Pre-trained Vision-Language Models Learn Discoverable Visual Concepts
2404.12652
0
0
Abstract
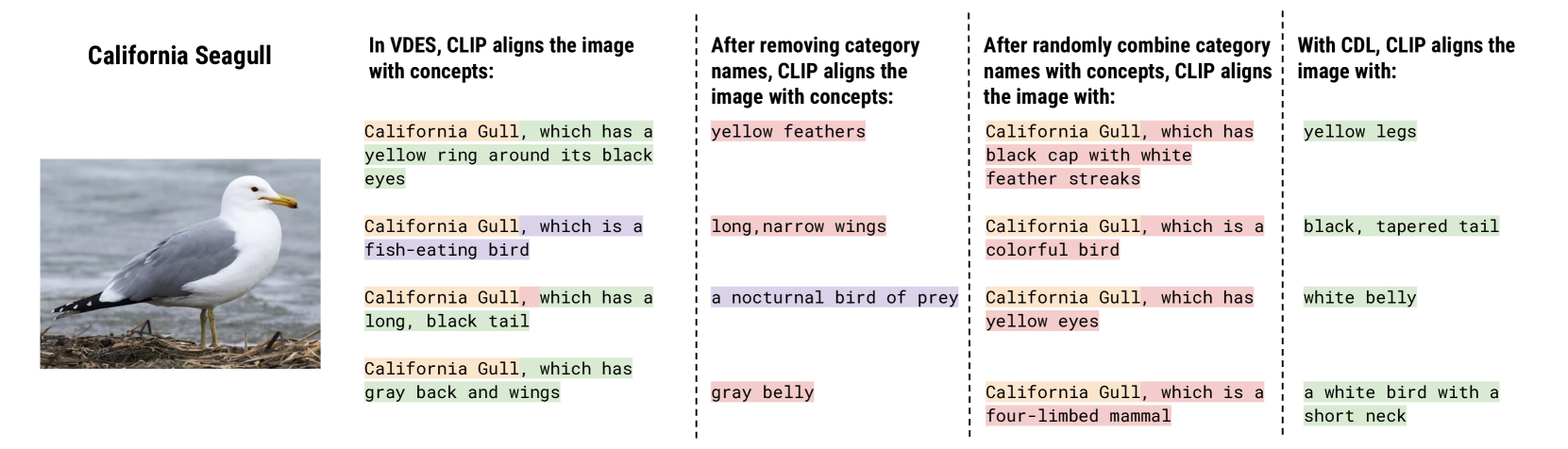
Do vision-language models (VLMs) pre-trained to caption an image of a durian learn visual concepts such as brown (color) and spiky (texture) at the same time? We aim to answer this question as visual concepts learned for free would enable wide applications such as neuro-symbolic reasoning or human-interpretable object classification. We assume that the visual concepts, if captured by pre-trained VLMs, can be extracted by their vision-language interface with text-based concept prompts. We observe that recent works prompting VLMs with concepts often differ in their strategies to define and evaluate the visual concepts, leading to conflicting conclusions. We propose a new concept definition strategy based on two observations: First, certain concept prompts include shortcuts that recognize correct concepts for wrong reasons; Second, multimodal information (e.g. visual discriminativeness, and textual knowledge) should be leveraged when selecting the concepts. Our proposed concept discovery and learning (CDL) framework is thus designed to identify a diverse list of generic visual concepts (e.g. spiky as opposed to spiky durian), which are ranked and selected based on visual and language mutual information. We carefully design quantitative and human evaluations of the discovered concepts on six diverse visual recognition datasets, which confirm that pre-trained VLMs do learn visual concepts that provide accurate and thorough descriptions for the recognized objects. All code and models are publicly released.
Create account to get full access
Overview
- Explores how pre-trained vision-language models can learn discoverable visual concepts
- Investigates the alignment between model-discovered visual concepts and human-annotated visual concepts
- Proposes a novel approach to extract and analyze visual concepts learned by these models
Plain English Explanation
This research paper examines how pre-trained vision-language models can discover and learn visual concepts, which are the fundamental building blocks that allow models to understand and reason about the visual world. The researchers were interested in seeing how well the visual concepts learned by these models align with the concepts that humans would typically identify.
To do this, the researchers developed a novel method to extract and analyze the visual concepts learned by pre-trained vision-language models. They then compared these model-discovered concepts to human-annotated visual concepts, which are concepts that people have explicitly identified and labeled.
