Conservative DDPG -- Pessimistic RL without Ensemble

0

Sign in to get full access
Overview
- The paper proposes a new reinforcement learning algorithm called Conservative DDPG (C-DDPG) that addresses the overestimation bias problem in Deep Deterministic Policy Gradient (DDPG).
- C-DDPG uses a pessimistic approach to value estimation, avoiding the need for an ensemble of models as in prior methods.
- The algorithm is evaluated on several continuous control tasks and shows improved performance and stability compared to standard DDPG.
Plain English Explanation
Reinforcement learning is a type of machine learning where an agent learns to make good decisions by interacting with an environment and receiving rewards or penalties. One popular reinforcement learning algorithm is Deep Deterministic Policy Gradient (DDPG), which has been successfully applied to many control problems.
However, DDPG suffers from a problem called "overestimation bias", where the agent's estimate of the value of taking an action tends to be higher than the true value. This can lead to the agent making suboptimal decisions.
The Conservative DDPG (C-DDPG) algorithm proposed in this paper aims to address this issue. Instead of trying to estimate the true value accurately, C-DDPG takes a "pessimistic" approach and estimates a lower bound on the true value. This helps the agent avoid taking actions that seem better than they really are.
Compared to previous methods that used an ensemble of models to address overestimation bias, C-DDPG achieves similar performance without the added complexity of maintaining multiple models. The researchers evaluate C-DDPG on several continuous control tasks and show that it outperforms standard DDPG in terms of both performance and stability.
Technical Explanation
The key idea behind Conservative DDPG (C-DDPG) is to modify the DDPG algorithm to use a lower bound on the expected return as the target for the critic network, rather than the actual expected return.
Specifically, the authors propose the following changes to the standard DDPG update rules:
- Critic Update: Instead of using the standard Bellman update, the critic network is trained to minimize the difference between its output and a lower bound on the expected return, computed using a pessimistic value function.
- Actor Update: The actor network is updated using the gradient of the pessimistic value function, rather than the gradient of the standard value function.
The pessimistic value function is estimated using a single neural network, in contrast to prior methods that used an ensemble of models to address overestimation bias.
The authors evaluate C-DDPG on several continuous control tasks, including MineRL, DMControl, and D4RL. They show that C-DDPG outperforms standard DDPG in terms of both performance and stability, while using a simpler architecture.
Critical Analysis
The Conservative DDPG algorithm proposed in this paper is a promising approach to addressing the overestimation bias problem in reinforcement learning. By using a pessimistic value function, the agent is able to make more cautious decisions and avoid taking actions that appear better than they truly are.
One potential limitation of the approach is that by consistently underestimating the true value of actions, the agent may become overly conservative and miss out on opportunities for high rewards. The authors acknowledge this in the paper and suggest that a more balanced approach, such as ADR-BC, may be preferable in some situations.
Additionally, the paper does not provide a thorough analysis of the computational complexity of C-DDPG compared to other methods. While the authors claim that it is simpler than ensemble-based approaches, the impact on training time and resource requirements is not fully explored.
Overall, the Conservative DDPG algorithm represents an interesting and potentially useful contribution to the field of reinforcement learning. Further research and empirical evaluation will be necessary to fully understand its strengths, weaknesses, and appropriate use cases.
Conclusion
The Conservative DDPG (C-DDPG) algorithm proposed in this paper offers a novel approach to addressing the overestimation bias problem in reinforcement learning. By using a pessimistic value function, C-DDPG is able to make more cautious decisions and achieve improved performance and stability compared to standard DDPG.
The simplicity of the C-DDPG architecture, which relies on a single neural network rather than an ensemble, is a key advantage of the method. This could make it more practical to implement and deploy in real-world applications.
While the paper provides a strong initial evaluation of C-DDPG, further research will be needed to fully understand its strengths, weaknesses, and potential use cases. Exploring the trade-offs between exploration and exploitation, as well as the computational complexity of the algorithm, could be fruitful areas for future work.
