Prompt Public Large Language Models to Synthesize Data for Private On-device Applications
2404.04360
0
0
Abstract
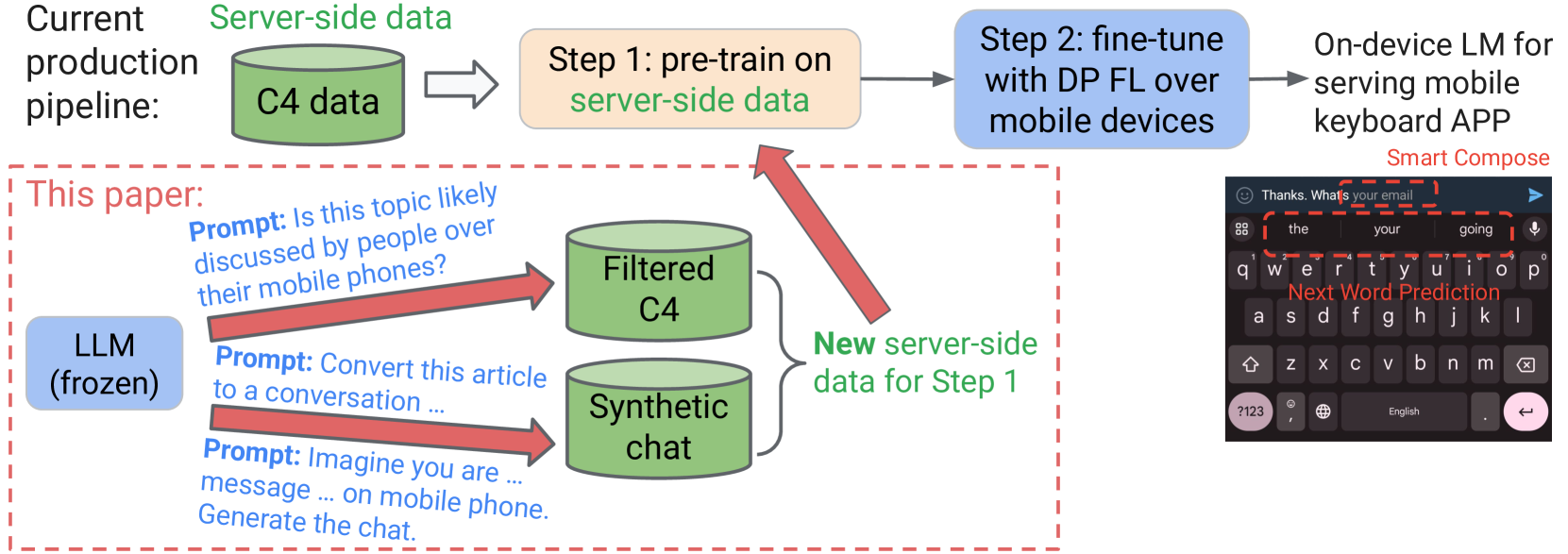
Pre-training on public data is an effective method to improve the performance for federated learning (FL) with differential privacy (DP). This paper investigates how large language models (LLMs) trained on public data can improve the quality of pre-training data for the on-device language models trained with DP and FL. We carefully design LLM prompts to filter and transform existing public data, and generate new data to resemble the real user data distribution. The model pre-trained on our synthetic dataset achieves relative improvement of 19.0% and 22.8% in next word prediction accuracy compared to the baseline model pre-trained on a standard public dataset, when evaluated over the real user data in Gboard (Google Keyboard, a production mobile keyboard application). Furthermore, our method achieves evaluation accuracy better than or comparable to the baseline during the DP FL fine-tuning over millions of mobile devices, and our final model outperforms the baseline in production A/B testing. Our experiments demonstrate the strengths of LLMs in synthesizing data close to the private distribution even without accessing the private data, and also suggest future research directions to further reduce the distribution gap.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores a novel approach to synthesizing private-like data using publicly available large language models (LLMs).