The key finding is that pre-trained vision-language models are able to learn a wide range of visual concepts that are highly aligned with human-annotated concepts. This suggests that these models are developing a deep understanding of the visual world that is similar to how humans perceive and conceptualize it.
This research has important implications for the development of more advanced vision-language models that can reason about and interact with the visual world in more natural and human-like ways. It also opens up new avenues for analyzing the inner workings of neural networks to better understand how they perceive and understand visual information.
Technical Explanation
The researchers developed a novel approach to extract and analyze the visual concepts learned by pre-trained vision-language models. They first used self-supervised learning to train these models on large-scale image-text datasets, allowing the models to learn rich representations of visual and linguistic information.
They then applied a concept discovery algorithm to the trained models, which identified the key visual concepts that the models had learned. This involved finding the visual features that were most strongly associated with specific language tokens in the model's output.
To evaluate the discovered concepts, the researchers compared them to human-annotated visual concepts from existing datasets. They found a high degree of alignment between the model-discovered concepts and the human-annotated concepts, suggesting that the models were developing an understanding of the visual world that was similar to human perception.
The researchers also conducted several experiments to further investigate the properties of the discovered concepts. For example, they found that the concepts were highly interpretable, meaning that they could be easily understood and described by humans. They also found that the concepts were hierarchical in nature, with more general concepts being composed of more specific sub-concepts.
Overall, this research provides valuable insights into the inner workings of pre-trained vision-language models and how they can learn to perceive and understand the visual world in ways that align with human cognition. This has important implications for the development of more advanced AI systems that can interact with the world in more natural and human-like ways.
Critical Analysis
The researchers acknowledge several limitations and areas for further research in their paper. For example, they note that their concept discovery algorithm may not capture all of the relevant visual concepts learned by the models, and that more sophisticated techniques may be needed to fully understand the models' representations.
Additionally, the researchers only evaluated the models on a relatively small set of human-annotated visual concepts, and it's possible that the models have learned many other concepts that were not captured in these datasets. Further research would be needed to explore the full breadth of the models' visual understanding.
Another potential concern is that the high alignment between model-discovered and human-annotated concepts may be influenced by biases in the training data or the way the models were developed. It's possible that the models are picking up on societal or cultural biases that are present in the data, which could limit their ability to perceive the visual world in a truly objective and unbiased way.
Overall, this research represents an important step forward in understanding the inner workings of pre-trained vision-language models and how they can learn to perceive and reason about the visual world. However, there is still much more work to be done to fully explore the capabilities and limitations of these models, and to develop even more advanced vision-language systems that can interact with the world in more natural and human-like ways.
