Concept Bottleneck Models Without Predefined Concepts

0

Sign in to get full access
Overview
- Concept Bottleneck Models Without Predefined Concepts is a research paper that introduces a new approach to building machine learning models.
- The key idea is to learn concepts from data without relying on predefined concepts, in contrast to traditional concept bottleneck models.
- The paper proposes an unsupervised concept bottleneck model that can automatically discover meaningful concepts from data.
- Experiments show this approach can achieve performance comparable to traditional concept bottleneck models while providing more flexibility and interpretability.
Plain English Explanation
The paper introduces a new type of machine learning model called an unsupervised concept bottleneck model. Traditional concept bottleneck models rely on predefined concepts, which can limit their flexibility and interpretability.
This new approach allows the model to automatically learn meaningful concepts from the data, rather than using predefined ones. The key idea is to have the model discover these concepts on its own, without being given a set of predefined concepts to use.
This provides several benefits:
- Flexibility: The model can adapt to different datasets and problems, rather than being constrained by predefined concepts.
- Interpretability: The learned concepts are more closely tied to the data, making the model's decision-making more transparent and interpretable.
- Performance: Experiments show the unsupervised approach can achieve comparable performance to traditional concept bottleneck models.
Overall, this research explores a new way to build more flexible and interpretable machine learning models by having them discover their own concepts from the data, rather than relying on predefined ones.
Technical Explanation
The paper proposes an unsupervised concept bottleneck model, which learns meaningful concepts from data without relying on predefined concepts. This contrasts with traditional concept bottleneck models, which use a fixed set of predefined concepts.
The key components of the unsupervised approach are:
- Encoder: Encodes the input data into a compact representation.
- Concept Extractor: Learns a set of concepts that capture the important factors in the data.
- Decoder: Reconstructs the original input from the learned concepts.
The model is trained end-to-end to optimize both the concept extraction and reconstruction objectives. This allows the model to automatically discover relevant concepts that are tailored to the data, rather than using a predefined set.
Experiments on image classification tasks show that the unsupervised concept bottleneck model can achieve performance comparable to traditional concept bottleneck models, while providing more flexibility and interpretability. The learned concepts are more closely tied to the data, making the model's decision-making more transparent.
Critical Analysis
The paper presents a promising approach to building more flexible and interpretable machine learning models. By allowing the model to discover its own concepts, it can adapt to different datasets and problems, rather than being constrained by predefined concepts.
However, the paper does not address some potential limitations and areas for further research:
- Concept Stability: The paper does not discuss how stable the learned concepts are across different training runs or datasets. Ensuring consistent and meaningful concepts is important for interpretability.
- Concept Interpretability: While the learned concepts are more closely tied to the data, the paper does not provide a deep analysis of how interpretable these concepts are to humans. Developing techniques to improve the interpretability of the learned concepts could be valuable.
- Scalability: The experiments in the paper are limited to relatively small-scale image classification tasks. Evaluating the approach on larger and more complex datasets would be important to understand its scalability.
Despite these limitations, the unsupervised concept bottleneck model represents an interesting step towards more flexible and interpretable machine learning systems. Further research in this direction could lead to significant advancements in the field.
Conclusion
This research paper introduces an unsupervised concept bottleneck model, which can automatically discover meaningful concepts from data without relying on predefined concepts. This approach provides several benefits, including improved flexibility, interpretability, and performance compared to traditional concept bottleneck models.
The paper's key contribution is demonstrating the feasibility and potential of learning concepts directly from data, rather than using a fixed set of predefined concepts. This opens up new avenues for developing more adaptable and transparent machine learning models, which could have important implications for a wide range of applications.
While the paper identifies some areas for further research, such as concept stability and scalability, the unsupervised concept bottleneck model represents an exciting step forward in the field of machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Concept Bottleneck Models Without Predefined Concepts
Simon Schrodi, Julian Schur, Max Argus, Thomas Brox
There has been considerable recent interest in interpretable concept-based models such as Concept Bottleneck Models (CBMs), which first predict human-interpretable concepts and then map them to output classes. To reduce reliance on human-annotated concepts, recent works have converted pretrained black-box models into interpretable CBMs post-hoc. However, these approaches predefine a set of concepts, assuming which concepts a black-box model encodes in its representations. In this work, we eliminate this assumption by leveraging unsupervised concept discovery to automatically extract concepts without human annotations or a predefined set of concepts. We further introduce an input-dependent concept selection mechanism that ensures only a small subset of concepts is used across all classes. We show that our approach improves downstream performance and narrows the performance gap to black-box models, while using significantly fewer concepts in the classification. Finally, we demonstrate how large vision-language models can intervene on the final model weights to correct model errors.
Read more7/8/2024