Overall, the Conservative DDPG algorithm represents an interesting and potentially impactful contribution to the field of reinforcement learning, with the potential to improve the reliability and performance of AI systems in a variety of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Conservative DDPG -- Pessimistic RL without Ensemble
Nitsan Soffair, Shie Mannor
DDPG is hindered by the overestimation bias problem, wherein its $Q$-estimates tend to overstate the actual $Q$-values. Traditional solutions to this bias involve ensemble-based methods, which require significant computational resources, or complex log-policy-based approaches, which are difficult to understand and implement. In contrast, we propose a straightforward solution using a $Q$-target and incorporating a behavioral cloning (BC) loss penalty. This solution, acting as an uncertainty measure, can be easily implemented with minimal code and without the need for an ensemble. Our empirical findings strongly support the superiority of Conservative DDPG over DDPG across various MuJoCo and Bullet tasks. We consistently observe better performance in all evaluated tasks and even competitive or superior performance compared to TD3 and TD7, all achieved with significantly reduced computational requirements.
Read more6/4/2024

0
Strategically Conservative Q-Learning
Yutaka Shimizu, Joey Hong, Sergey Levine, Masayoshi Tomizuka
Offline reinforcement learning (RL) is a compelling paradigm to extend RL's practical utility by leveraging pre-collected, static datasets, thereby avoiding the limitations associated with collecting online interactions. The major difficulty in offline RL is mitigating the impact of approximation errors when encountering out-of-distribution (OOD) actions; doing so ineffectively will lead to policies that prefer OOD actions, which can lead to unexpected and potentially catastrophic results. Despite the variety of works proposed to address this issue, they tend to excessively suppress the value function in and around OOD regions, resulting in overly pessimistic value estimates. In this paper, we propose a novel framework called Strategically Conservative Q-Learning (SCQ) that distinguishes between OOD data that is easy and hard to estimate, ultimately resulting in less conservative value estimates. Our approach exploits the inherent strengths of neural networks to interpolate, while carefully navigating their limitations in extrapolation, to obtain pessimistic yet still property calibrated value estimates. Theoretical analysis also shows that the value function learned by SCQ is still conservative, but potentially much less so than that of Conservative Q-learning (CQL). Finally, extensive evaluation on the D4RL benchmark tasks shows our proposed method outperforms state-of-the-art methods. Our code is available through url{https://github.com/purewater0901/SCQ}.
Read more6/10/2024
🏅
0
The Curious Price of Distributional Robustness in Reinforcement Learning with a Generative Model
Laixi Shi, Gen Li, Yuting Wei, Yuxin Chen, Matthieu Geist, Yuejie Chi
This paper investigates model robustness in reinforcement learning (RL) to reduce the sim-to-real gap in practice. We adopt the framework of distributionally robust Markov decision processes (RMDPs), aimed at learning a policy that optimizes the worst-case performance when the deployed environment falls within a prescribed uncertainty set around the nominal MDP. Despite recent efforts, the sample complexity of RMDPs remained mostly unsettled regardless of the uncertainty set in use. It was unclear if distributional robustness bears any statistical consequences when benchmarked against standard RL. Assuming access to a generative model that draws samples based on the nominal MDP, we characterize the sample complexity of RMDPs when the uncertainty set is specified via either the total variation (TV) distance or $chi^2$ divergence. The algorithm studied here is a model-based method called {em distributionally robust value iteration}, which is shown to be near-optimal for the full range of uncertainty levels. Somewhat surprisingly, our results uncover that RMDPs are not necessarily easier or harder to learn than standard MDPs. The statistical consequence incurred by the robustness requirement depends heavily on the size and shape of the uncertainty set: in the case w.r.t.~the TV distance, the minimax sample complexity of RMDPs is always smaller than that of standard MDPs; in the case w.r.t.~the $chi^2$ divergence, the sample complexity of RMDPs can often far exceed the standard MDP counterpart.
