Connected Speech-Based Cognitive Assessment in Chinese and English

0
Sign in to get full access
Overview
- This paper explores the use of connected speech analysis for cognitive assessment in both Chinese and English languages.
- The researchers investigate the potential of using speech-based features to detect cognitive impairment across different languages.
- The study aims to provide insights into the cognitive insights across languages and enhance the speech-based clinical depression screening.
Plain English Explanation
The paper examines how analyzing a person's connected speech, or the way they speak in a continuous, natural conversation, can be used to assess their cognitive abilities. The researchers looked at this in both Chinese and English, to see if the same speech-based techniques could be applied across different languages.
The goal was to find ways to detect potential cognitive impairment, such as early signs of dementia or other neurological conditions, by examining features of a person's speech pattern. This could provide a zero-shot multi-lingual speaker verification approach for clinical assessments.
The researchers wanted to build on previous work that has shown speech analysis can be a useful tool for evaluating mental health and cognition. By exploring how these techniques perform across languages, they aimed to develop a more comprehensive evaluation framework for assessing cognitive function through speech.
Technical Explanation
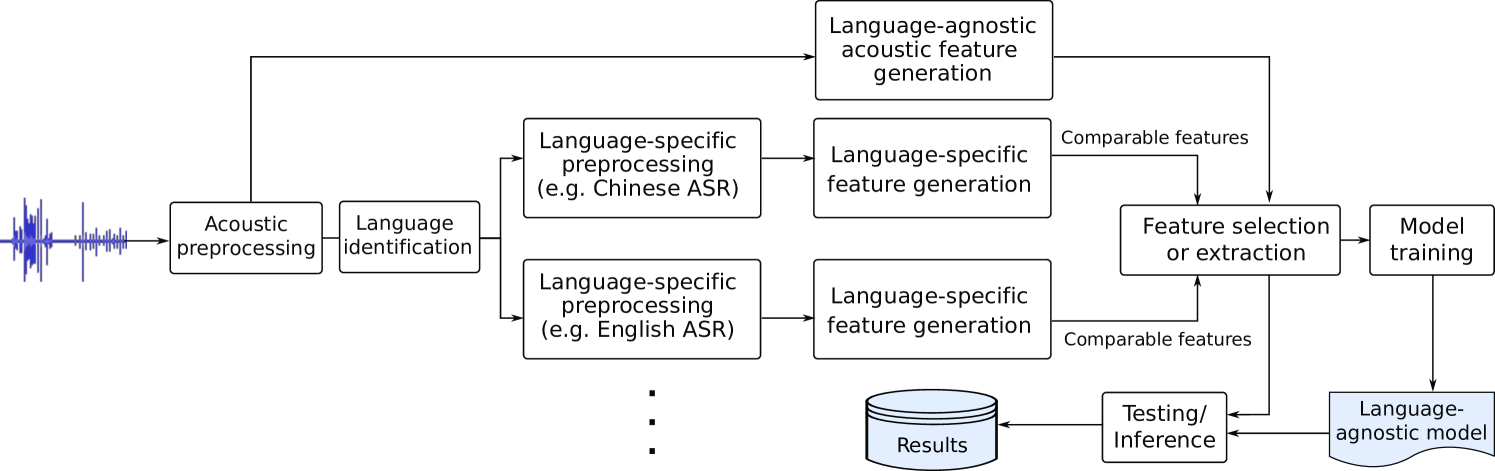
The study used connected speech samples collected from both Chinese and English speakers. The researchers extracted various acoustic, linguistic, and temporal features from the speech data to capture different aspects of the speakers' cognitive abilities.
They then trained machine learning models to analyze these speech-based features and assess the speakers' cognitive performance. The models were evaluated on their ability to accurately detect signs of cognitive impairment in the speech samples.
The results showed that the speech-based approach was effective in both Chinese and English, demonstrating the potential for a multi-lingual cognitive assessment tool. The researchers found that certain speech features, such as pause patterns and lexical diversity, were particularly informative in identifying cognitive impairment across the two languages.
Critical Analysis
The paper provides a valuable contribution to the field of speech-based cognitive assessment, but it also acknowledges several limitations and areas for further research. For example, the study was conducted with a relatively small sample size, and the researchers suggest that larger, more diverse datasets should be explored in the future.
Additionally, the paper does not delve deeply into the specific mechanisms by which speech patterns are linked to cognitive functioning. More research is needed to understand the precise cognitive processes and neural correlates that underlie the observed speech-based markers of impairment.
It would also be interesting to see how the speech-based approach compares to or complements other modalities, such as neuropsychological testing or neuroimaging data, in assessing cognitive abilities across languages.
Conclusion
This study showcases the potential of using connected speech analysis for cognitive assessment in both Chinese and English. By demonstrating the feasibility of this approach across languages, the researchers have taken an important step towards developing a more comprehensive and accessible assessment framework for detecting early signs of cognitive decline.
The findings have important implications for clinical practice, as this type of speech-based assessment could provide a non-invasive, zero-shot multi-lingual speaker verification tool for monitoring cognitive health. Further research in this area has the potential to enhance our understanding of speech-based clinical depression screening and cognitive insights across languages, ultimately leading to improved early detection and intervention for cognitive impairment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Connected Speech-Based Cognitive Assessment in Chinese and English
Saturnino Luz, Sofia De La Fuente Garcia, Fasih Haider, Davida Fromm, Brian MacWhinney, Alyssa Lanzi, Ya-Ning Chang, Chia-Ju Chou, Yi-Chien Liu
We present a novel benchmark dataset and prediction tasks for investigating approaches to assess cognitive function through analysis of connected speech. The dataset consists of speech samples and clinical information for speakers of Mandarin Chinese and English with different levels of cognitive impairment as well as individuals with normal cognition. These data have been carefully matched by age and sex by propensity score analysis to ensure balance and representativity in model training. The prediction tasks encompass mild cognitive impairment diagnosis and cognitive test score prediction. This framework was designed to encourage the development of approaches to speech-based cognitive assessment which generalise across languages. We illustrate it by presenting baseline prediction models that employ language-agnostic and comparable features for diagnosis and cognitive test score prediction. The models achieved unweighted average recall was 59.2% in diagnosis, and root mean squared error of 2.89 in score prediction.
Read more6/19/2024