- The proposed method allows developers to leverage the capabilities of LLMs to generate synthetic data that mimics the characteristics of sensitive, private data.
- This can enable the development of private on-device applications without the need for accessing or storing actual private user data.
Plain English Explanation
The researchers in this paper have come up with a way to use powerful language models that are publicly available to create fake data that looks and behaves a lot like real private user data. The goal is to allow developers to build applications that can work with this synthetic data, instead of having to use actual private information from users.
This is important because many useful applications require access to people's private data, like their personal messages, search history, or location information. But collecting and storing that kind of sensitive data raises a lot of privacy concerns. By generating fake data that has similar properties, developers can test and train their apps without needing to touch the real private data.
The key insight here is that large language models, which are trained on huge amounts of online text, can be prompted or instructed to produce content that mimics the patterns and characteristics of real private data. So instead of accessing users' private information directly, developers can leverage these language models to create synthetic stand-ins that preserve the essential properties needed for their application, while keeping the actual private data safe.
Technical Explanation
The paper proposes a method for prompting publicly available LLMs, such as GPT-3, to synthesize private-like data that can be used for developing on-device applications. The approach involves crafting prompts that guide the LLM to generate content mimicking the statistical and semantic characteristics of sensitive user data, without actually requiring access to that private information.
The authors demonstrate this technique across several data modalities, including text, images, and tabular data. For example, they show how an LLM can be prompted to produce synthetic chat messages that preserve key properties like language style, sentiment, and conversational flow, without recreating actual private conversations.
Importantly, the researchers also explore techniques for evaluating the fidelity of the synthetic data, ensuring it maintains the desired private-like qualities while avoiding the leakage of real private information. This includes novel metrics for measuring statistical similarity as well as human evaluations.
Overall, the paper presents a promising approach for leveraging public LLMs to enable the development of private on-device applications without the need for accessing or storing users' actual sensitive data.
Critical Analysis
The research raises several important considerations. While the proposed method can generate synthetic data that preserves key properties of private information, there may still be challenges around the trustworthiness of the generated content. The authors acknowledge that their evaluation metrics do not fully capture all aspects of private data fidelity, and there may be subtle differences that could impact the viability of using the synthetic data in real-world applications.
Additionally, the potential for language model biases to be reflected in the generated synthetic data is an important consideration that warrants further investigation. Developers would need to carefully assess the suitability and limitations of the synthetic data for their specific use cases.
Overall, the research presents a compelling approach to addressing the privacy challenges associated with developing applications that leverage sensitive user data. While more work is needed to fully validate the techniques, the ability to generate private-like data using public LLMs is a significant step forward in enabling the responsible development of privacy-preserving applications.
Conclusion
This paper introduces a novel method for using publicly available large language models to synthesize private-like data that can be used for developing on-device applications. By crafting prompts that guide the language models to generate content mimicking the characteristics of sensitive user data, the researchers have demonstrated a promising approach to enabling private application development without the need for accessing or storing actual private information.
While further research is needed to fully validate the trustworthiness and limitations of the synthetic data, this work represents an important advancement in the field of privacy-preserving machine learning. By leveraging the capabilities of public language models, developers can now explore new avenues for building useful applications that respect user privacy and avoid the risks associated with handling sensitive personal data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Can Public Large Language Models Help Private Cross-device Federated Learning?
Boxin Wang, Yibo Jacky Zhang, Yuan Cao, Bo Li, H. Brendan McMahan, Sewoong Oh, Zheng Xu, Manzil Zaheer
0
0
We study (differentially) private federated learning (FL) of language models. The language models in cross-device FL are relatively small, which can be trained with meaningful formal user-level differential privacy (DP) guarantees when massive parallelism in training is enabled by the participation of a moderate size of users. Recently, public data has been used to improve privacy-utility trade-offs for both large and small language models. In this work, we provide a systematic study of using large-scale public data and LLMs to help differentially private training of on-device FL models, and further improve the privacy-utility tradeoff by techniques of distillation. Moreover, we propose a novel distribution matching algorithm with theoretical grounding to sample public data close to private data distribution, which significantly improves the sample efficiency of (pre-)training on public data. The proposed method is efficient and effective for training private models by taking advantage of public data, especially for customized on-device architectures that do not have ready-to-use pre-trained models.
