Confidence Estimation for LLM-Based Dialogue State Tracking

0
Sign in to get full access
Overview
- Examines the challenge of confidence estimation for large language model (LLM)-based dialogue state tracking
- Proposes an approach to estimate the confidence of LLM-based dialogue state tracking predictions
- Evaluates the approach on multiple dialogue datasets and compares it to existing methods
Plain English Explanation
The paper explores the issue of confidence estimation for dialogue state tracking using large language models (LLMs). Dialogue state tracking is a key component of conversational AI systems, where the system needs to understand the current state of the dialogue in order to respond appropriately.
However, LLMs can sometimes make incorrect predictions, so it's important for the system to have a way to estimate how confident it is in its predictions. This paper proposes a new approach for confidence estimation that can be used with LLM-based dialogue state tracking models.
The researchers evaluate their approach on several different dialogue datasets and compare it to existing methods. The goal is to provide a more accurate and reliable way for conversational AI systems to assess the confidence of their dialogue state tracking predictions.
Technical Explanation
The paper first reviews related work on confidence estimation for dialogue state tracking, including both traditional and LLM-based approaches.
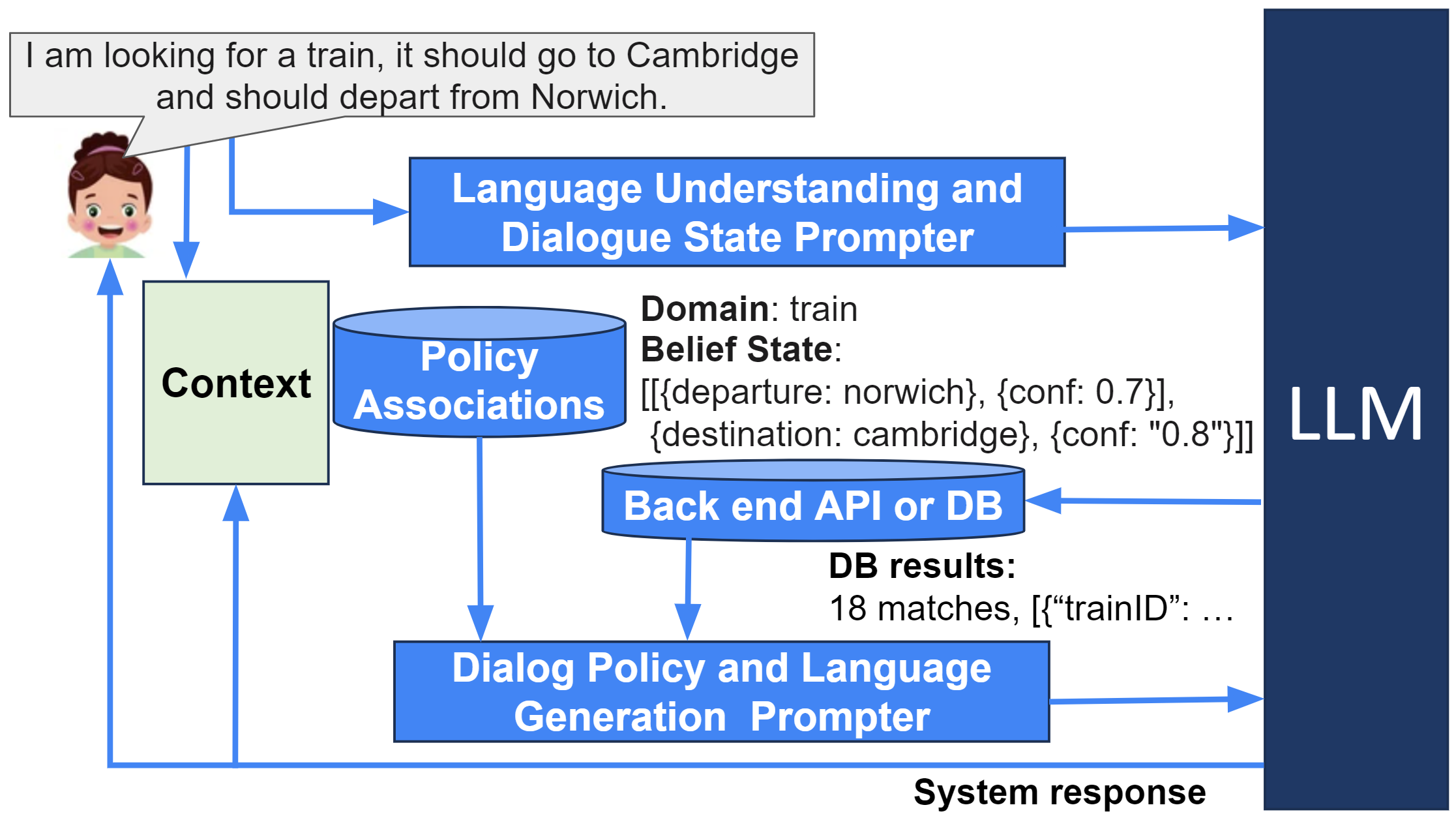
The proposed confidence estimation approach involves training a separate model to predict the confidence score for each dialogue state tracking prediction made by the LLM. This confidence model is trained using a combination of the LLM's internal representations and dialogue-specific features.
