ConfusionPrompt: Practical Private Inference for Online Large Language Models
2401.00870
0
0

Abstract
State-of-the-art large language models (LLMs) are commonly deployed as online services, necessitating users to transmit informative prompts to cloud servers, thus engendering substantial privacy concerns. In response, we present ConfusionPrompt, a novel private LLM inference framework designed to obfuscate the server by: (i) decomposing the prompt into sub-prompts, and (ii) generating pseudo prompts along with the genuine sub-prompts as input to the online LLM. Eventually, the returned responses can be recomposed by the user to obtain the final whole response. Such designs endows our framework with advantages over previous protocols that (i) it can be seamlessly integrated with existing black-box LLMs, and (ii) it achieves significantly better privacy-utility trade-off than existing text perturbation-based methods. We develop a $(lambda, mu, rho)$-privacy model to formulate the requirement for a privacy-preserving group of prompts, and provide a complexity analysis, affirming ConfusionPrompt's efficiency. Our empirical evaluation reveals that our method offers significantly higher utility compared to local inference methods using open-source models and perturbation-based techniques, while also requiring much less memory than open-source LLMs.
Create account to get full access
Introduction
Main Contributions:
- The paper explores methods to teach large language models (LLMs) to "forget" private information, addressing the critical issue of privacy preservation in AI systems.
- It proposes several techniques, including prompt engineering for privacy preservation, prompting LLMs to synthesize outputs that avoid revealing private information, and locally differentially private context learning.
- The paper also discusses ways to extract prompts by inverting LLM outputs and the implications for personalized recommendation systems via prompting LLMs.
Plain English Explanation
The paper focuses on a critical issue in the development of large language models (LLMs) - preserving the privacy of individuals whose data is used to train these models. LLMs are AI systems that can generate human-like text, but they can also inadvertently reveal sensitive personal information about the people whose data was used to train them.
The researchers propose several techniques to address this problem. One approach is "prompt engineering" - carefully designing the prompts (or instructions) given to the LLM to avoid triggering the model to generate private information. Another technique is to prompt the LLM to synthesize outputs that actively avoid revealing private details.
The researchers also explore the use of "locally differentially private context learning," which involves training the LLM in a way that preserves the privacy of individual data points, rather than just the overall dataset.
Additionally, the paper discusses methods to "extract" the prompts that were used to generate certain LLM outputs, which could have implications for personalized recommendation systems that use prompting to tailor their outputs to individual users.
Technical Explanation
The paper presents several approaches to address the challenge of preserving privacy in large language models (LLMs). One key technique is "prompt engineering" - the process of carefully designing the prompts (or instructions) given to the LLM to avoid triggering the model to generate private information. The researchers demonstrate how prompts can be engineered to maintain the utility of the LLM while minimizing the risk of revealing sensitive personal data.
Another method explored in the paper is prompting LLMs to synthesize outputs that actively avoid revealing private details. By training the models to generate text that does not contain private information, the researchers aim to create LLMs that can be safely deployed in real-world applications.
The paper also investigates the use of "locally differentially private context learning," a approach that preserves the privacy of individual data points during the training process, rather than just the overall dataset. This technique helps to ensure that the LLM does not inadvertently memorize or reproduce sensitive information about the individuals whose data was used to train it.
Additionally, the researchers explore methods to "extract" the prompts that were used to generate certain LLM outputs. This could have implications for personalized recommendation systems that use prompting to tailor their outputs to individual users, as it may enable the reconstruction of personalized prompts from the model's outputs.
Critical Analysis
The paper presents a comprehensive and well-designed approach to addressing the critical issue of privacy preservation in large language models (LLMs). The researchers have identified several key challenges and proposed innovative solutions to address them.
One potential limitation of the paper is that it does not delve deeply into the practical implications and challenges of deploying these privacy-preserving techniques in real-world scenarios. The researchers acknowledge that there may be trade-offs between privacy and utility, and further research is needed to understand the practical implications of these techniques.
Additionally, the paper does not address the broader societal and ethical implications of the research. As LLMs become increasingly ubiquitous, it will be important to consider the potential for these models to be used in ways that could infringe on individual privacy, even with the proposed privacy-preserving techniques in place.
Overall, the paper represents a significant contribution to the field of AI safety and privacy, and the researchers have laid the groundwork for future work in this critical area.
