Constructing Concept-based Models to Mitigate Spurious Correlations with Minimal Human Effort

0

Sign in to get full access
Overview
- This paper explores a novel approach to constructing concept-based machine learning models that can mitigate the impact of spurious correlations with minimal human effort.
- The key ideas include using a Concept Bottleneck Model architecture and employing techniques like Stochastic Concept Bottleneck Models and Concept Realignment to improve model robustness.
- The authors also discuss extensions like Coarse-to-Fine Concept Bottleneck Models and Editable Concept Bottleneck Models to further enhance the capabilities of these concept-based models.
Plain English Explanation
The paper is about a new way to build machine learning models that can better handle situations where there are sneaky relationships (called "spurious correlations") in the data that the model might latch onto, leading to poor performance. The key idea is to use a special kind of model architecture called a "Concept Bottleneck Model" that forces the model to first identify important "concepts" in the data before making predictions.
This helps the model focus on the right things and avoid getting misled by the sneaky relationships. The researchers also tested out some additional techniques, like introducing randomness into how the concepts are identified, and allowing the model to adjust the importance of different concepts, to make the models even more robust.
The paper explores a few variations on this core idea, like building models that can go from coarse to fine-grained concepts, and models that allow humans to directly edit and refine the concepts the model uses. The overall goal is to create machine learning systems that are more reliable and less susceptible to being tricked by quirks in the training data.
Technical Explanation
The paper presents a novel approach to constructing concept-based machine learning models that can mitigate the impact of spurious correlations with minimal human effort. At the core of their approach is the Concept Bottleneck Model architecture, which forces the model to first identify a set of relevant "concepts" before making predictions.
To improve the robustness of these concept-based models, the authors explore several techniques:
- Stochastic Concept Bottleneck Models: Introducing randomness into the concept identification process to encourage the model to learn more generalizable concepts.
- Concept Realignment: Allowing the model to dynamically adjust the importance of different concepts based on the input, to better handle context-dependent relationships.
The paper also discusses extensions to the core Concept Bottleneck Model approach:
- Coarse-to-Fine Concept Bottleneck Models: Building models that can reason about concepts at multiple levels of abstraction, from coarse to fine-grained.
- Editable Concept Bottleneck Models: Enabling humans to directly edit and refine the concepts used by the model, allowing for greater control and interpretability.
Through extensive experiments, the authors demonstrate the effectiveness of their concept-based modeling approach in mitigating the impact of spurious correlations across a variety of benchmark datasets and tasks.
Critical Analysis
The paper presents a thoughtful and methodical approach to addressing the challenge of spurious correlations in machine learning, a critical issue that can severely limit the reliability and generalizability of models. The authors' focus on concept-based modeling, with techniques like Stochastic Concept Bottleneck Models and Concept Realignment, is a promising direction for improving model robustness.
One potential limitation of the approach is the reliance on human-defined or machine-learned concepts, which may not always capture the full complexity of the underlying data. The authors acknowledge this and discuss extensions like Coarse-to-Fine Concept Bottleneck Models and Editable Concept Bottleneck Models as ways to address this, but further research may be needed to fully understand the capabilities and limitations of these concept-based approaches.
Additionally, the paper does not provide a deep dive into the computational and storage overhead of the proposed techniques, which could be an important practical consideration for real-world applications. It would be valuable to see an analysis of the trade-offs between model complexity, training time, and performance improvements.
Overall, this paper represents an important step forward in the quest to build more reliable and trustworthy machine learning systems. The authors' focus on mitigating spurious correlations through innovative concept-based modeling techniques is a compelling approach that warrants further exploration and refinement.
Conclusion
This paper introduces a novel concept-based modeling approach to mitigating the impact of spurious correlations in machine learning, a critical issue that can significantly undermine the reliability and generalizability of models. By leveraging techniques like Stochastic Concept Bottleneck Models and Concept Realignment, the authors demonstrate how concept-based models can be made more robust and adaptable to context-dependent relationships in the data.