Conclusion
This research paper presents a novel approach for extracting and analyzing the visual concepts learned by pre-trained vision-language models. The key finding is that these models are able to discover a wide range of visual concepts that are highly aligned with human-annotated concepts, suggesting that they are developing a deep understanding of the visual world that is similar to human perception.
This has important implications for the development of more advanced AI systems that can interact with the world in more natural and human-like ways. It also opens up new avenues for analyzing the inner workings of neural networks to better understand how they perceive and reason about visual information.
While the research has some limitations and areas for further exploration, it represents an important step forward in the field of vision-language AI. By continuing to study and refine these models, researchers can work towards creating AI systems that can truly understand and engage with the visual world in ways that are more meaningful and intuitive for humans.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
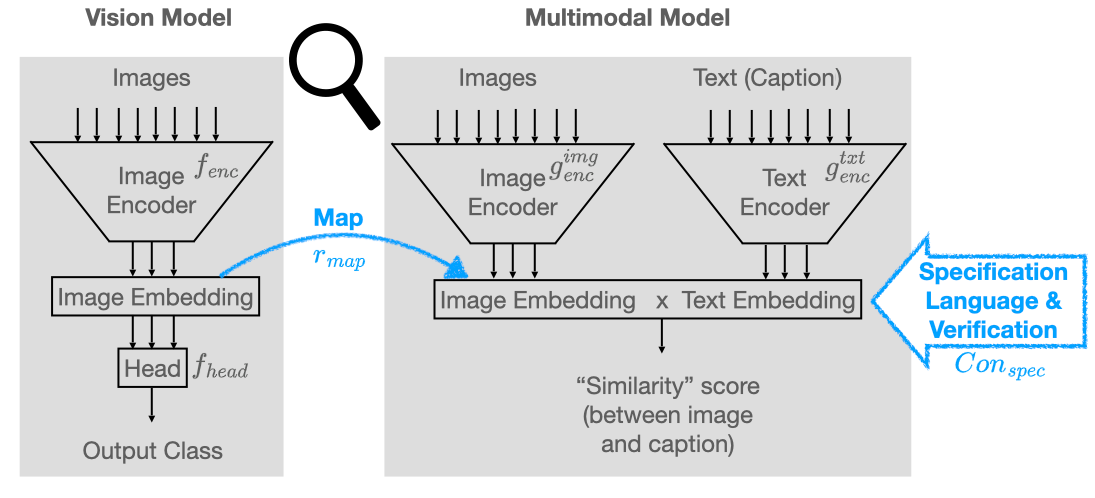
Concept-based Analysis of Neural Networks via Vision-Language Models
Ravi Mangal, Nina Narodytska, Divya Gopinath, Boyue Caroline Hu, Anirban Roy, Susmit Jha, Corina Pasareanu
0
0
The analysis of vision-based deep neural networks (DNNs) is highly desirable but it is very challenging due to the difficulty of expressing formal specifications for vision tasks and the lack of efficient verification procedures. In this paper, we propose to leverage emerging multimodal, vision-language, foundation models (VLMs) as a lens through which we can reason about vision models. VLMs have been trained on a large body of images accompanied by their textual description, and are thus implicitly aware of high-level, human-understandable concepts describing the images. We describe a logical specification language $texttt{Con}_{texttt{spec}}$ designed to facilitate writing specifications in terms of these concepts. To define and formally check $texttt{Con}_{texttt{spec}}$ specifications, we build a map between the internal representations of a given vision model and a VLM, leading to an efficient verification procedure of natural-language properties for vision models. We demonstrate our techniques on a ResNet-based classifier trained on the RIVAL-10 dataset using CLIP as the multimodal model.
4/12/2024
⛏️
Language-Informed Visual Concept Learning
Sharon Lee, Yunzhi Zhang, Shangzhe Wu, Jiajun Wu
0
0
Our understanding of the visual world is centered around various concept axes, characterizing different aspects of visual entities. While different concept axes can be easily specified by language, e.g. color, the exact visual nuances along each axis often exceed the limitations of linguistic articulations, e.g. a particular style of painting. In this work, our goal is to learn a language-informed visual concept representation, by simply distilling large pre-trained vision-language models. Specifically, we train a set of concept encoders to encode the information pertinent to a set of language-informed concept axes, with an objective of reproducing the input image through a pre-trained Text-to-Image (T2I) model. To encourage better disentanglement of different concept encoders, we anchor the concept embeddings to a set of text embeddings obtained from a pre-trained Visual Question Answering (VQA) model. At inference time, the model extracts concept embeddings along various axes from new test images, which can be remixed to generate images with novel compositions of visual concepts. With a lightweight test-time finetuning procedure, it can also generalize to novel concepts unseen at training.
