Constrained Reinforcement Learning Under Model Mismatch
2405.01327
0
0
Abstract
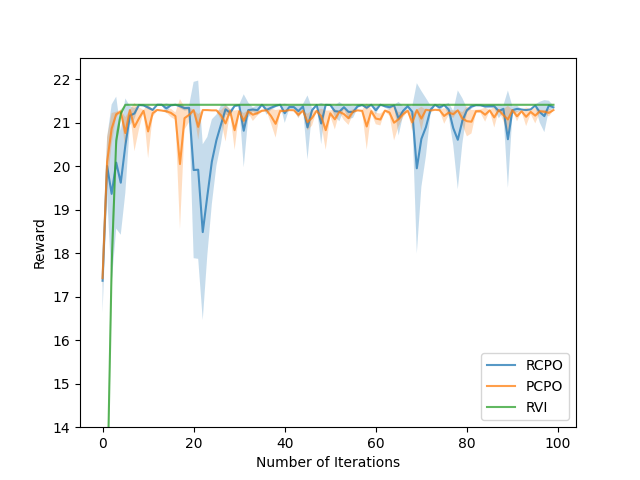
Existing studies on constrained reinforcement learning (RL) may obtain a well-performing policy in the training environment. However, when deployed in a real environment, it may easily violate constraints that were originally satisfied during training because there might be model mismatch between the training and real environments. To address the above challenge, we formulate the problem as constrained RL under model uncertainty, where the goal is to learn a good policy that optimizes the reward and at the same time satisfy the constraint under model mismatch. We develop a Robust Constrained Policy Optimization (RCPO) algorithm, which is the first algorithm that applies to large/continuous state space and has theoretical guarantees on worst-case reward improvement and constraint violation at each iteration during the training. We demonstrate the effectiveness of our algorithm on a set of RL tasks with constraints.
Create account to get full access
Overview
- This paper explores reinforcement learning (RL) in scenarios where there is a mismatch between the true environment and the environment model used for training the RL agent.
- The authors propose a novel approach called Constrained Reinforcement Learning Under Model Mismatch (CRLUMM) that can handle this model mismatch while satisfying certain constraints.
- CRLUMM aims to learn a policy that optimizes the true objective function while ensuring that the policy satisfies the given constraints, even when the model used for training does not accurately reflect the real-world environment.
Plain English Explanation
Reinforcement learning (RL) is a powerful technique used to train agents to make decisions in complex environments. However, in many real-world scenarios, the model of the environment used during training may not perfectly match the true environment. This can lead to the agent learning a policy that performs well in the training environment but fails to satisfy important constraints or achieve the desired objective when deployed in the real world.
The Constrained Reinforcement Learning Under Model Mismatch (CRLUMM) approach proposed in this paper aims to address this challenge. CRLUMM learns a policy that not only optimizes the true objective function (i.e., the desired outcome) but also ensures that the policy satisfies the given constraints, even when there is a mismatch between the training model and the actual environment.
This is particularly useful in situations where there are critical safety or performance requirements that must be met, such as in autonomous driving, robotics, or financial trading. By explicitly accounting for the model mismatch, CRLUMM can help ensure that the learned policy is robust and reliable when deployed in the real world.
Technical Explanation
The key idea behind CRLUMM is to formulate the RL problem as a constrained optimization problem, where the objective is to maximize the true reward function while satisfying the given constraints. The authors leverage a unified view of solving objective mismatch in model-based RL to tackle the model mismatch challenge.
Specifically, CRLUMM uses a "dual-perspective" approach, where the agent simultaneously learns a policy and a constraint function. The policy optimization step aims to maximize the true reward function, while the constraint function learning step ensures that the policy satisfies the given constraints, even in the presence of model mismatch.
The authors demonstrate the effectiveness of CRLUMM through extensive experiments, including a sample-efficient and robust multi-agent reinforcement learning setup and a Reinforcement Learning via Regressing Relative Rewards (REBEL) benchmark. The results show that CRLUMM outperforms traditional RL approaches in terms of constraint satisfaction and true reward optimization, particularly when there is a significant model mismatch.
Critical Analysis
The authors acknowledge several limitations and areas for further research in their paper. For example, they note that CRLUMM relies on accurate estimates of the true reward and constraint functions, which may not always be available in practice. Additionally, the computational complexity of the approach may be a concern, especially in large-scale or high-dimensional environments.
One potential issue not explicitly addressed in the paper is the potential for policy constraints to introduce their own biases or unintended consequences. While the authors focus on satisfying constraints, it is important to carefully consider the implications of the chosen constraints and ensure that they align with the desired objectives.
Further research could explore ways to make CRLUMM more sample-efficient, investigate the impact of different constraint formulations, and examine the potential for transfer learning or domain adaptation to mitigate the effects of model mismatch.
Conclusion
The Constrained Reinforcement Learning Under Model Mismatch (CRLUMM) approach proposed in this paper addresses an important challenge in real-world RL applications, where the training environment may not accurately reflect the true environment. By explicitly accounting for model mismatch and formulating the RL problem as a constrained optimization task, CRLUMM can learn policies that optimize the true objective function while satisfying critical constraints.
The promising results demonstrated in the paper suggest that CRLUMM could have significant implications for the deployment of RL systems in safety-critical or high-stakes domains, where reliable and robust decision-making is paramount. As the field of RL continues to advance, techniques like CRLUMM will be crucial for bridging the gap between simulated environments and the complexities of the real world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
Constraint-Conditioned Policy Optimization for Versatile Safe Reinforcement Learning
Yihang Yao, Zuxin Liu, Zhepeng Cen, Jiacheng Zhu, Wenhao Yu, Tingnan Zhang, Ding Zhao
0
0
Safe reinforcement learning (RL) focuses on training reward-maximizing agents subject to pre-defined safety constraints. Yet, learning versatile safe policies that can adapt to varying safety constraint requirements during deployment without retraining remains a largely unexplored and challenging area. In this work, we formulate the versatile safe RL problem and consider two primary requirements: training efficiency and zero-shot adaptation capability. To address them, we introduce the Conditioned Constrained Policy Optimization (CCPO) framework, consisting of two key modules: (1) Versatile Value Estimation (VVE) for approximating value functions under unseen threshold conditions, and (2) Conditioned Variational Inference (CVI) for encoding arbitrary constraint thresholds during policy optimization. Our extensive experiments demonstrate that CCPO outperforms the baselines in terms of safety and task performance while preserving zero-shot adaptation capabilities to different constraint thresholds data-efficiently. This makes our approach suitable for real-world dynamic applications.
5/1/2024

