LiveMind: Low-latency Large Language Models with Simultaneous Inference
2406.14319
0
0
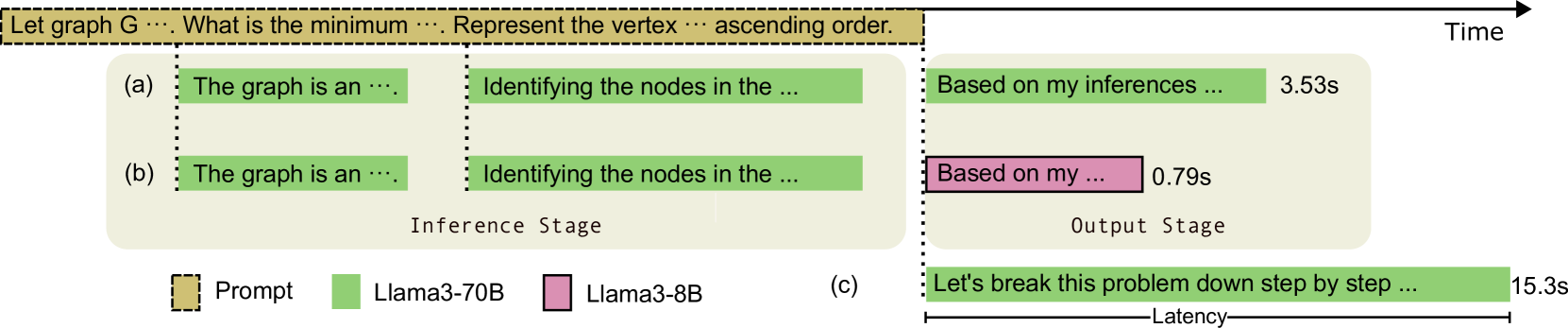
Abstract
In this paper, we introduce a novel low-latency inference framework for large language models (LLMs) inference which enables LLMs to perform inferences with incomplete prompts. By reallocating computational processes to prompt input phase, we achieve a substantial reduction in latency, thereby significantly enhancing the interactive experience for users of LLMs. The framework adeptly manages the visibility of the streaming prompt to the model, allowing it to infer from incomplete prompts or await additional prompts. Compared with traditional inference methods that utilize complete prompts, our approach demonstrates an average reduction of 59% in response latency on the MMLU-Pro dataset, while maintaining comparable accuracy. Additionally, our framework facilitates collaborative inference and output across different models. By employing an LLM for inference and a small language model (SLM) for output, we achieve an average 68% reduction in response latency, alongside a 5.5% improvement in accuracy on the MMLU-Pro dataset compared with the SLM baseline. For long prompts exceeding 20 sentences, the response latency can be reduced by up to 93%.
Create account to get full access
Overview
• This paper introduces LiveMind, a system that enables low-latency inference with large language models (LLMs) by using simultaneous inference techniques.
• The key idea is to split the input text into smaller chunks and process them concurrently, rather than waiting for the entire input to be available before starting inference.
• This approach reduces the end-to-end latency of LLM inference, making it more suitable for real-time applications like conversational simulmt, parallel generation of text and speech, and others.
Plain English Explanation
Large language models (LLMs) like GPT-3 have become powerful tools for a variety of natural language processing tasks. However, the computational cost of running these models can be high, leading to long latency periods between when a user submits a request and when the model generates a response.
The LiveMind system aims to address this issue by using a technique called "simultaneous inference." Instead of waiting for the entire input text to be available before starting the inference process, LiveMind splits the text into smaller chunks and processes them concurrently. This allows the system to start generating a response much faster, reducing the overall latency experienced by the user.
Imagine you're talking to a virtual assistant and asking it a complex question. With traditional LLM inference, the assistant would need to wait until you finished speaking before it could start processing your request. With LiveMind, the assistant could start analyzing the first part of your question as you're still speaking, allowing it to provide a quicker response.
This low-latency inference capability makes LiveMind a promising approach for real-time applications that rely on large language models, such as conversational simultaneous translation, parallel generation of text and speech, and others.
Technical Explanation
The key technical innovation in LiveMind is the use of "simultaneous inference," which involves breaking up the input text into smaller chunks and processing them concurrently. This is in contrast to the traditional approach, where the entire input is processed sequentially.
To achieve this, LiveMind employs a specialized architecture that includes a text chunker, a parallelized inference engine, and a response aggregator. The text chunker divides the input text into manageable segments, the parallelized inference engine processes these chunks simultaneously, and the response aggregator combines the individual outputs into a coherent final response.
The researchers conducted experiments to evaluate the performance of LiveMind, comparing it to a baseline sequential inference approach. They found that LiveMind was able to achieve significant reductions in end-to-end latency, with only a modest increase in computational cost. This suggests that the benefits of lower latency outweigh the additional resource requirements.
Critical Analysis
The paper presents a compelling approach to addressing the latency challenges associated with large language models. By leveraging simultaneous inference, LiveMind is able to provide faster responses, which is particularly important for real-time applications.
However, the paper does not discuss the potential impact of this approach on the accuracy or quality of the model's outputs. It would be important to understand if the concurrent processing of text chunks introduces any degradation in the coherence or semantics of the final response.
Additionally, the paper does not explore the scalability of the LiveMind approach as the size and complexity of the language model increases. It is possible that the performance benefits may diminish or the computational overhead may become more significant as the model grows larger.
Further research could also investigate the integration of LiveMind with other techniques, such as knowledge-enhanced language models or query-aware inference acceleration, to achieve even greater improvements in latency and overall system performance.
Conclusion
The LiveMind system represents an important step forward in enabling low-latency inference with large language models. By leveraging simultaneous inference techniques, LiveMind is able to significantly reduce the end-to-end latency experienced by users, making LLMs more suitable for real-time applications.
This innovation has the potential to unlock new use cases and applications for large language models, particularly in areas where quick responses are critical, such as conversational simultaneous translation, parallel generation of text and speech, and practical private inference. As the field of natural language processing continues to evolve, techniques like LiveMind will play an increasingly important role in making these powerful models more accessible and useful in real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