Conclusion
The paper presents a range of techniques to teach large language models (LLMs) to "forget" private information, addressing a crucial issue in the development of AI systems. The proposed approaches, including prompt engineering, synthetic output generation, and locally differentially private context learning, offer promising avenues for preserving individual privacy while maintaining the utility of LLMs.
The research discussed in this paper has important implications for the responsible development and deployment of large language models, which are becoming increasingly ubiquitous in a wide range of applications. By addressing the privacy challenges head-on, the researchers are helping to pave the way for the safe and ethical use of these powerful AI systems.
As LLMs continue to evolve and become more integrated into our daily lives, ongoing research and development in the area of privacy preservation will be essential. The insights and techniques presented in this paper represent an important step forward in ensuring that the benefits of these technologies are realized while safeguarding the privacy and rights of individuals.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
LiveMind: Low-latency Large Language Models with Simultaneous Inference
Chuangtao Chen, Grace Li Zhang, Xunzhao Yin, Cheng Zhuo, Ulf Schlichtmann, Bing Li
0
0
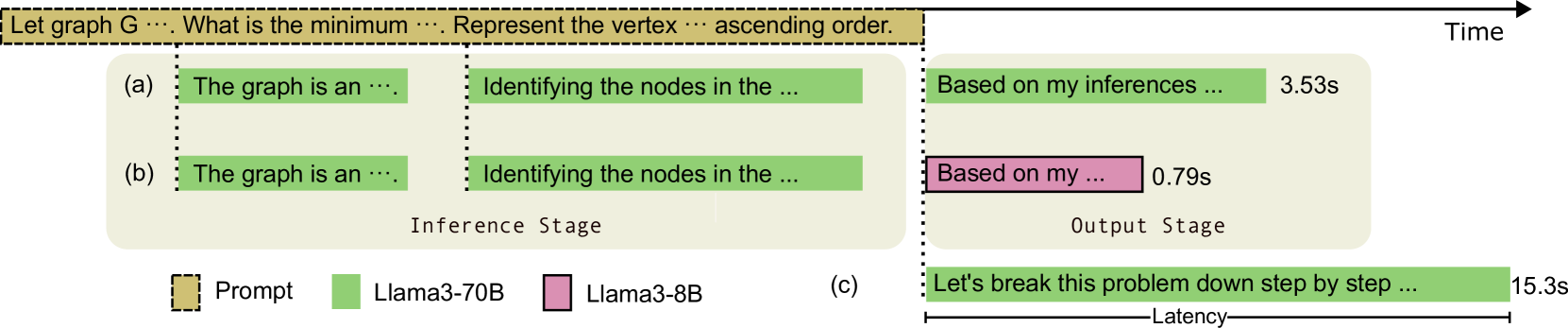
In this paper, we introduce a novel low-latency inference framework for large language models (LLMs) inference which enables LLMs to perform inferences with incomplete prompts. By reallocating computational processes to prompt input phase, we achieve a substantial reduction in latency, thereby significantly enhancing the interactive experience for users of LLMs. The framework adeptly manages the visibility of the streaming prompt to the model, allowing it to infer from incomplete prompts or await additional prompts. Compared with traditional inference methods that utilize complete prompts, our approach demonstrates an average reduction of 59% in response latency on the MMLU-Pro dataset, while maintaining comparable accuracy. Additionally, our framework facilitates collaborative inference and output across different models. By employing an LLM for inference and a small language model (SLM) for output, we achieve an average 68% reduction in response latency, alongside a 5.5% improvement in accuracy on the MMLU-Pro dataset compared with the SLM baseline. For long prompts exceeding 20 sentences, the response latency can be reduced by up to 93%.
