clinical notes and documenting medical exams is a critical task for healthcare professionals, serving as a vital component of patient care documentation. However, manually writing these notes is time-consuming and can impact the amount of time clinicians can spend on direct patient interaction and other tasks. Consequently, the development of automated clinical note generation systems has emerged as a clinically meaningful area of research within AI for health. In this paper, we present three key contributions to the field of clinical note generation using large language models (LLMs). First, we introduce CliniKnote, a comprehensive dataset consisting of 1,200 complex doctor-patient conversations paired with their full clinical notes. This dataset, created and curated by medical experts with the help of modern neural networks, provides a valuable resource for training and evaluating models in clinical note generation tasks. Second, we propose the K-SOAP (Keyword, Subjective, Objective, Assessment, and Plan) note format, which enhances traditional SOAP~cite{podder2023soap} (Subjective, Objective, Assessment, and Plan) notes by adding a keyword section at the top, allowing for quick identification of essential information. Third, we develop an automatic pipeline to generate K-SOAP notes from doctor-patient conversations and benchmark various modern LLMs using various metrics. Our results demonstrate significant improvements in efficiency and performance compared to standard LLM finetuning methods.
Read more8/28/2024
0
Towards Adapting Open-Source Large Language Models for Expert-Level Clinical Note Generation
Hanyin Wang, Chufan Gao, Bolun Liu, Qiping Xu, Guleid Hussein, Mohamad El Labban, Kingsley Iheasirim, Hariprasad Korsapati, Chuck Outcalt, Jimeng Sun
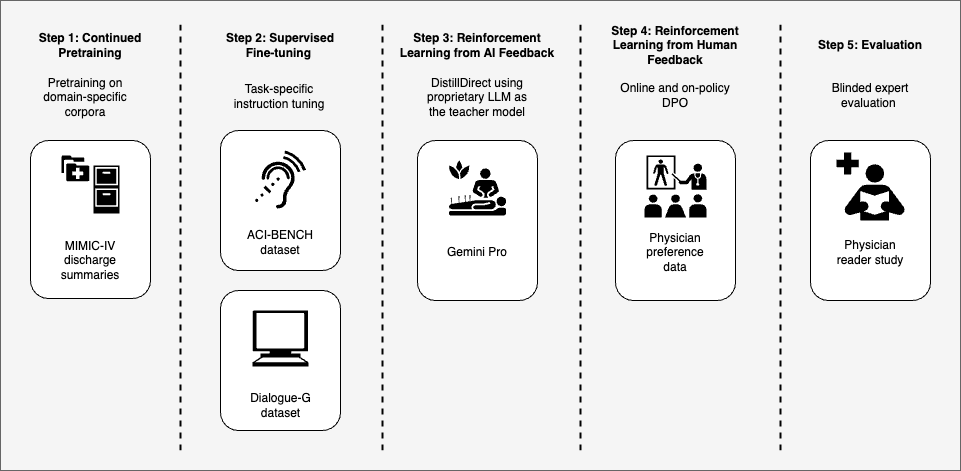
Proprietary Large Language Models (LLMs) such as GPT-4 and Gemini have demonstrated promising capabilities in clinical text summarization tasks. However, due to patient data privacy concerns and computational costs, many healthcare providers prefer using small, locally-hosted models over external generic LLMs. This study presents a comprehensive domain- and task-specific adaptation process for the open-source LLaMA-2 13 billion parameter model, enabling it to generate high-quality clinical notes from outpatient patient-doctor dialogues. Our process incorporates continued pre-training, supervised fine-tuning, and reinforcement learning from both AI and human feedback. We introduced a new approach, DistillDirect, for performing on-policy reinforcement learning with Gemini 1.0 Pro as the teacher model. Our resulting model, LLaMA-Clinic, can generate clinical notes comparable in quality to those authored by physicians. In a blinded physician reader study, the majority (90.4%) of individual evaluations rated the notes generated by LLaMA-Clinic as acceptable or higher across all three criteria: real-world readiness, completeness, and accuracy. In the more challenging Assessment and Plan section, LLaMA-Clinic scored higher (4.2/5) in real-world readiness than physician-authored notes (4.1/5). Our cost analysis for inference shows that our LLaMA-Clinic model achieves a 3.75-fold cost reduction compared to an external generic LLM service. Additionally, we highlight key considerations for future clinical note-generation tasks, emphasizing the importance of pre-defining a best-practice note format, rather than relying on LLMs to determine this for clinical practice. We have made our newly created synthetic clinic dialogue-note dataset and the physician feedback dataset publicly available to foster future research.
Read more6/11/2024

0
EHRNoteQA: An LLM Benchmark for Real-World Clinical Practice Using Discharge Summaries
Sunjun Kweon, Jiyoun Kim, Heeyoung Kwak, Dongchul Cha, Hangyul Yoon, Kwanghyun Kim, Jeewon Yang, Seunghyun Won, Edward Choi
Discharge summaries in Electronic Health Records (EHRs) are crucial for clinical decision-making, but their length and complexity make information extraction challenging, especially when dealing with accumulated summaries across multiple patient admissions. Large Language Models (LLMs) show promise in addressing this challenge by efficiently analyzing vast and complex data. Existing benchmarks, however, fall short in properly evaluating LLMs' capabilities in this context, as they typically focus on single-note information or limited topics, failing to reflect the real-world inquiries required by clinicians. To bridge this gap, we introduce EHRNoteQA, a novel benchmark built on the MIMIC-IV EHR, comprising 962 different QA pairs each linked to distinct patients' discharge summaries. Every QA pair is initially generated using GPT-4 and then manually reviewed and refined by three clinicians to ensure clinical relevance. EHRNoteQA includes questions that require information across multiple discharge summaries and covers eight diverse topics, mirroring the complexity and diversity of real clinical inquiries. We offer EHRNoteQA in two formats: open-ended and multi-choice question answering, and propose a reliable evaluation method for each. We evaluate 27 LLMs using EHRNoteQA and examine various factors affecting the model performance (e.g., the length and number of discharge summaries). Furthermore, to validate EHRNoteQA as a reliable proxy for expert evaluations in clinical practice, we measure the correlation between the LLM performance on EHRNoteQA, and the LLM performance manually evaluated by clinicians. Results show that LLM performance on EHRNoteQA have higher correlation with clinician-evaluated performance (Spearman: 0.78, Kendall: 0.62) compared to other benchmarks, demonstrating its practical relevance in evaluating LLMs in clinical settings.
Read more6/28/2024