Conformal Ranked Retrieval

0

Sign in to get full access
Overview
- This paper introduces a new method called Conformal Ranked Retrieval (CoRR) that extends the principles of conformal prediction to ranked retrieval tasks.
- The authors propose using conformal prediction to assign confidence scores to the ranking of retrieved documents, providing a principled way to quantify the uncertainty in the retrieval results.
- The CoRR method is shown to outperform standard retrieval approaches on several benchmark datasets, demonstrating its effectiveness in improving the reliability and interpretability of ranked retrieval.
Plain English Explanation
The paper presents a new approach called Conformal Ranked Retrieval (CoRR) that aims to make document retrieval systems more reliable and transparent. In typical document retrieval, a system takes a user's query and returns a ranked list of relevant documents. However, these rankings can be uncertain, as the system may not be completely sure about the relevance of each document.
The CoRR method tries to address this by using a statistical technique called conformal prediction to assign a "confidence score" to each ranking. This score indicates how certain the system is that the document is relevant to the user's query. This additional information can help users better understand the retrieval results and make more informed decisions.
The authors show that CoRR outperforms standard retrieval approaches on several common benchmarks, suggesting it is an effective way to improve the reliability and interpretability of document retrieval systems. By quantifying the uncertainty in the rankings, CoRR provides users with a more transparent and trustworthy retrieval experience.
Technical Explanation
The CoRR method builds on the principles of conformal prediction, which provides a way to measure the confidence or reliability of machine learning predictions. In the context of ranked retrieval, the authors apply conformal prediction to assign a p-value (confidence score) to each document in the ranking.
The key steps of the CoRR approach are:
- Train a base retrieval model (e.g., a neural ranking model) on a corpus of documents and queries.
- For a given query, use the base model to rank the relevant documents.
- Apply conformal prediction to the ranked list, calculating a p-value for each document that quantifies the confidence in its relevance.
- Return the ranked list of documents along with the associated p-values, which can be used to filter or re-rank the results based on desired confidence thresholds.
The authors demonstrate the effectiveness of CoRR on several benchmark retrieval datasets, showing that it outperforms standard retrieval approaches in terms of both ranking performance and the reliability of the results.
Critical Analysis
The CoRR method presents a promising approach for improving the transparency and reliability of document retrieval systems. By quantifying the uncertainty in the ranking, CoRR provides users with valuable information to better interpret and trust the retrieval results.
However, the paper does not address some important limitations and potential issues. For example, the authors do not discuss how the choice of base retrieval model or the specific conformal prediction technique used can impact the performance and reliability of CoRR. Additionally, the paper does not explore how CoRR might scale to large-scale retrieval tasks or how it might be integrated with other advanced retrieval techniques.
Further research is needed to better understand the strengths and weaknesses of the CoRR approach, as well as its potential for real-world deployment in practical retrieval systems. Rigorous evaluations on a wider range of datasets and user studies to assess the usability and interpretability of the confidence scores would also be valuable.
Conclusion
The Conformal Ranked Retrieval (CoRR) method presented in this paper offers a novel approach to improving the reliability and transparency of document retrieval systems. By applying the principles of conformal prediction to ranked retrieval, CoRR provides a principled way to quantify the uncertainty in the ranking results, empowering users to make more informed decisions.
The authors' empirical results demonstrate the effectiveness of CoRR in outperforming standard retrieval approaches, suggesting that this technique has the potential to significantly enhance the user experience and trust in document retrieval systems. As the field of information retrieval continues to evolve, methods like CoRR that prioritize reliability and interpretability will become increasingly important for building robust and trustworthy search and discovery tools.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Conformal Ranked Retrieval
Yunpeng Xu, Wenge Guo, Zhi Wei
Given the wide adoption of ranked retrieval techniques in various information systems that significantly impact our daily lives, there is an increasing need to assess and address the uncertainty inherent in their predictions. This paper introduces a novel method using the conformal risk control framework to quantitatively measure and manage risks in the context of ranked retrieval problems. Our research focuses on a typical two-stage ranked retrieval problem, where the retrieval stage generates candidates for subsequent ranking. By carefully formulating the conformal risk for each stage, we have developed algorithms to effectively control these risks within their specified bounds. The efficacy of our proposed methods has been demonstrated through comprehensive experiments on three large-scale public datasets for ranked retrieval tasks, including the MSLR-WEB dataset, the Yahoo LTRC dataset and the MS MARCO dataset.
Read more4/30/2024
🏷️
0
Conformal Risk Control for Ordinal Classification
Yunpeng Xu, Wenge Guo, Zhi Wei
As a natural extension to the standard conformal prediction method, several conformal risk control methods have been recently developed and applied to various learning problems. In this work, we seek to control the conformal risk in expectation for ordinal classification tasks, which have broad applications to many real problems. For this purpose, we firstly formulated the ordinal classification task in the conformal risk control framework, and provided theoretic risk bounds of the risk control method. Then we proposed two types of loss functions specially designed for ordinal classification tasks, and developed corresponding algorithms to determine the prediction set for each case to control their risks at a desired level. We demonstrated the effectiveness of our proposed methods, and analyzed the difference between the two types of risks on three different datasets, including a simulated dataset, the UTKFace dataset and the diabetic retinopathy detection dataset.
Read more5/2/2024

