Compositional Factorization of Visual Scenes with Convolutional Sparse Coding and Resonator Networks

0

Sign in to get full access
Overview
- This paper introduces a new approach for compositional factorization of visual scenes using convolutional sparse coding and resonator networks.
- The researchers develop a model that can decompose complex visual scenes into their constituent elements, representing them as sparse, high-dimensional vectors.
- This allows for efficient storage and processing of visual information, as well as the ability to perform combinatorial search and computing-in-superposition.
Plain English Explanation
The paper presents a novel way to understand and represent visual scenes using a combination of sparse coding and resonator networks. Sparse coding is a technique that can break down complex images into simpler, more fundamental components. The researchers leverage this to create a model that can decompose a visual scene into its underlying elements, representing each one as a compact, high-dimensional vector.
This vector representation allows for efficient storage and processing of the visual information. It also enables the model to perform what the authors call "combinatorial search" and "computing-in-superposition" - essentially, the ability to rapidly explore and combine the different elements of a scene in creative ways. [This relates to the concepts of hyperdimensional computing and vector symbolic architectures.]
The key insight is that by representing visual scenes in this sparse, high-dimensional format, the model can capture the compositional structure of the world in a way that mirrors how our own brains process visual information. This could have important implications for real-time 3D semantic occupancy prediction, low-light image enhancement, and other visual understanding tasks.
Technical Explanation
The paper introduces a novel approach for compositional factorization of visual scenes using convolutional sparse coding and resonator networks. The core idea is to represent visual scenes as sparse, high-dimensional vectors that capture the underlying compositional structure.
The model first uses convolutional sparse coding to decompose input images into a set of sparse, localized feature representations. These sparse feature vectors are then fed into a resonator network, which learns to combine them into higher-level, compositional representations.
The key advantage of this approach is that it allows for efficient storage and processing of visual information. The sparse, high-dimensional vector representations enable the model to perform "combinatorial search" - rapidly exploring different combinations of the scene elements. This also enables "computing-in-superposition", where the model can perform computations directly on the vector representations without the need for explicit decompression or decoding.
The researchers evaluate their approach on a range of visual understanding tasks, including saliency prediction and scene reconstruction. They demonstrate that their model outperforms baseline approaches, particularly in its ability to capture the compositional structure of visual scenes.
Critical Analysis
The paper presents a promising approach for compositional factorization of visual scenes, but it is important to note some potential limitations and areas for further research.
One key concern is the scalability of the model, particularly as the complexity of the visual scenes increases. The authors acknowledge that the resonator network may struggle to learn effective representations for highly cluttered or busy scenes. Exploring ways to hierarchically compose the sparse feature vectors could be a promising direction to address this.
Additionally, the paper does not provide a detailed analysis of the types of visual features that the model learns to represent. Understanding the semantic and functional meaning of the sparse feature vectors would be valuable for interpreting the model's inner workings and potentially improving its performance.
Finally, the authors do not extensively discuss the computational and memory efficiency of their approach compared to other visual understanding models. Benchmarking the model's performance along these axes would help better situate it within the broader landscape of computer vision techniques.
Overall, the paper presents an intriguing new direction for compositional scene understanding, but further research is needed to fully assess its capabilities and limitations.
Conclusion
This paper introduces a novel approach for compositional factorization of visual scenes using convolutional sparse coding and resonator networks. By representing visual information as sparse, high-dimensional vectors, the model is able to capture the underlying structure of scenes in an efficient and flexible way.
The key innovations of this work include the ability to perform combinatorial search and computing-in-superposition on the vector representations, which enables new forms of visual reasoning and processing. While the paper demonstrates promising results, there are also important challenges around scalability and interpretability that warrant further investigation.