Read more4/15/2024
0
Robust Model-Based Reinforcement Learning with an Adversarial Auxiliary Model
Siemen Herremans, Ali Anwar, Siegfried Mercelis
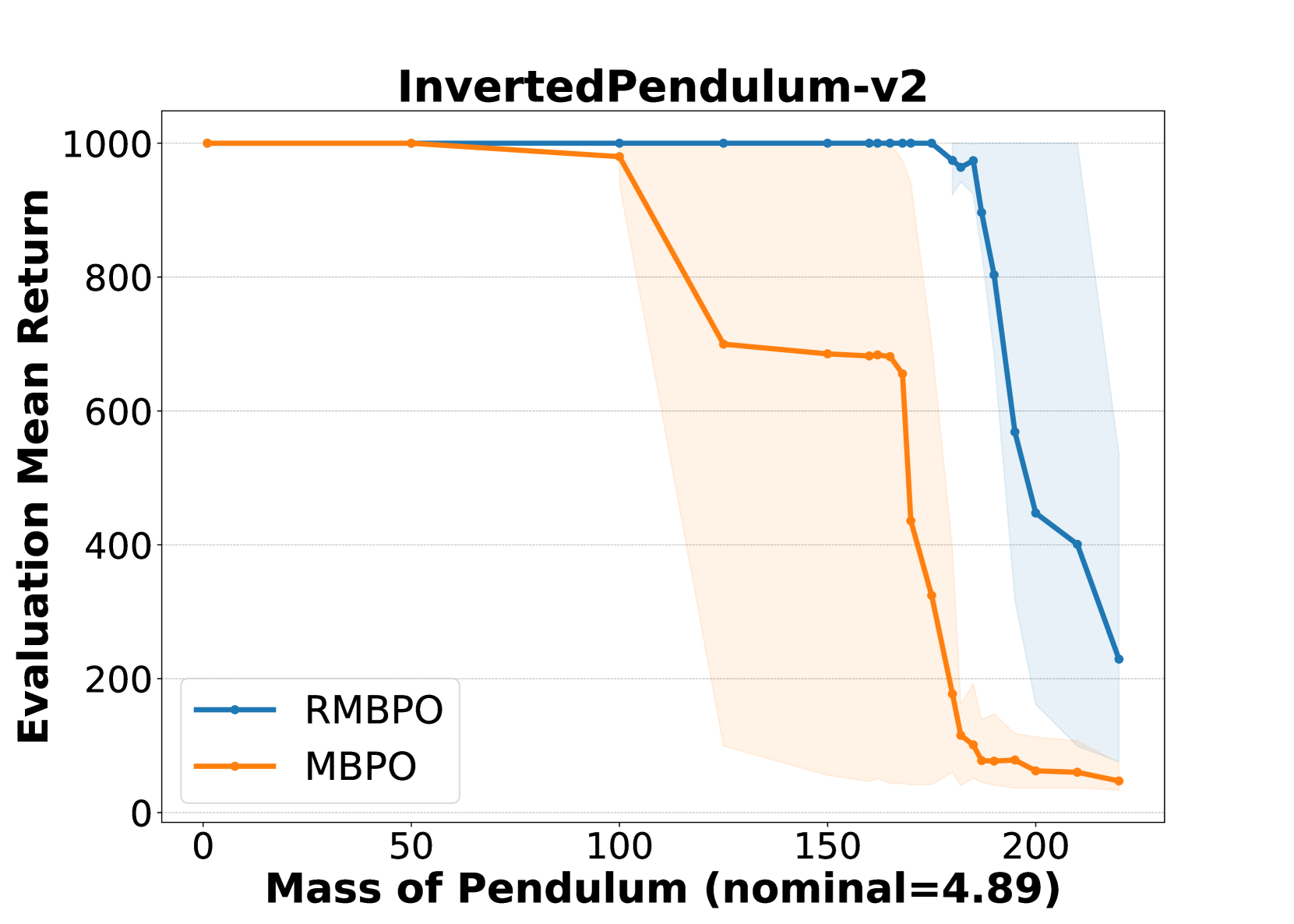
Reinforcement learning has demonstrated impressive performance in various challenging problems such as robotics, board games, and classical arcade games. However, its real-world applications can be hindered by the absence of robustness and safety in the learned policies. More specifically, an RL agent that trains in a certain Markov decision process (MDP) often struggles to perform well in nearly identical MDPs. To address this issue, we employ the framework of Robust MDPs (RMDPs) in a model-based setting and introduce a novel learned transition model. Our method specifically incorporates an auxiliary pessimistic model, updated adversarially, to estimate the worst-case MDP within a Kullback-Leibler uncertainty set. In comparison to several existing works, our work does not impose any additional conditions on the training environment, such as the need for a parametric simulator. To test the effectiveness of the proposed pessimistic model in enhancing policy robustness, we integrate it into a practical RL algorithm, called Robust Model-Based Policy Optimization (RMBPO). Our experimental results indicate a notable improvement in policy robustness on high-dimensional MuJoCo control tasks, with the auxiliary model enhancing the performance of the learned policy in distorted MDPs. We further explore the learned deviation between the proposed auxiliary world model and the nominal model, to examine how pessimism is achieved. By learning a pessimistic world model and demonstrating its role in improving policy robustness, our research contributes towards making (model-based) RL more robust.
Read more7/2/2024