6/21/2024
Privacy Preserving Prompt Engineering: A Survey
Kennedy Edemacu, Xintao Wu
0
0
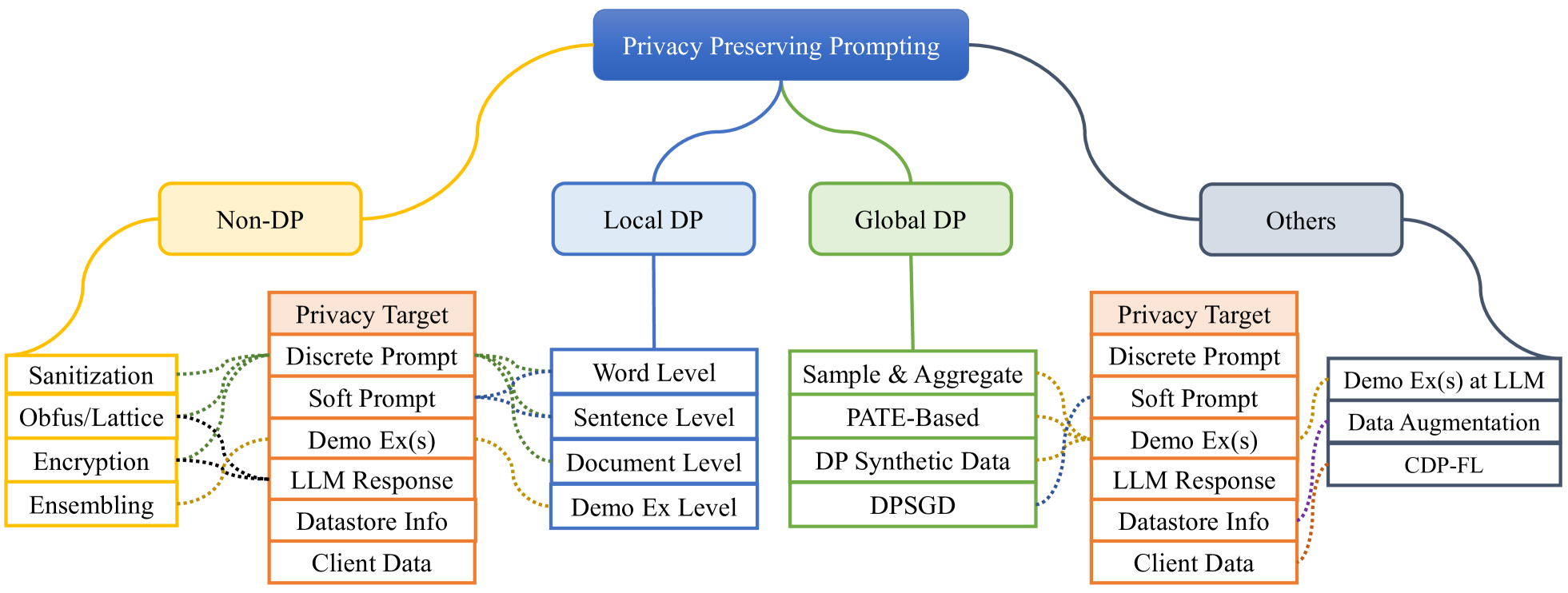
Pre-trained language models (PLMs) have demonstrated significant proficiency in solving a wide range of general natural language processing (NLP) tasks. Researchers have observed a direct correlation between the performance of these models and their sizes. As a result, the sizes of these models have notably expanded in recent years, persuading researchers to adopt the term large language models (LLMs) to characterize the larger-sized PLMs. The size expansion comes with a distinct capability called in-context learning (ICL), which represents a special form of prompting and allows the models to be utilized through the presentation of demonstration examples without modifications to the model parameters. Although interesting, privacy concerns have become a major obstacle in its widespread usage. Multiple studies have examined the privacy risks linked to ICL and prompting in general, and have devised techniques to alleviate these risks. Thus, there is a necessity to organize these mitigation techniques for the benefit of the community. This survey provides a systematic overview of the privacy protection methods employed during ICL and prompting in general. We review, analyze, and compare different methods under this paradigm. Furthermore, we provide a summary of the resources accessible for the development of these frameworks. Finally, we discuss the limitations of these frameworks and offer a detailed examination of the promising areas that necessitate further exploration.
