Compressible Dynamics in Deep Overparameterized Low-Rank Learning & Adaptation

0

Sign in to get full access
Overview
- This paper explores the compressible dynamics of deep overparameterized low-rank learning and adaptation in large language models.
- The authors investigate the compression properties of low-rank parameter updates, which can enable more efficient fine-tuning and adaptation of large models.
- The research builds on previous work on techniques like feature-based low-rank compression, NOLA: Compressing LoRA using Linear Combination of Random Matrices, LoRA-XS: Low-Rank Adaptation of Extremely Small, oLoRA: Orthonormal Low-Rank Adaptation for Large Language Models, and MoRA: High-Rank Updating for Parameter-Efficient Fine-Tuning.
Plain English Explanation
This research paper explores ways to make it more efficient to fine-tune and adapt large AI language models. The key idea is to focus on compressing or reducing the number of parameters that need to be updated during the fine-tuning process.
The researchers investigate a technique called "low-rank learning and adaptation." This means that instead of updating all the parameters in the model, they only update a small subset of the parameters in a structured way. This allows the model to be adapted to new tasks or datasets without having to completely retrain the entire model from scratch.
The paper looks at the properties of these low-rank updates and how they can enable more efficient fine-tuning and adaptation of large language models. The authors build on previous research in this area, exploring different ways to compress and structure the low-rank updates to make the process even more efficient.
The goal is to make it easier and cheaper to adapt these large, powerful language models to new applications and use cases, without having to go through the full, time-consuming process of retraining the entire model. By focusing on low-rank, compressed updates, the researchers aim to unlock more flexible and practical ways to leverage the capabilities of these advanced language models.
Technical Explanation
The paper investigates the compression properties of low-rank parameter updates in the context of deep overparameterized learning and adaptation. The authors build on prior work on techniques like feature-based low-rank compression, NOLA: Compressing LoRA using Linear Combination of Random Matrices, LoRA-XS: Low-Rank Adaptation of Extremely Small, oLoRA: Orthonormal Low-Rank Adaptation for Large Language Models, and MoRA: High-Rank Updating for Parameter-Efficient Fine-Tuning.
The key idea is to leverage the overparameterization of deep neural networks to enable efficient fine-tuning and adaptation. Rather than updating all the model parameters, the researchers focus on updating only a small subset of the parameters in a low-rank, structured manner. This allows the model to be adapted to new tasks or datasets without having to completely retrain from scratch.
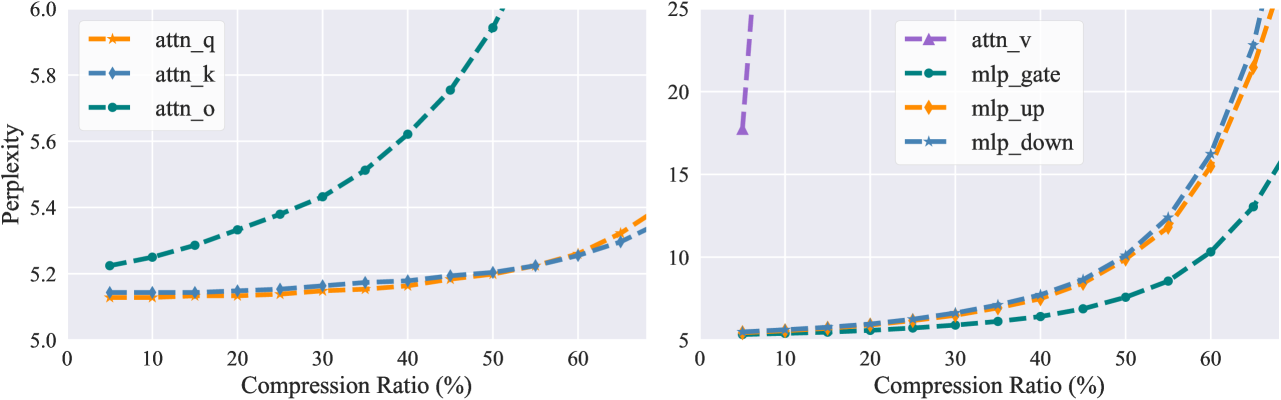
The paper analyzes the compressible dynamics of these low-rank updates, exploring how they can enable more efficient fine-tuning and adaptation. The authors investigate factors like the effective dimensionality of the updates, the stability and convergence properties, and the ability to compress the updates while preserving performance.
