Robust Model-Based Reinforcement Learning with an Adversarial Auxiliary Model
2406.09976
0
0
Abstract
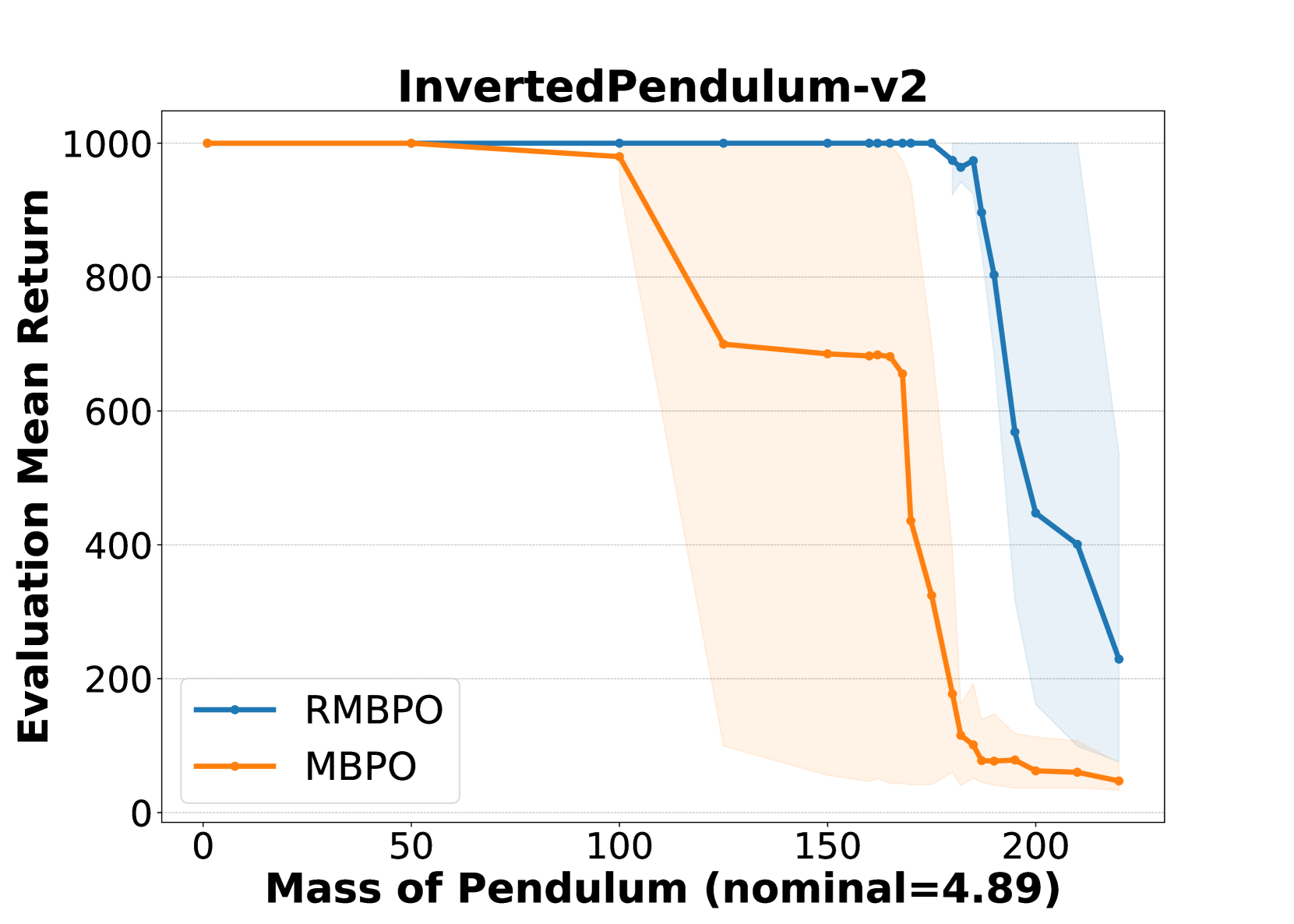
Reinforcement learning has demonstrated impressive performance in various challenging problems such as robotics, board games, and classical arcade games. However, its real-world applications can be hindered by the absence of robustness and safety in the learned policies. More specifically, an RL agent that trains in a certain Markov decision process (MDP) often struggles to perform well in nearly identical MDPs. To address this issue, we employ the framework of Robust MDPs (RMDPs) in a model-based setting and introduce a novel learned transition model. Our method specifically incorporates an auxiliary pessimistic model, updated adversarially, to estimate the worst-case MDP within a Kullback-Leibler uncertainty set. In comparison to several existing works, our work does not impose any additional conditions on the training environment, such as the need for a parametric simulator. To test the effectiveness of the proposed pessimistic model in enhancing policy robustness, we integrate it into a practical RL algorithm, called Robust Model-Based Policy Optimization (RMBPO). Our experimental results indicate a notable improvement in policy robustness on high-dimensional MuJoCo control tasks, with the auxiliary model enhancing the performance of the learned policy in distorted MDPs. We further explore the learned deviation between the proposed auxiliary world model and the nominal model, to examine how pessimism is achieved. By learning a pessimistic world model and demonstrating its role in improving policy robustness, our research contributes towards making (model-based) RL more robust.