4/4/2024
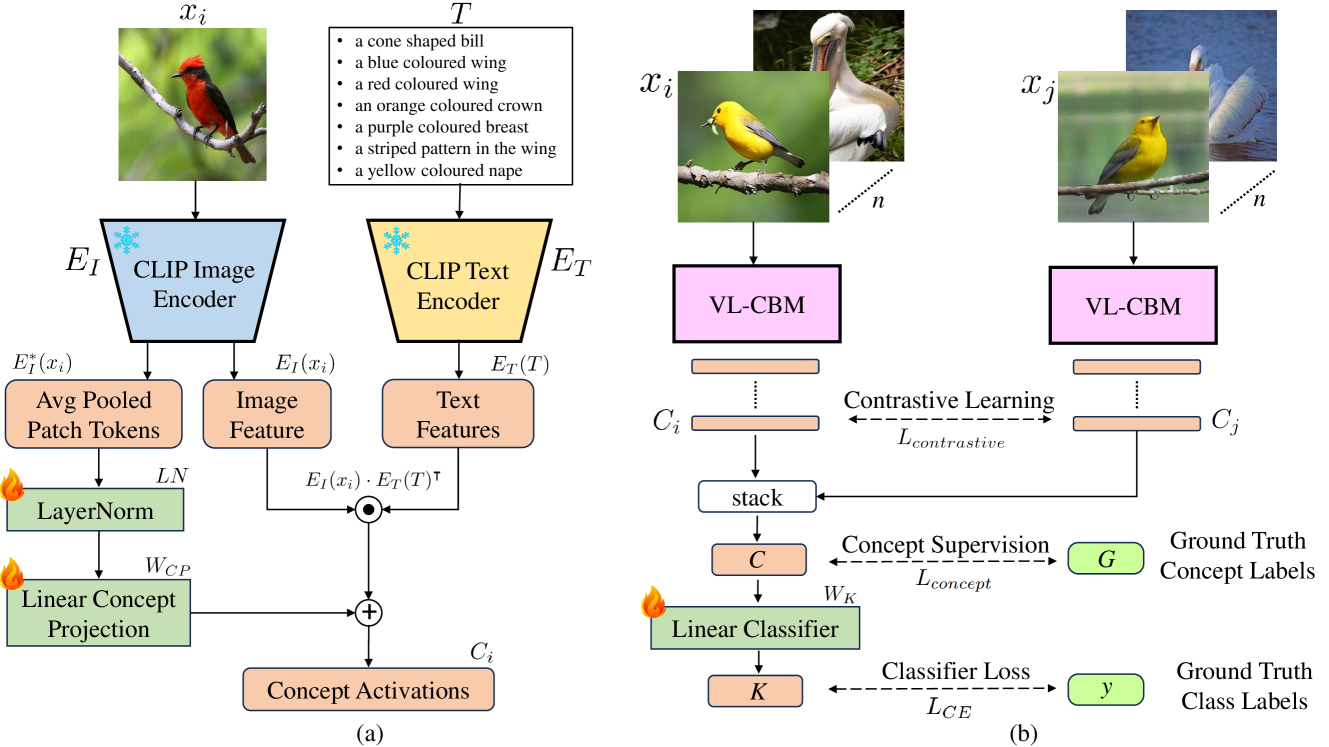
Improving Concept Alignment in Vision-Language Concept Bottleneck Models
Nithish Muthuchamy Selvaraj, Xiaobao Guo, Bingquan Shen, Adams Wai-Kin Kong, Alex Kot
0
0
Concept Bottleneck Models (CBM) map the input image to a high-level human-understandable concept space and then make class predictions based on these concepts. Recent approaches automate the construction of CBM by prompting Large Language Models (LLM) to generate text concepts and then use Vision Language Models (VLM) to obtain concept scores to train a CBM. However, it is desired to build CBMs with concepts defined by human experts instead of LLM generated concepts to make them more trustworthy. In this work, we take a closer inspection on the faithfulness of VLM concept scores for such expert-defined concepts in domains like fine-grain bird species classification and animal classification. Our investigations reveal that frozen VLMs, like CLIP, struggle to correctly associate a concept to the corresponding visual input despite achieving a high classification performance. To address this, we propose a novel Contrastive Semi-Supervised (CSS) learning method which uses a few labeled concept examples to improve concept alignment (activate truthful visual concepts) in CLIP model. Extensive experiments on three benchmark datasets show that our approach substantially increases the concept accuracy and classification accuracy, yet requires only a fraction of the human-annotated concept labels. To further improve the classification performance, we also introduce a new class-level intervention procedure for fine-grain classification problems that identifies the confounding classes and intervenes their concept space to reduce errors.
5/6/2024

The Neglected Tails in Vision-Language Models
Shubham Parashar, Zhiqiu Lin, Tian Liu, Xiangjue Dong, Yanan Li, Deva Ramanan, James Caverlee, Shu Kong
0
0
Vision-language models (VLMs) excel in zero-shot recognition but their performance varies greatly across different visual concepts. For example, although CLIP achieves impressive accuracy on ImageNet (60-80%), its performance drops below 10% for more than ten concepts like night snake, presumably due to their limited presence in the pretraining data. However, measuring the frequency of concepts in VLMs' large-scale datasets is challenging. We address this by using large language models (LLMs) to count the number of pretraining texts that contain synonyms of these concepts. Our analysis confirms that popular datasets, such as LAION, exhibit a long-tailed concept distribution, yielding biased performance in VLMs. We also find that downstream applications of VLMs, including visual chatbots (e.g., GPT-4V) and text-to-image models (e.g., Stable Diffusion), often fail to recognize or generate images of rare concepts identified by our method. To mitigate the imbalanced performance of zero-shot VLMs, we propose REtrieval-Augmented Learning (REAL). First, instead of prompting VLMs using the original class names, REAL uses their most frequent synonyms found in pretraining texts. This simple change already outperforms costly human-engineered and LLM-enriched prompts over nine benchmark datasets. Second, REAL trains a linear classifier on a small yet balanced set of pretraining data retrieved using concept synonyms. REAL surpasses the previous zero-shot SOTA, using 400x less storage and 10,000x less training time!
5/24/2024