The researchers evaluate their approach on multiple dialogue datasets and compare it to existing confidence estimation methods. They find that their approach outperforms the baselines, indicating that it can provide more accurate and reliable confidence estimates for LLM-based dialogue state tracking.
Critical Analysis
The paper provides a thorough analysis of the proposed confidence estimation approach and its performance compared to existing methods. However, the authors acknowledge that their approach still has some limitations, such as the need for additional dialogue-specific features and the potential for overfitting on the training data.
Additionally, the paper does not explore the impact of confidence estimation on the overall performance of the dialogue system or how it might affect user experience. Further research could investigate these aspects and explore ways to integrate confidence estimation into the broader conversational AI ecosystem.
Conclusion
This paper presents a novel approach for confidence estimation in LLM-based dialogue state tracking. The proposed method demonstrates improved performance over existing techniques, highlighting the importance of accurately assessing the confidence of LLM predictions in conversational AI systems.
The findings of this research could have significant implications for the development of more robust and reliable conversational AI assistants, which is a crucial step towards enhancing the user experience and trust in these technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Confidence Estimation for LLM-Based Dialogue State Tracking
Yi-Jyun Sun, Suvodip Dey, Dilek Hakkani-Tur, Gokhan Tur
Estimation of a model's confidence on its outputs is critical for Conversational AI systems based on large language models (LLMs), especially for reducing hallucination and preventing over-reliance. In this work, we provide an exhaustive exploration of methods, including approaches proposed for open- and closed-weight LLMs, aimed at quantifying and leveraging model uncertainty to improve the reliability of LLM-generated responses, specifically focusing on dialogue state tracking (DST) in task-oriented dialogue systems (TODS). Regardless of the model type, well-calibrated confidence scores