ConfusionPrompt: Practical Private Inference for Online Large Language Models
Peihua Mai, Ran Yan, Rui Ye, Youjia Yang, Yinchuan Li, Yan Pang
0
0
State-of-the-art large language models (LLMs) are commonly deployed as online services, necessitating users to transmit informative prompts to cloud servers, thus engendering substantial privacy concerns. In response, we present ConfusionPrompt, a novel private LLM inference framework designed to obfuscate the server by: (i) decomposing the prompt into sub-prompts, and (ii) generating pseudo prompts along with the genuine sub-prompts as input to the online LLM. Eventually, the returned responses can be recomposed by the user to obtain the final whole response. Such designs endows our framework with advantages over previous protocols that (i) it can be seamlessly integrated with existing black-box LLMs, and (ii) it achieves significantly better privacy-utility trade-off than existing text perturbation-based methods. We develop a $(lambda, mu, rho)$-privacy model to formulate the requirement for a privacy-preserving group of prompts, and provide a complexity analysis, affirming ConfusionPrompt's efficiency. Our empirical evaluation reveals that our method offers significantly higher utility compared to local inference methods using open-source models and perturbation-based techniques, while also requiring much less memory than open-source LLMs.
5/27/2024
💬
Conversational SimulMT: Efficient Simultaneous Translation with Large Language Models
Minghan Wang, Thuy-Trang Vu, Yuxia Wang, Ehsan Shareghi, Gholamreza Haffari
0
0
Simultaneous machine translation (SimulMT) presents a challenging trade-off between translation quality and latency. Recent studies have shown that LLMs can achieve good performance in SimulMT tasks. However, this often comes at the expense of high inference cost and latency. In this paper, we propose a conversational SimulMT framework to enhance the inference efficiency of LLM-based SimulMT through multi-turn-dialogue-based decoding. Our experiments with Llama2-7b-chat on two SimulMT benchmarks demonstrate the superiority of LLM in translation quality while achieving comparable computational latency to specialized SimulMT models.
6/24/2024

Supervised Knowledge Makes Large Language Models Better In-context Learners
Linyi Yang, Shuibai Zhang, Zhuohao Yu, Guangsheng Bao, Yidong Wang, Jindong Wang, Ruochen Xu, Wei Ye, Xing Xie, Weizhu Chen, Yue Zhang
0
0
Large Language Models (LLMs) exhibit emerging in-context learning abilities through prompt engineering. The recent progress in large-scale generative models has further expanded their use in real-world language applications. However, the critical challenge of improving the generalizability and factuality of LLMs in natural language understanding and question answering remains under-explored. While previous in-context learning research has focused on enhancing models to adhere to users' specific instructions and quality expectations, and to avoid undesired outputs, little to no work has explored the use of task-Specific fine-tuned Language Models (SLMs) to improve LLMs' in-context learning during the inference stage. Our primary contribution is the establishment of a simple yet effective framework that enhances the reliability of LLMs as it: 1) generalizes out-of-distribution data, 2) elucidates how LLMs benefit from discriminative models, and 3) minimizes hallucinations in generative tasks. Using our proposed plug-in method, enhanced versions of Llama 2 and ChatGPT surpass their original versions regarding generalizability and factuality. We offer a comprehensive suite of resources, including 16 curated datasets, prompts, model checkpoints, and LLM outputs across 9 distinct tasks. The code and data are released at: https://github.com/YangLinyi/Supervised-Knowledge-Makes-Large-Language-Models-Better-In-context-Learners. Our empirical analysis sheds light on the advantages of incorporating discriminative models into LLMs and highlights the potential of our methodology in fostering more reliable LLMs.
4/12/2024

QuickLLaMA: Query-aware Inference Acceleration for Large Language Models
Jingyao Li, Han Shi, Xin Jiang, Zhenguo Li, Hong Xu, Jiaya Jia
0
0
The capacity of Large Language Models (LLMs) to comprehend and reason over long contexts is pivotal for advancements in diverse fields. Yet, they still stuggle with capturing long-distance dependencies within sequences to deeply understand semantics. To address this issue, we introduce Query-aware Inference for LLMs (Q-LLM), a system designed to process extensive sequences akin to human cognition. By focusing on memory data relevant to a given query, Q-LLM can accurately capture pertinent information within a fixed window size and provide precise answers to queries. It doesn't require extra training and can be seamlessly integrated with any LLMs. Q-LLM using LLaMA3 (QuickLLaMA) can read Harry Potter within 30s and accurately answer the questions. Q-LLM improved by 7.17% compared to the current state-of-the-art on LLaMA3, and by 3.26% on Mistral on the $infty$-bench. In the Needle-in-a-Haystack task, On widely recognized benchmarks, Q-LLM improved upon the current SOTA by 7.0% on Mistral and achieves 100% on LLaMA3. Our code can be found in https://github.com/dvlab-research/Q-LLM.
6/12/2024