Nonetheless, this research represents an exciting step forward in our understanding of how to build more sophisticated and flexible models for visual scene understanding. As the field of computer vision continues to evolve, approaches like the one presented in this paper could play an important role in developing systems that can better comprehend and reason about the complex, compositional nature of the visual world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Compositional Factorization of Visual Scenes with Convolutional Sparse Coding and Resonator Networks
Christopher J. Kymn, Sonia Mazelet, Annabel Ng, Denis Kleyko, Bruno A. Olshausen
We propose a system for visual scene analysis and recognition based on encoding the sparse, latent feature-representation of an image into a high-dimensional vector that is subsequently factorized to parse scene content. The sparse feature representation is learned from image statistics via convolutional sparse coding, while scene parsing is performed by a resonator network. The integration of sparse coding with the resonator network increases the capacity of distributed representations and reduces collisions in the combinatorial search space during factorization. We find that for this problem the resonator network is capable of fast and accurate vector factorization, and we develop a confidence-based metric that assists in tracking the convergence of the resonator network.
Read more5/1/2024
🤔
0
Neuromorphic Visual Scene Understanding with Resonator Networks
Alpha Renner, Lazar Supic, Andreea Danielescu, Giacomo Indiveri, Bruno A. Olshausen, Yulia Sandamirskaya, Friedrich T. Sommer, E. Paxon Frady
Analyzing a visual scene by inferring the configuration of a generative model is widely considered the most flexible and generalizable approach to scene understanding. Yet, one major problem is the computational challenge of the inference procedure, involving a combinatorial search across object identities and poses. Here we propose a neuromorphic solution exploiting three key concepts: (1) a computational framework based on Vector Symbolic Architectures (VSA) with complex-valued vectors; (2) the design of Hierarchical Resonator Networks (HRN) to factorize the non-commutative transforms translation and rotation in visual scenes; (3) the design of a multi-compartment spiking phasor neuron model for implementing complex-valued resonator networks on neuromorphic hardware. The VSA framework uses vector binding operations to form a generative image model in which binding acts as the equivariant operation for geometric transformations. A scene can, therefore, be described as a sum of vector products, which can then be efficiently factorized by a resonator network to infer objects and their poses. The HRN features a partitioned architecture in which vector binding is equivariant for horizontal and vertical translation within one partition and for rotation and scaling within the other partition. The spiking neuron model allows mapping the resonator network onto efficient and low-power neuromorphic hardware. Our approach is demonstrated on synthetic scenes composed of simple 2D shapes undergoing rigid geometric transformations and color changes. A companion paper demonstrates the same approach in real-world application scenarios for machine vision and robotics.