are essential to handle uncertainties, thereby improving model performance. We evaluate four methods for estimating confidence scores based on softmax, raw token scores, verbalized confidences, and a combination of these methods, using the area under the curve (AUC) metric to assess calibration, with higher AUC indicating better calibration. We also enhance these with a self-probing mechanism, proposed for closed models. Furthermore, we assess these methods using an open-weight model fine-tuned for the task of DST, achieving superior joint goal accuracy (JGA). Our findings also suggest that fine-tuning open-weight LLMs can result in enhanced AUC performance, indicating better confidence score calibration.
Read more9/17/2024
0
A Comprehensive Study of Multilingual Confidence Estimation on Large Language Models
Boyang Xue, Hongru Wang, Rui Wang, Sheng Wang, Zezhong Wang, Yiming Du, Kam-Fai Wong
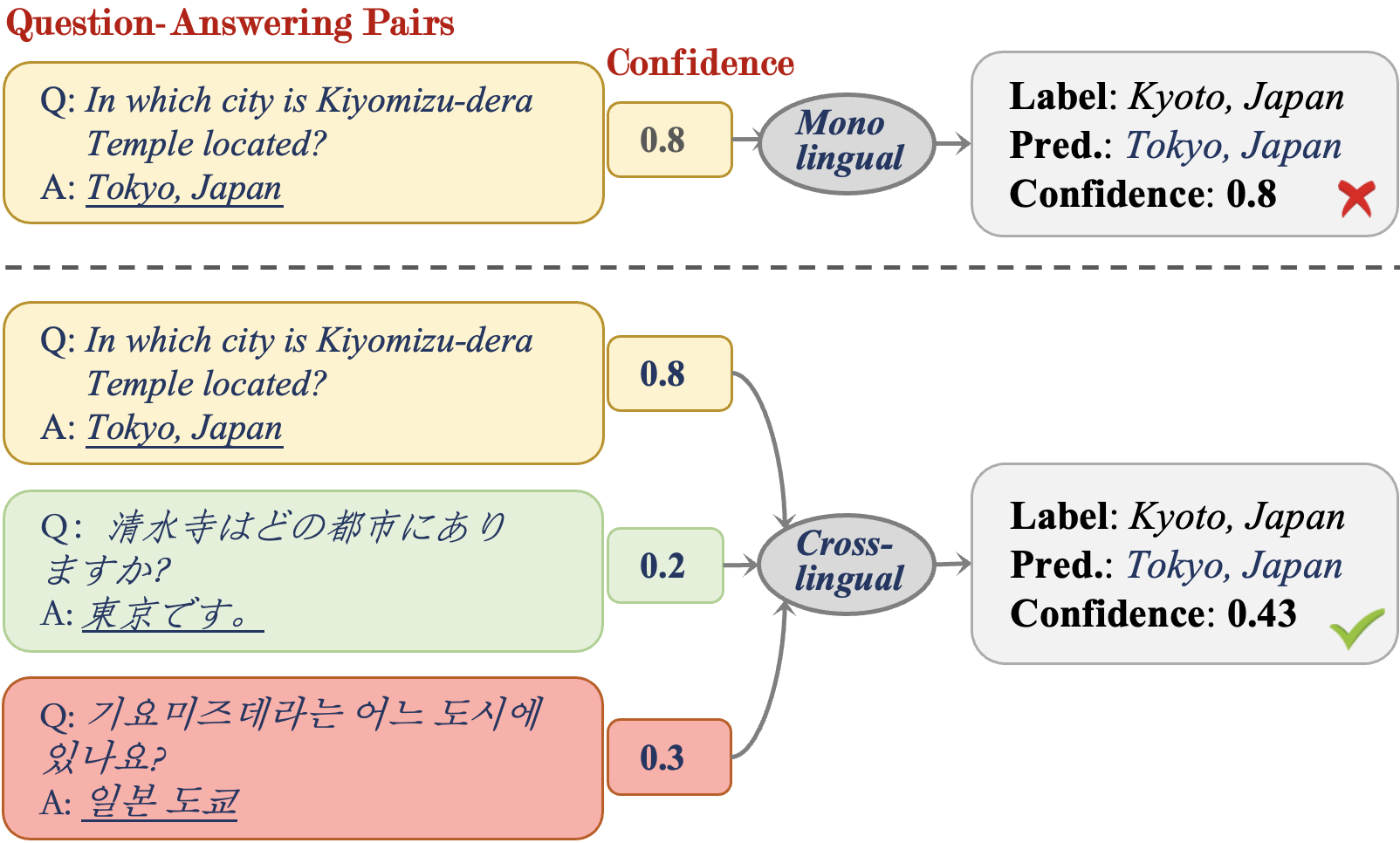
The tendency of Large Language Models (LLMs) to generate hallucinations and exhibit overconfidence in predictions raises concerns regarding their reliability. Confidence or uncertainty estimations indicating the extent of trustworthiness of a model's response are essential to developing reliable AI systems. Current research primarily focuses on LLM confidence estimations in English, remaining a void for other widely used languages and impeding the global development of reliable AI applications. This paper introduces a comprehensive investigation of textbf Multitextbf{ling}ual textbf{Conf}idence estimation (textsc{MlingConf}) on LLMs. First, we introduce an elaborated and expert-checked multilingual QA dataset. Subsequently, we delve into the performance of several confidence estimation methods across diverse languages and examine how these confidence scores can enhance LLM performance through self-refinement. Extensive experiments conducted on the multilingual QA dataset demonstrate that confidence estimation results vary in different languages, and the verbalized numerical confidence estimation method exhibits the best performance among most languages over other methods. Finally, the obtained confidence scores can consistently improve performance as self-refinement feedback across various languages.