4/16/2024
Group-wise Prompting for Synthetic Tabular Data Generation using Large Language Models
Jinhee Kim, Taesung Kim, Jaegul Choo
0
0
Generating realistic synthetic tabular data presents a critical challenge in machine learning. This study introduces a simple yet effective method employing Large Language Models (LLMs) tailored to generate synthetic data, specifically addressing data imbalance problems. We propose a novel group-wise prompting method in CSV-style formatting that leverages the in-context learning capabilities of LLMs to produce data that closely adheres to the specified requirements and characteristics of the target dataset. Moreover, our proposed random word replacement strategy significantly improves the handling of monotonous categorical values, enhancing the accuracy and representativeness of the synthetic data. The effectiveness of our method is extensively validated across eight real-world public datasets, achieving state-of-the-art performance in downstream classification and regression tasks while maintaining inter-feature correlations and improving token efficiency over existing approaches. This advancement significantly contributes to addressing the key challenges of machine learning applications, particularly in the context of tabular data generation and handling class imbalance. The source code for our work is available at: https://github.com/seharanul17/synthetic-tabular-LLM
4/22/2024
Privacy Preserving Prompt Engineering: A Survey
Kennedy Edemacu, Xintao Wu
0
0
Pre-trained language models (PLMs) have demonstrated significant proficiency in solving a wide range of general natural language processing (NLP) tasks. Researchers have observed a direct correlation between the performance of these models and their sizes. As a result, the sizes of these models have notably expanded in recent years, persuading researchers to adopt the term large language models (LLMs) to characterize the larger-sized PLMs. The size expansion comes with a distinct capability called in-context learning (ICL), which represents a special form of prompting and allows the models to be utilized through the presentation of demonstration examples without modifications to the model parameters. Although interesting, privacy concerns have become a major obstacle in its widespread usage. Multiple studies have examined the privacy risks linked to ICL and prompting in general, and have devised techniques to alleviate these risks. Thus, there is a necessity to organize these mitigation techniques for the benefit of the community. This survey provides a systematic overview of the privacy protection methods employed during ICL and prompting in general. We review, analyze, and compare different methods under this paradigm. Furthermore, we provide a summary of the resources accessible for the development of these frameworks. Finally, we discuss the limitations of these frameworks and offer a detailed examination of the promising areas that necessitate further exploration.
4/12/2024
💬
Utilizing Large Language Models to Generate Synthetic Data to Increase the Performance of BERT-Based Neural Networks
Chancellor R. Woolsey, Prakash Bisht, Joshua Rothman, Gondy Leroy
0
0
An important issue impacting healthcare is a lack of available experts. Machine learning (ML) models could resolve this by aiding in diagnosing patients. However, creating datasets large enough to train these models is expensive. We evaluated large language models (LLMs) for data creation. Using Autism Spectrum Disorders (ASD), we prompted ChatGPT and GPT-Premium to generate 4,200 synthetic observations to augment existing medical data. Our goal is to label behaviors corresponding to autism criteria and improve model accuracy with synthetic training data. We used a BERT classifier pre-trained on biomedical literature to assess differences in performance between models. A random sample (N=140) from the LLM-generated data was evaluated by a clinician and found to contain 83% correct example-label pairs. Augmenting data increased recall by 13% but decreased precision by 16%, correlating with higher quality and lower accuracy across pairs. Future work will analyze how different synthetic data traits affect ML outcomes.
5/14/2024