Through theoretical analysis and empirical evaluation, the researchers demonstrate the potential of low-rank learning and adaptation techniques to significantly reduce the computational and memory requirements of model fine-tuning, while maintaining strong performance. This has important implications for making large language models more accessible and practical for a wider range of applications.
Critical Analysis
The paper provides a robust theoretical and empirical analysis of the compression properties of low-rank parameter updates in deep overparameterized learning. The authors build on a solid foundation of prior work in this area and make a compelling case for the potential of these techniques to enable more efficient fine-tuning and adaptation of large language models.
One potential limitation is the focus on the specific low-rank update schemes explored in the paper. While the authors demonstrate the effectiveness of these approaches, there may be other low-rank or structured update strategies that could further improve efficiency and performance. Exploring a broader range of compression techniques could be an area for future research.
Additionally, the paper does not extensively address the practical challenges of implementing these low-rank adaptation techniques in real-world scenarios. Issues like the impact on inference latency, the scalability to very large models, and the potential tradeoffs between compression and task-specific fine-tuning performance could be valuable to explore in more depth.
Overall, the research presented in this paper is a significant contribution to the field of efficient model adaptation and fine-tuning. By focusing on the compressible dynamics of low-rank learning, the authors have provided important insights that could help make large language models more accessible and practical for a wider range of applications.
Conclusion
This paper explores the compressible dynamics of deep overparameterized low-rank learning and adaptation, building on a body of previous research in this area. The authors investigate techniques for efficiently fine-tuning and adapting large language models by focusing on low-rank parameter updates, rather than updating all model parameters.
The key findings demonstrate the potential of these low-rank adaptation approaches to significantly reduce the computational and memory requirements of model fine-tuning, while maintaining strong performance. This has important implications for making large language models more accessible and practical for a wider range of applications.
While the paper provides a robust theoretical and empirical analysis, there may be opportunities to explore additional low-rank or structured update strategies, as well as address practical implementation challenges. Nonetheless, the insights presented in this research represent an important step forward in enabling more efficient and flexible adaptation of advanced language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Compressible Dynamics in Deep Overparameterized Low-Rank Learning & Adaptation
Can Yaras, Peng Wang, Laura Balzano, Qing Qu
While overparameterization in machine learning models offers great benefits in terms of optimization and generalization, it also leads to increased computational requirements as model sizes grow. In this work, we show that by leveraging the inherent low-dimensional structures of data and compressible dynamics within the model parameters, we can reap the benefits of overparameterization without the computational burdens. In practice, we demonstrate the effectiveness of this approach for deep low-rank matrix completion as well as fine-tuning language models. Our approach is grounded in theoretical findings for deep overparameterized low-rank matrix recovery, where we show that the learning dynamics of each weight matrix are confined to an invariant low-dimensional subspace. Consequently, we can construct and train compact, highly compressed factorizations possessing the same benefits as their overparameterized counterparts. In the context of deep matrix completion, our technique substantially improves training efficiency while retaining the advantages of overparameterization. For language model fine-tuning, we propose a method called Deep LoRA, which improves the existing low-rank adaptation (LoRA) technique, leading to reduced overfitting and a simplified hyperparameter setup, while maintaining comparable efficiency. We validate the effectiveness of Deep LoRA on natural language tasks, particularly when fine-tuning with limited data. Our code is available at https://github.com/cjyaras/deep-lora-transformers.