Create account to get full access
Overview
- This paper proposes a novel approach to robust model-based reinforcement learning (RL) that uses an adversarial auxiliary model to improve the agent's performance in the face of environmental uncertainty or disturbances.
- The key idea is to train an auxiliary model to identify the most adversarial perturbations of the agent's observations, and then use this information to learn a more robust policy.
- This approach builds on prior work in robust Lagrangian adversarial policy gradients, time-constrained robust MDPs, and distributional robustness in RL.
Plain English Explanation
The paper presents a new way to make reinforcement learning (RL) systems more robust to changes or disturbances in their environment. RL systems are used to train agents, like digital assistants or robots, to perform tasks by learning from rewards and punishments. However, these agents can struggle when the environment is uncertain or unpredictable.
The key innovation in this paper is to train a separate "adversarial" model alongside the main RL agent. This adversarial model tries to find the worst-case perturbations or changes to the agent's observations that would cause it to perform poorly. By learning to handle these adversarial perturbations, the main agent becomes more robust and can adapt better to real-world uncertainty.
This builds on previous work that has explored related ideas, like using Lagrangian methods for robust RL, handling time constraints in robust MDPs, and achieving distributional robustness in RL. The key innovation here is the adversarial auxiliary model that directly targets the agent's vulnerabilities.
Technical Explanation
The paper proposes a robust model-based RL framework that trains an adversarial auxiliary model alongside the main agent. The auxiliary model aims to identify the most adversarial perturbations of the agent's observations, which the agent then learns to handle.
Specifically, the framework consists of three key components:
- A dynamics model: This learns to predict the next state given the current state and action.
- A reward model: This learns to predict the reward given the current state and action.
- An adversarial auxiliary model: This tries to find the worst-case perturbations of the agent's observations that would lead to the lowest predicted rewards.
The agent then learns a policy that maximizes the expected return under the worst-case perturbations identified by the adversarial model. This encourages the agent to become more robust and less sensitive to environmental disturbances.
The authors evaluate this approach on various control tasks and show that it outperforms standard model-based RL methods, as well as prior work on robust RL, in terms of both performance and sample efficiency.
Critical Analysis
The paper presents a compelling approach to improving the robustness of model-based RL agents. The key strength is the use of an adversarial auxiliary model to directly target the agent's vulnerabilities, which builds on prior work in robust RL and offline RL.
However, the paper does not address several potential limitations and areas for further research:
- The adversarial auxiliary model is trained separately from the main agent, which may not be optimal. Integrating the two training processes more tightly could potentially lead to further performance gains.
- The paper focuses on relatively simple control tasks. Evaluating the approach on more complex, real-world problems would be an important next step to assess its broader applicability.
- The paper does not provide much insight into the types of perturbations the adversarial model is identifying or how they relate to the agent's weaknesses. A deeper analysis of this could lead to a better understanding of the source of the agent's fragility.
Overall, the paper makes a valuable contribution to the field of robust RL, but further research is needed to fully understand the strengths and limitations of the proposed approach.
Conclusion
This paper presents a novel framework for robust model-based reinforcement learning that uses an adversarial auxiliary model to identify and mitigate the agent's vulnerabilities to environmental disturbances. By explicitly training the agent to handle the worst-case perturbations, the approach leads to significant performance improvements over standard RL methods.
The key innovation is the adversarial auxiliary model, which builds on prior work in robust RL and offline RL to directly target the agent's weaknesses. While the paper focuses on relatively simple control tasks, the approach has the potential to improve the reliability and robustness of RL agents in a wide range of real-world applications, from autonomous systems to decision-making assistants.