0
CogniVoice: Multimodal and Multilingual Fusion Networks for Mild Cognitive Impairment Assessment from Spontaneous Speech
Jiali Cheng, Mohamed Elgaar, Nidhi Vakil, Hadi Amiri
Mild Cognitive Impairment (MCI) is a medical condition characterized by noticeable declines in memory and cognitive abilities, potentially affecting individual's daily activities. In this paper, we introduce CogniVoice, a novel multilingual and multimodal framework to detect MCI and estimate Mini-Mental State Examination (MMSE) scores by analyzing speech data and its textual transcriptions. The key component of CogniVoice is an ensemble multimodal and multilingual network based on ``Product of Experts'' that mitigates reliance on shortcut solutions. Using a comprehensive dataset containing both English and Chinese languages from TAUKADIAL challenge, CogniVoice outperforms the best performing baseline model on MCI classification and MMSE regression tasks by 2.8 and 4.1 points in F1 and RMSE respectively, and can effectively reduce the performance gap across different language groups by 0.7 points in F1.
Read more7/19/2024

0
Pronunciation Assessment with Multi-modal Large Language Models
Kaiqi Fu, Linkai Peng, Nan Yang, Shuran Zhou
Large language models (LLMs), renowned for their powerful conversational abilities, are widely recognized as exceptional tools in the field of education, particularly in the context of automated intelligent instruction systems for language learning. In this paper, we propose a scoring system based on LLMs, motivated by their positive impact on text-related scoring tasks. Specifically, the speech encoder first maps the learner's speech into contextual features. The adapter layer then transforms these features to align with the text embedding in latent space. The assessment task-specific prefix and prompt text are embedded and concatenated with the features generated by the modality adapter layer, enabling the LLMs to predict accuracy and fluency scores. Our experiments demonstrate that the proposed scoring systems achieve competitive results compared to the baselines on the Speechocean762 datasets. Moreover, we also conducted an ablation study to better understand the contributions of the prompt text and training strategy in the proposed scoring system.
Read more7/19/2024
👨🏫
0
Supervised Learning and Large Language Model Benchmarks on Mental Health Datasets: Cognitive Distortions and Suicidal Risks in Chinese Social Media
Hongzhi Qi, Qing Zhao, Jianqiang Li, Changwei Song, Wei Zhai, Dan Luo, Shuo Liu, Yi Jing Yu, Fan Wang, Huijing Zou, Bing Xiang Yang, Guanghui Fu
On social media, users often express their personal feelings, which may exhibit cognitive distortions or even suicidal tendencies on certain specific topics. Early recognition of these signs is critical for effective psychological intervention. In this paper, we introduce two novel datasets from Chinese social media: SOS-HL-1K for suicidal risk classification and SocialCD-3K for cognitive distortions detection. The SOS-HL-1K dataset contained 1,249 posts and SocialCD-3K dataset was a multi-label classification dataset that containing 3,407 posts. We propose a comprehensive evaluation using two supervised learning methods and eight large language models (LLMs) on the proposed datasets. From the prompt engineering perspective, we experimented with two types of prompt strategies, including four zero-shot and five few-shot strategies. We also evaluated the performance of the LLMs after fine-tuning on the proposed tasks. The experimental results show that there is still a huge gap between LLMs relying only on prompt engineering and supervised learning. In the suicide classification task, this gap is 6.95% points in F1-score, while in the cognitive distortion task, the gap is even more pronounced, reaching 31.53% points in F1-score. However, after fine-tuning, this difference is significantly reduced. In the suicide and cognitive distortion classification tasks, the gap decreases to 4.31% and 3.14%, respectively. This research highlights the potential of LLMs in psychological contexts, but supervised learning remains necessary for more challenging tasks. All datasets and code are made available.
Read more6/11/2024