The extensions discussed, such as Coarse-to-Fine Concept Bottleneck Models and Editable Concept Bottleneck Models, further enhance the flexibility and interpretability of these concept-based approaches. While the paper does not address all the practical considerations, it represents an important contribution to the field of machine learning and paves the way for future research and development of more reliable and trustworthy AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Constructing Concept-based Models to Mitigate Spurious Correlations with Minimal Human Effort
Jeeyung Kim, Ze Wang, Qiang Qiu
Enhancing model interpretability can address spurious correlations by revealing how models draw their predictions. Concept Bottleneck Models (CBMs) can provide a principled way of disclosing and guiding model behaviors through human-understandable concepts, albeit at a high cost of human efforts in data annotation. In this paper, we leverage a synergy of multiple foundation models to construct CBMs with nearly no human effort. We discover undesirable biases in CBMs built on pre-trained models and propose a novel framework designed to exploit pre-trained models while being immune to these biases, thereby reducing vulnerability to spurious correlations. Specifically, our method offers a seamless pipeline that adopts foundation models for assessing potential spurious correlations in datasets, annotating concepts for images, and refining the annotations for improved robustness. We evaluate the proposed method on multiple datasets, and the results demonstrate its effectiveness in reducing model reliance on spurious correlations while preserving its interpretability.
Read more7/15/2024

0
Concept Bottleneck Models Without Predefined Concepts
Simon Schrodi, Julian Schur, Max Argus, Thomas Brox
There has been considerable recent interest in interpretable concept-based models such as Concept Bottleneck Models (CBMs), which first predict human-interpretable concepts and then map them to output classes. To reduce reliance on human-annotated concepts, recent works have converted pretrained black-box models into interpretable CBMs post-hoc. However, these approaches predefine a set of concepts, assuming which concepts a black-box model encodes in its representations. In this work, we eliminate this assumption by leveraging unsupervised concept discovery to automatically extract concepts without human annotations or a predefined set of concepts. We further introduce an input-dependent concept selection mechanism that ensures only a small subset of concepts is used across all classes. We show that our approach improves downstream performance and narrows the performance gap to black-box models, while using significantly fewer concepts in the classification. Finally, we demonstrate how large vision-language models can intervene on the final model weights to correct model errors.
Read more7/8/2024
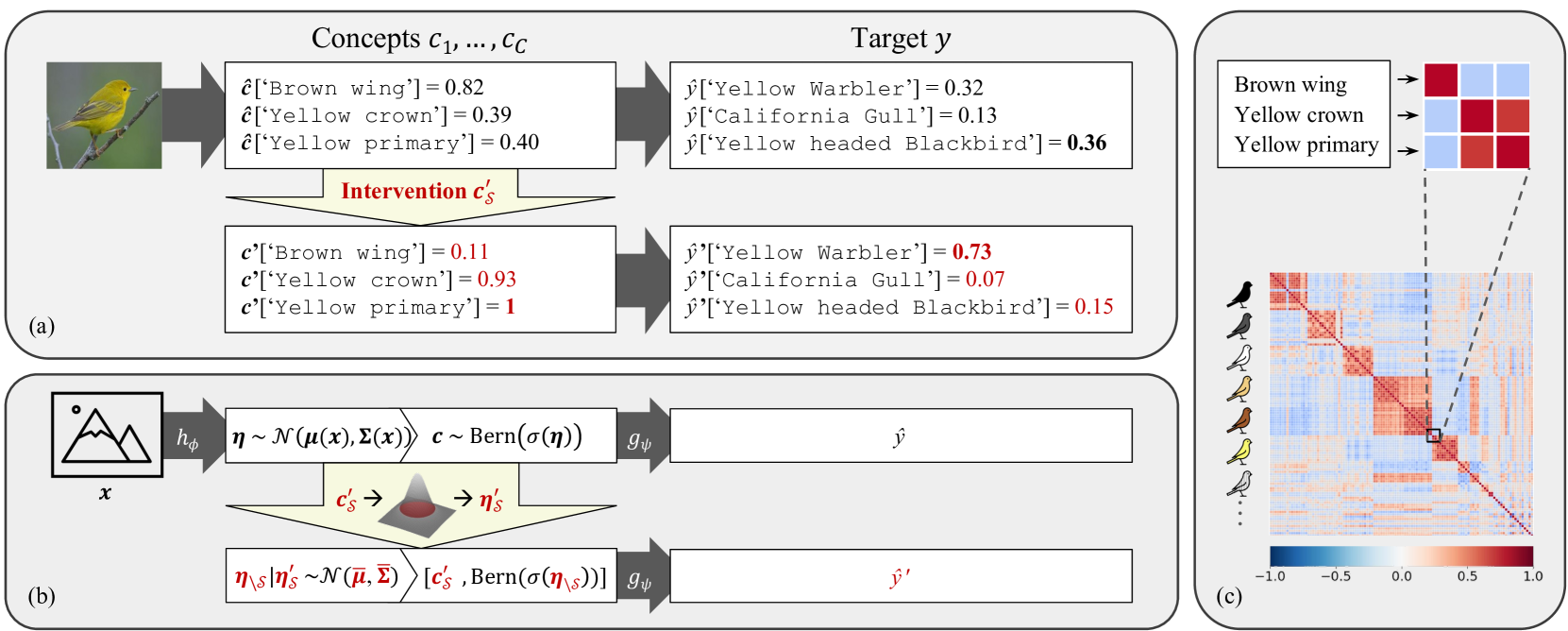
0
Stochastic Concept Bottleneck Models