Read more6/11/2024
0
Feature-based Low-Rank Compression of Large Language Models via Bayesian Optimization
Yixin Ji, Yang Xiang, Juntao Li, Wei Chen, Zhongyi Liu, Kehai Chen, Min Zhang
In recent years, large language models (LLMs) have driven advances in natural language processing. Still, their growing scale has increased the computational burden, necessitating a balance between efficiency and performance. Low-rank compression, a promising technique, reduces non-essential parameters by decomposing weight matrices into products of two low-rank matrices. Yet, its application in LLMs has not been extensively studied. The key to low-rank compression lies in low-rank factorization and low-rank dimensions allocation. To address the challenges of low-rank compression in LLMs, we conduct empirical research on the low-rank characteristics of large models. We propose a low-rank compression method suitable for LLMs. This approach involves precise estimation of feature distributions through pooled covariance matrices and a Bayesian optimization strategy for allocating low-rank dimensions. Experiments on the LLaMA-2 models demonstrate that our method outperforms existing strong structured pruning and low-rank compression techniques in maintaining model performance at the same compression ratio.
Read more5/20/2024
👀
0
NOLA: Compressing LoRA using Linear Combination of Random Basis
Soroush Abbasi Koohpayegani, KL Navaneet, Parsa Nooralinejad, Soheil Kolouri, Hamed Pirsiavash
Fine-tuning Large Language Models (LLMs) and storing them for each downstream task or domain is impractical because of the massive model size (e.g., 350GB in GPT-3). Current literature, such as LoRA, showcases the potential of low-rank modifications to the original weights of an LLM, enabling efficient adaptation and storage for task-specific models. These methods can reduce the number of parameters needed to fine-tune an LLM by several orders of magnitude. Yet, these methods face two primary limitations: (1) the parameter count is lower-bounded by the rank one decomposition, and (2) the extent of reduction is heavily influenced by both the model architecture and the chosen rank. We introduce NOLA, which overcomes the rank one lower bound present in LoRA. It achieves this by re-parameterizing the low-rank matrices in LoRA using linear combinations of randomly generated matrices (basis) and optimizing the linear mixture coefficients only. This approach allows us to decouple the number of trainable parameters from both the choice of rank and the network architecture. We present adaptation results using GPT-2, LLaMA-2, and ViT in natural language and computer vision tasks. NOLA performs as well as LoRA models with much fewer number of parameters compared to LoRA with rank one, the best compression LoRA can archive. Particularly, on LLaMA-2 70B, our method is almost 20 times more compact than the most compressed LoRA without degradation in accuracy. Our code is available here: https://github.com/UCDvision/NOLA
Read more5/1/2024

0
PC-LoRA: Low-Rank Adaptation for Progressive Model Compression with Knowledge Distillation
Injoon Hwang, Haewon Park, Youngwan Lee, Jooyoung Yang, SunJae Maeng
Low-rank adaption (LoRA) is a prominent method that adds a small number of learnable parameters to the frozen pre-trained weights for parameter-efficient fine-tuning. Prompted by the question, ``Can we make its representation enough with LoRA weights solely at the final phase of finetuning without the pre-trained weights?'' In this work, we introduce Progressive Compression LoRA~(PC-LoRA), which utilizes low-rank adaptation (LoRA) to simultaneously perform model compression and fine-tuning. The PC-LoRA method gradually removes the pre-trained weights during the training process, eventually leaving only the low-rank adapters in the end. Thus, these low-rank adapters replace the whole pre-trained weights, achieving the goals of compression and fine-tuning at the same time. Empirical analysis across various models demonstrates that PC-LoRA achieves parameter and FLOPs compression rates of 94.36%/89.1% for vision models, e.g., ViT-B, and 93.42%/84.2% parameters and FLOPs compressions for language models, e.g., BERT.
Read more6/14/2024