0
Constructing Concept-based Models to Mitigate Spurious Correlations with Minimal Human Effort
Jeeyung Kim, Ze Wang, Qiang Qiu
Enhancing model interpretability can address spurious correlations by revealing how models draw their predictions. Concept Bottleneck Models (CBMs) can provide a principled way of disclosing and guiding model behaviors through human-understandable concepts, albeit at a high cost of human efforts in data annotation. In this paper, we leverage a synergy of multiple foundation models to construct CBMs with nearly no human effort. We discover undesirable biases in CBMs built on pre-trained models and propose a novel framework designed to exploit pre-trained models while being immune to these biases, thereby reducing vulnerability to spurious correlations. Specifically, our method offers a seamless pipeline that adopts foundation models for assessing potential spurious correlations in datasets, annotating concepts for images, and refining the annotations for improved robustness. We evaluate the proposed method on multiple datasets, and the results demonstrate its effectiveness in reducing model reliance on spurious correlations while preserving its interpretability.
Read more7/15/2024
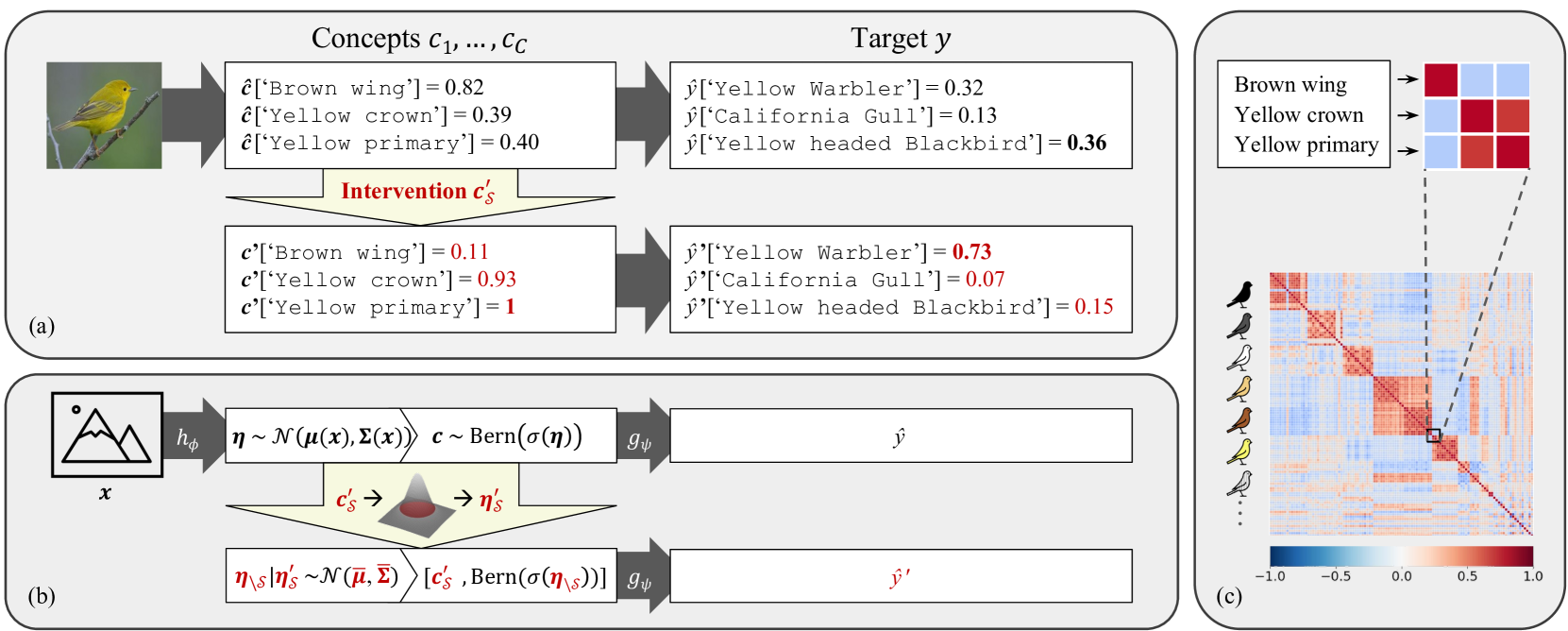
0
Stochastic Concept Bottleneck Models
Moritz Vandenhirtz, Sonia Laguna, Riv{c}ards Marcinkeviv{c}s, Julia E. Vogt
Concept Bottleneck Models (CBMs) have emerged as a promising interpretable method whose final prediction is based on intermediate, human-understandable concepts rather than the raw input. Through time-consuming manual interventions, a user can correct wrongly predicted concept values to enhance the model's downstream performance. We propose Stochastic Concept Bottleneck Models (SCBMs), a novel approach that models concept dependencies. In SCBMs, a single-concept intervention affects all correlated concepts, thereby improving intervention effectiveness. Unlike previous approaches that model the concept relations via an autoregressive structure, we introduce an explicit, distributional parameterization that allows SCBMs to retain the CBMs' efficient training and inference procedure. Additionally, we leverage the parameterization to derive an effective intervention strategy based on the confidence region. We show empirically on synthetic tabular and natural image datasets that our approach improves intervention effectiveness significantly. Notably, we showcase the versatility and usability of SCBMs by examining a setting with CLIP-inferred concepts, alleviating the need for manual concept annotations.
Read more6/28/2024
🌿
0
Coarse-to-Fine Concept Bottleneck Models
Konstantinos P. Panousis, Dino Ienco, Diego Marcos
Deep learning algorithms have recently gained significant attention due to their impressive performance. However, their high complexity and un-interpretable mode of operation hinders their confident deployment in real-world safety-critical tasks. This work targets ante hoc interpretability, and specifically Concept Bottleneck Models (CBMs). Our goal is to design a framework that admits a highly interpretable decision making process with respect to human understandable concepts, on two levels of granularity. To this end, we propose a novel two-level concept discovery formulation leveraging: (i) recent advances in vision-language models, and (ii) an innovative formulation for coarse-to-fine concept selection via data-driven and sparsity-inducing Bayesian arguments. Within this framework, concept information does not solely rely on the similarity between the whole image and general unstructured concepts; instead, we introduce the notion of concept hierarchy to uncover and exploit more granular concept information residing in patch-specific regions of the image scene. As we experimentally show, the proposed construction not only outperforms recent CBM approaches, but also yields a principled framework towards interpetability.
Read more6/28/2024