Moritz Vandenhirtz, Sonia Laguna, Riv{c}ards Marcinkeviv{c}s, Julia E. Vogt
Concept Bottleneck Models (CBMs) have emerged as a promising interpretable method whose final prediction is based on intermediate, human-understandable concepts rather than the raw input. Through time-consuming manual interventions, a user can correct wrongly predicted concept values to enhance the model's downstream performance. We propose Stochastic Concept Bottleneck Models (SCBMs), a novel approach that models concept dependencies. In SCBMs, a single-concept intervention affects all correlated concepts, thereby improving intervention effectiveness. Unlike previous approaches that model the concept relations via an autoregressive structure, we introduce an explicit, distributional parameterization that allows SCBMs to retain the CBMs' efficient training and inference procedure. Additionally, we leverage the parameterization to derive an effective intervention strategy based on the confidence region. We show empirically on synthetic tabular and natural image datasets that our approach improves intervention effectiveness significantly. Notably, we showcase the versatility and usability of SCBMs by examining a setting with CLIP-inferred concepts, alleviating the need for manual concept annotations.
Read more6/28/2024

0
Improving Intervention Efficacy via Concept Realignment in Concept Bottleneck Models
Nishad Singhi, Jae Myung Kim, Karsten Roth, Zeynep Akata
Concept Bottleneck Models (CBMs) ground image classification on human-understandable concepts to allow for interpretable model decisions. Crucially, the CBM design inherently allows for human interventions, in which expert users are given the ability to modify potentially misaligned concept choices to influence the decision behavior of the model in an interpretable fashion. However, existing approaches often require numerous human interventions per image to achieve strong performances, posing practical challenges in scenarios where obtaining human feedback is expensive. In this paper, we find that this is noticeably driven by an independent treatment of concepts during intervention, wherein a change of one concept does not influence the use of other ones in the model's final decision. To address this issue, we introduce a trainable concept intervention realignment module, which leverages concept relations to realign concept assignments post-intervention. Across standard, real-world benchmarks, we find that concept realignment can significantly improve intervention efficacy; significantly reducing the number of interventions needed to reach a target classification performance or concept prediction accuracy. In addition, it easily integrates into existing concept-based architectures without requiring changes to the models themselves. This reduced cost of human-model collaboration is crucial to enhancing the feasibility of CBMs in resource-constrained environments. Our code is available at: https://github.com/ExplainableML/concept_realignment.
Read more8/7/2024