4/12/2024
Prompt Public Large Language Models to Synthesize Data for Private On-device Applications
Shanshan Wu, Zheng Xu, Yanxiang Zhang, Yuanbo Zhang, Daniel Ramage
0
0
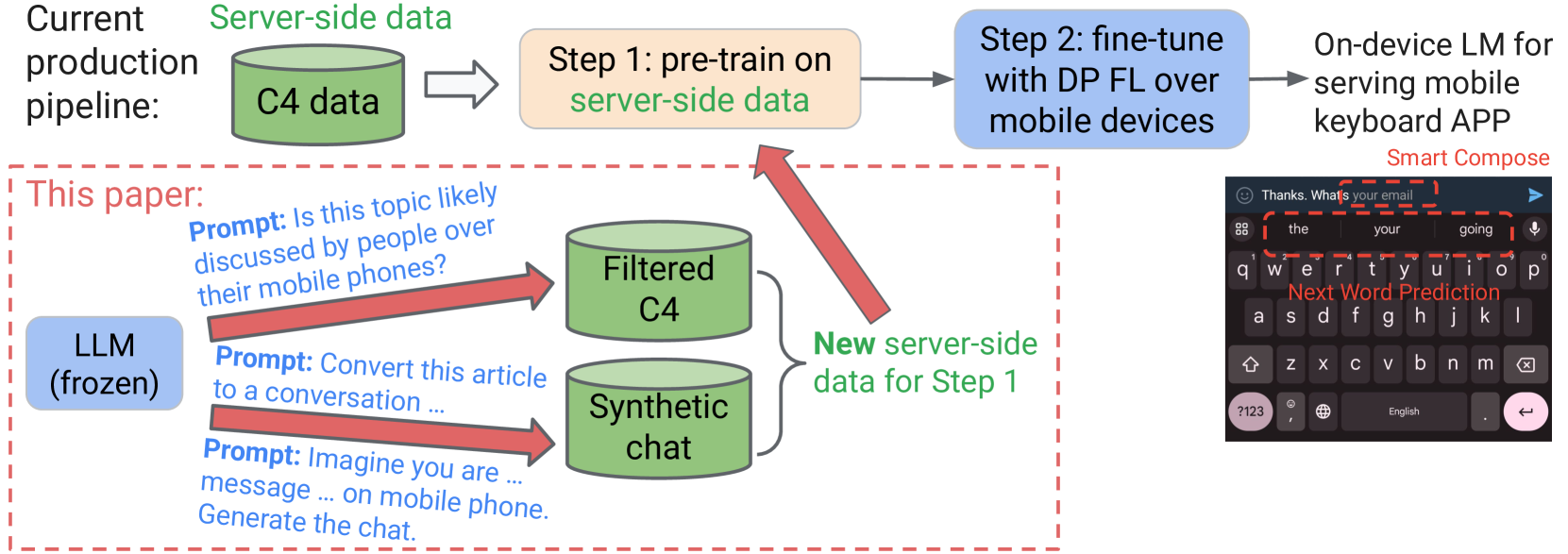
Pre-training on public data is an effective method to improve the performance for federated learning (FL) with differential privacy (DP). This paper investigates how large language models (LLMs) trained on public data can improve the quality of pre-training data for the on-device language models trained with DP and FL. We carefully design LLM prompts to filter and transform existing public data, and generate new data to resemble the real user data distribution. The model pre-trained on our synthetic dataset achieves relative improvement of 19.0% and 22.8% in next word prediction accuracy compared to the baseline model pre-trained on a standard public dataset, when evaluated over the real user data in Gboard (Google Keyboard, a production mobile keyboard application). Furthermore, our method achieves evaluation accuracy better than or comparable to the baseline during the DP FL fine-tuning over millions of mobile devices, and our final model outperforms the baseline in production A/B testing. Our experiments demonstrate the strengths of LLMs in synthesizing data close to the private distribution even without accessing the private data, and also suggest future research directions to further reduce the distribution gap.
4/9/2024

RePrompt: Planning by Automatic Prompt Engineering for Large Language Models Agents
Weizhe Chen, Sven Koenig, Bistra Dilkina
0
0
In this past year, large language models (LLMs) have had remarkable success in domains outside the traditional natural language processing, and people are starting to explore the usage of LLMs in more general and close to application domains like code generation, travel planning, and robot controls. Connecting these LLMs with great capacity and external tools, people are building the so-called LLM agents, which are supposed to help people do all kinds of work in everyday life. In all these domains, the prompt to the LLMs has been shown to make a big difference in what the LLM would generate and thus affect the performance of the LLM agents. Therefore, automatic prompt engineering has become an important question for many researchers and users of LLMs. In this paper, we propose a novel method, textsc{RePrompt}, which does gradient descent to optimize the step-by-step instructions in the prompt of the LLM agents based on the chat history obtained from interactions with LLM agents. By optimizing the prompt, the LLM will learn how to plan in specific domains. We have used experiments in PDDL generation and travel planning to show that our method could generally improve the performance for different reasoning tasks when using the updated prompt as the initial prompt.
6/18/2024