0
Trustworthy Classification through Rank-Based Conformal Prediction Sets
Rui Luo, Zhixin Zhou
Machine learning classification tasks often benefit from predicting a set of possible labels with confidence scores to capture uncertainty. However, existing methods struggle with the high-dimensional nature of the data and the lack of well-calibrated probabilities from modern classification models. We propose a novel conformal prediction method that employs a rank-based score function suitable for classification models that predict the order of labels correctly, even if not well-calibrated. Our approach constructs prediction sets that achieve the desired coverage rate while managing their size. We provide a theoretical analysis of the expected size of the conformal prediction sets based on the rank distribution of the underlying classifier. Through extensive experiments, we demonstrate that our method outperforms existing techniques on various datasets, providing reliable uncertainty quantification. Our contributions include a novel conformal prediction method, theoretical analysis, and empirical evaluation. This work advances the practical deployment of machine learning systems by enabling reliable uncertainty quantification.
Read more7/8/2024
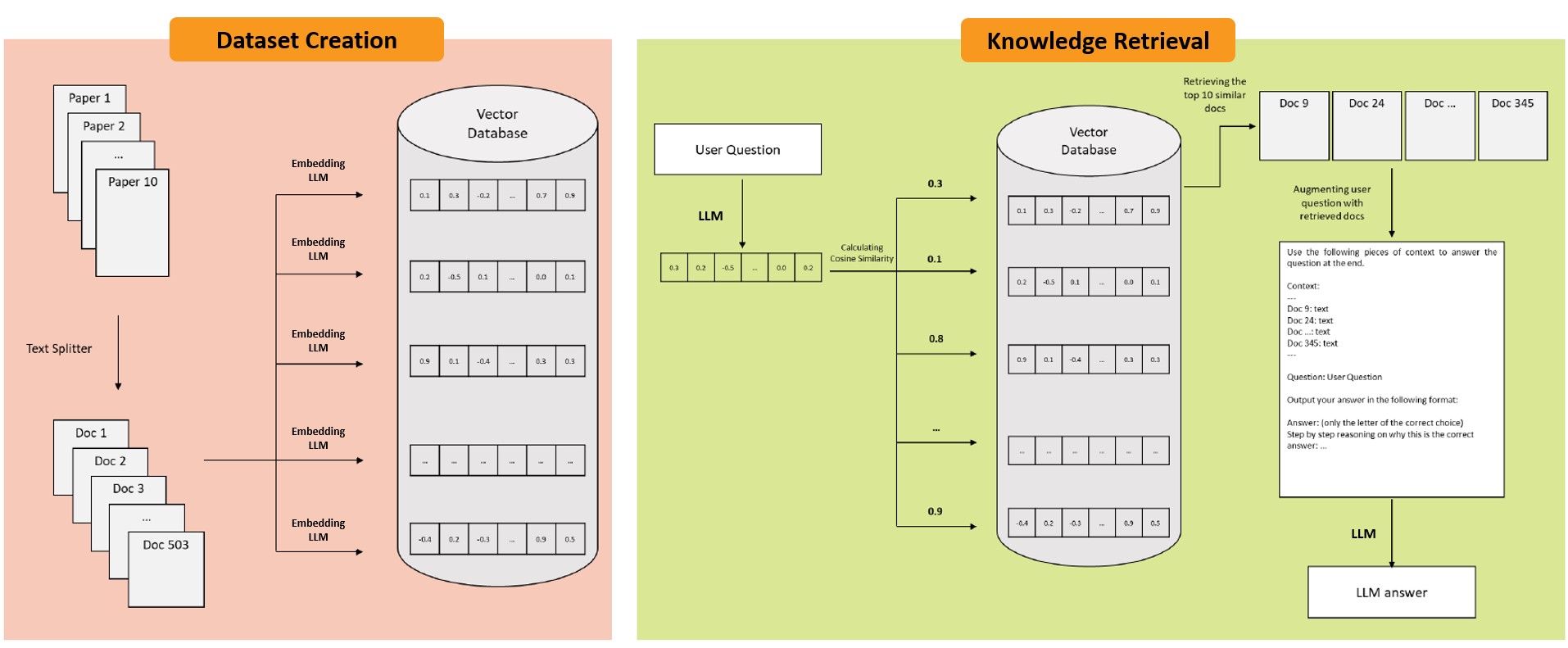
0
CONFLARE: CONFormal LArge language model REtrieval
Pouria Rouzrokh, Shahriar Faghani, Cooper U. Gamble, Moein Shariatnia, Bradley J. Erickson
Retrieval-augmented generation (RAG) frameworks enable large language models (LLMs) to retrieve relevant information from a knowledge base and incorporate it into the context for generating responses. This mitigates hallucinations and allows for the updating of knowledge without retraining the LLM. However, RAG does not guarantee valid responses if retrieval fails to identify the necessary information as the context for response generation. Also, if there is contradictory content, the RAG response will likely reflect only one of the two possible responses. Therefore, quantifying uncertainty in the retrieval process is crucial for ensuring RAG trustworthiness. In this report, we introduce a four-step framework for applying conformal prediction to quantify retrieval uncertainty in RAG frameworks. First, a calibration set of questions answerable from the knowledge base is constructed. Each question's embedding is compared against document embeddings to identify the most relevant document chunks containing the answer and record their similarity scores. Given a user-specified error rate ({alpha}), these similarity scores are then analyzed to determine a similarity score cutoff threshold. During inference, all chunks with similarity exceeding this threshold are retrieved to provide context to the LLM, ensuring the true answer is captured in the context with a (1-{alpha}) confidence level. We provide a Python package that enables users to implement the entire workflow proposed in our work, only using LLMs and without human intervention.
Read more4/9/2024