Read more6/27/2024
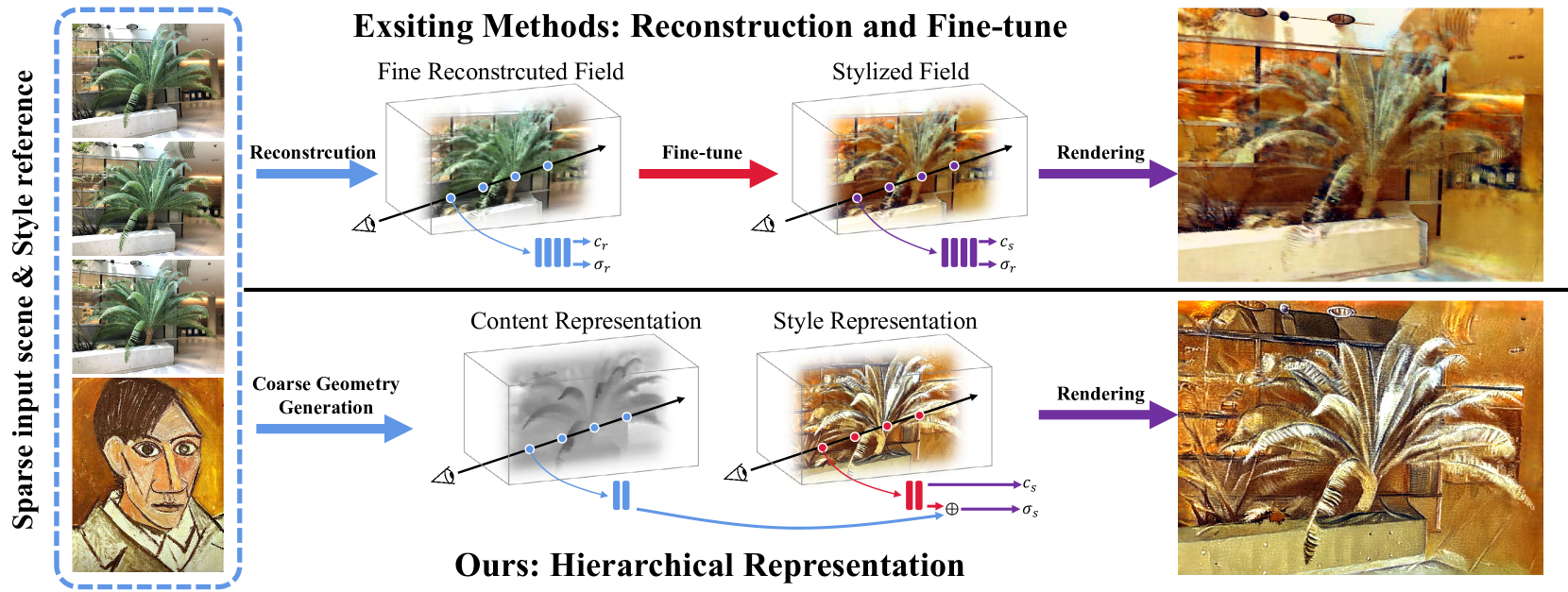
0
Stylizing Sparse-View 3D Scenes with Hierarchical Neural Representation
Y. Wang, A. Gao, Y. Gong, Y. Zeng
Recently, a surge of 3D style transfer methods has been proposed that leverage the scene reconstruction power of a pre-trained neural radiance field (NeRF). To successfully stylize a scene this way, one must first reconstruct a photo-realistic radiance field from collected images of the scene. However, when only sparse input views are available, pre-trained few-shot NeRFs often suffer from high-frequency artifacts, which are generated as a by-product of high-frequency details for improving reconstruction quality. Is it possible to generate more faithful stylized scenes from sparse inputs by directly optimizing encoding-based scene representation with target style? In this paper, we consider the stylization of sparse-view scenes in terms of disentangling content semantics and style textures. We propose a coarse-to-fine sparse-view scene stylization framework, where a novel hierarchical encoding-based neural representation is designed to generate high-quality stylized scenes directly from implicit scene representations. We also propose a new optimization strategy with content strength annealing to achieve realistic stylization and better content preservation. Extensive experiments demonstrate that our method can achieve high-quality stylization of sparse-view scenes and outperforms fine-tuning-based baselines in terms of stylization quality and efficiency.
Read more4/9/2024
🧠
0
Representing Animatable Avatar via Factorized Neural Fields
Chunjin Song, Zhijie Wu, Bastian Wandt, Leonid Sigal, Helge Rhodin
For reconstructing high-fidelity human 3D models from monocular videos, it is crucial to maintain consistent large-scale body shapes along with finely matched subtle wrinkles. This paper explores the observation that the per-frame rendering results can be factorized into a pose-independent component and a corresponding pose-dependent equivalent to facilitate frame consistency. Pose adaptive textures can be further improved by restricting frequency bands of these two components. In detail, pose-independent outputs are expected to be low-frequency, while highfrequency information is linked to pose-dependent factors. We achieve a coherent preservation of both coarse body contours across the entire input video and finegrained texture features that are time variant with a dual-branch network with distinct frequency components. The first branch takes coordinates in canonical space as input, while the second branch additionally considers features outputted by the first branch and pose information of each frame. Our network integrates the information predicted by both branches and utilizes volume rendering to generate photo-realistic 3D human images. Through experiments, we demonstrate that our network surpasses the neural radiance fields (NeRF) based state-of-the-art methods in preserving high-frequency details and ensuring consistent body contours.
Read more6/4/2024