Further research is needed to fully understand the limitations of the approach and explore ways to integrate the adversarial model more tightly into the agent's training process. Nevertheless, this paper represents an important step forward in the quest to develop RL systems that can reliably operate in complex, uncertain environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
➖
Robust Lagrangian and Adversarial Policy Gradient for Robust Constrained Markov Decision Processes
David M. Bossens
0
0
The robust constrained Markov decision process (RCMDP) is a recent task-modelling framework for reinforcement learning that incorporates behavioural constraints and that provides robustness to errors in the transition dynamics model through the use of an uncertainty set. Simulating RCMDPs requires computing the worst-case dynamics based on value estimates for each state, an approach which has previously been used in the Robust Constrained Policy Gradient (RCPG). Highlighting potential downsides of RCPG such as not robustifying the full constrained objective and the lack of incremental learning, this paper introduces two algorithms, called RCPG with Robust Lagrangian and Adversarial RCPG. RCPG with Robust Lagrangian modifies RCPG by taking the worst-case dynamics based on the Lagrangian rather than either the value or the constraint. Adversarial RCPG also formulates the worst-case dynamics based on the Lagrangian but learns this directly and incrementally as an adversarial policy through gradient descent rather than indirectly and abruptly through constrained optimisation on a sorted value list. A theoretical analysis first derives the Lagrangian policy gradient for the policy optimisation of both proposed algorithms and then the adversarial policy gradient to learn the adversary for Adversarial RCPG. Empirical experiments injecting perturbations in inventory management and safe navigation tasks demonstrate the competitive performance of both algorithms compared to traditional RCPG variants as well as non-robust and non-constrained ablations. In particular, Adversarial RCPG ranks among the top two performing algorithms on all tests.
5/16/2024
🏅
The Curious Price of Distributional Robustness in Reinforcement Learning with a Generative Model
Laixi Shi, Gen Li, Yuting Wei, Yuxin Chen, Matthieu Geist, Yuejie Chi
0
0
This paper investigates model robustness in reinforcement learning (RL) to reduce the sim-to-real gap in practice. We adopt the framework of distributionally robust Markov decision processes (RMDPs), aimed at learning a policy that optimizes the worst-case performance when the deployed environment falls within a prescribed uncertainty set around the nominal MDP. Despite recent efforts, the sample complexity of RMDPs remained mostly unsettled regardless of the uncertainty set in use. It was unclear if distributional robustness bears any statistical consequences when benchmarked against standard RL. Assuming access to a generative model that draws samples based on the nominal MDP, we characterize the sample complexity of RMDPs when the uncertainty set is specified via either the total variation (TV) distance or $chi^2$ divergence. The algorithm studied here is a model-based method called {em distributionally robust value iteration}, which is shown to be near-optimal for the full range of uncertainty levels. Somewhat surprisingly, our results uncover that RMDPs are not necessarily easier or harder to learn than standard MDPs. The statistical consequence incurred by the robustness requirement depends heavily on the size and shape of the uncertainty set: in the case w.r.t.~the TV distance, the minimax sample complexity of RMDPs is always smaller than that of standard MDPs; in the case w.r.t.~the $chi^2$ divergence, the sample complexity of RMDPs can often far exceed the standard MDP counterpart.
4/15/2024

Time-Constrained Robust MDPs
Adil Zouitine, David Bertoin, Pierre Clavier, Matthieu Geist, Emmanuel Rachelson
0
0
Robust reinforcement learning is essential for deploying reinforcement learning algorithms in real-world scenarios where environmental uncertainty predominates. Traditional robust reinforcement learning often depends on rectangularity assumptions, where adverse probability measures of outcome states are assumed to be independent across different states and actions. This assumption, rarely fulfilled in practice, leads to overly conservative policies. To address this problem, we introduce a new time-constrained robust MDP (TC-RMDP) formulation that considers multifactorial, correlated, and time-dependent disturbances, thus more accurately reflecting real-world dynamics. This formulation goes beyond the conventional rectangularity paradigm, offering new perspectives and expanding the analytical framework for robust RL. We propose three distinct algorithms, each using varying levels of environmental information, and evaluate them extensively on continuous control benchmarks. Our results demonstrate that these algorithms yield an efficient tradeoff between performance and robustness, outperforming traditional deep robust RL methods in time-constrained environments while preserving robustness in classical benchmarks. This study revisits the prevailing assumptions in robust RL and opens new avenues for developing more practical and realistic RL applications.
6/13/2024
Robust Risk-Sensitive Reinforcement Learning with Conditional Value-at-Risk
Xinyi Ni, Lifeng Lai
0
0
Robust Markov Decision Processes (RMDPs) have received significant research interest, offering an alternative to standard Markov Decision Processes (MDPs) that often assume fixed transition probabilities. RMDPs address this by optimizing for the worst-case scenarios within ambiguity sets. While earlier studies on RMDPs have largely centered on risk-neutral reinforcement learning (RL), with the goal of minimizing expected total discounted costs, in this paper, we analyze the robustness of CVaR-based risk-sensitive RL under RMDP. Firstly, we consider predetermined ambiguity sets. Based on the coherency of CVaR, we establish a connection between robustness and risk sensitivity, thus, techniques in risk-sensitive RL can be adopted to solve the proposed problem. Furthermore, motivated by the existence of decision-dependent uncertainty in real-world problems, we study problems with state-action-dependent ambiguity sets. To solve this, we define a new risk measure named NCVaR and build the equivalence of NCVaR optimization and robust CVaR optimization. We further propose value iteration algorithms and validate our approach in simulation experiments.
5/6/2024