Read more6/18/2024
0
Large Language Model Confidence Estimation via Black-Box Access
Tejaswini Pedapati, Amit Dhurandhar, Soumya Ghosh, Soham Dan, Prasanna Sattigeri
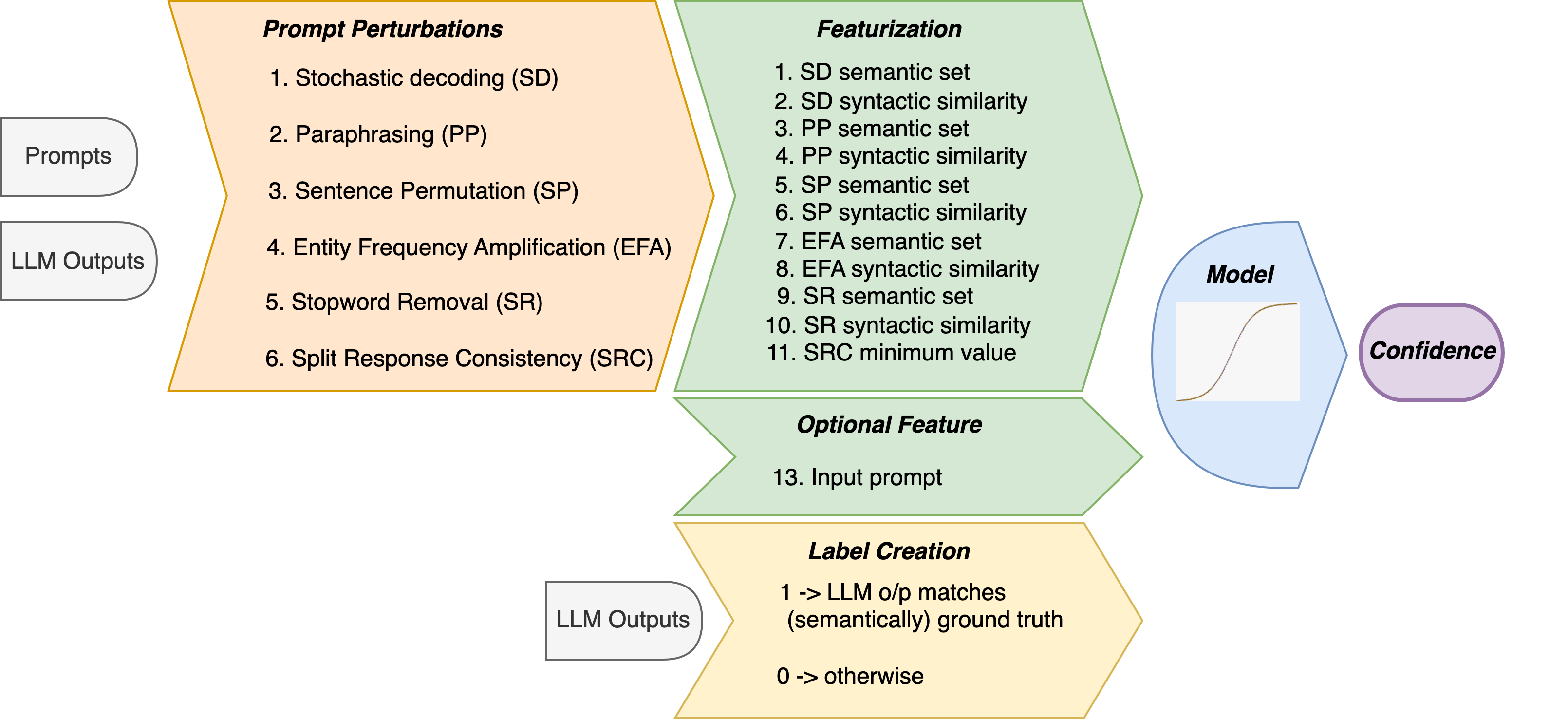
Estimating uncertainty or confidence in the responses of a model can be significant in evaluating trust not only in the responses, but also in the model as a whole. In this paper, we explore the problem of estimating confidence for responses of large language models (LLMs) with simply black-box or query access to them. We propose a simple and extensible framework where, we engineer novel features and train a (interpretable) model (viz. logistic regression) on these features to estimate the confidence. We empirically demonstrate that our simple framework is effective in estimating confidence of flan-ul2, llama-13b and mistral-7b with it consistently outperforming existing black-box confidence estimation approaches on benchmark datasets such as TriviaQA, SQuAD, CoQA and Natural Questions by even over $10%$ (on AUROC) in some cases. Additionally, our interpretable approach provides insight into features that are predictive of confidence, leading to the interesting and useful discovery that our confidence models built for one LLM generalize zero-shot across others on a given dataset.
Read more6/10/2024

0
Confidence Under the Hood: An Investigation into the Confidence-Probability Alignment in Large Language Models
Abhishek Kumar, Robert Morabito, Sanzhar Umbet, Jad Kabbara, Ali Emami
As the use of Large Language Models (LLMs) becomes more widespread, understanding their self-evaluation of confidence in generated responses becomes increasingly important as it is integral to the reliability of the output of these models. We introduce the concept of Confidence-Probability Alignment, that connects an LLM's internal confidence, quantified by token probabilities, to the confidence conveyed in the model's response when explicitly asked about its certainty. Using various datasets and prompting techniques that encourage model introspection, we probe the alignment between models' internal and expressed confidence. These techniques encompass using structured evaluation scales to rate confidence, including answer options when prompting, and eliciting the model's confidence level for outputs it does not recognize as its own. Notably, among the models analyzed, OpenAI's GPT-4 showed the strongest confidence-probability alignment, with an average Spearman's $hat{rho}$ of 0.42, across a wide range of tasks. Our work contributes to the ongoing efforts to facilitate risk assessment in the application of LLMs and to further our understanding of model trustworthiness.
Read more6/18/2024