State-wise Constrained Policy Optimization
Weiye Zhao, Rui Chen, Yifan Sun, Tianhao Wei, Changliu Liu
0
0
Reinforcement Learning (RL) algorithms have shown tremendous success in simulation environments, but their application to real-world problems faces significant challenges, with safety being a major concern. In particular, enforcing state-wise constraints is essential for many challenging tasks such as autonomous driving and robot manipulation. However, existing safe RL algorithms under the framework of Constrained Markov Decision Process (CMDP) do not consider state-wise constraints. To address this gap, we propose State-wise Constrained Policy Optimization (SCPO), the first general-purpose policy search algorithm for state-wise constrained reinforcement learning. SCPO provides guarantees for state-wise constraint satisfaction in expectation. In particular, we introduce the framework of Maximum Markov Decision Process, and prove that the worst-case safety violation is bounded under SCPO. We demonstrate the effectiveness of our approach on training neural network policies for extensive robot locomotion tasks, where the agent must satisfy a variety of state-wise safety constraints. Our results show that SCPO significantly outperforms existing methods and can handle state-wise constraints in high-dimensional robotics tasks.
6/19/2024

POLICEd RL: Learning Closed-Loop Robot Control Policies with Provable Satisfaction of Hard Constraints
Jean-Baptiste Bouvier, Kartik Nagpal, Negar Mehr
0
0
In this paper, we seek to learn a robot policy guaranteed to satisfy state constraints. To encourage constraint satisfaction, existing RL algorithms typically rely on Constrained Markov Decision Processes and discourage constraint violations through reward shaping. However, such soft constraints cannot offer verifiable safety guarantees. To address this gap, we propose POLICEd RL, a novel RL algorithm explicitly designed to enforce affine hard constraints in closed-loop with a black-box environment. Our key insight is to force the learned policy to be affine around the unsafe set and use this affine region as a repulsive buffer to prevent trajectories from violating the constraint. We prove that such policies exist and guarantee constraint satisfaction. Our proposed framework is applicable to both systems with continuous and discrete state and action spaces and is agnostic to the choice of the RL training algorithm. Our results demonstrate the capacity of POLICEd RL to enforce hard constraints in robotic tasks while significantly outperforming existing methods.
6/5/2024

Confidence Aware Inverse Constrained Reinforcement Learning
Sriram Ganapathi Subramanian, Guiliang Liu, Mohammed Elmahgiubi, Kasra Rezaee, Pascal Poupart
0
0
In coming up with solutions to real-world problems, humans implicitly adhere to constraints that are too numerous and complex to be specified completely. However, reinforcement learning (RL) agents need these constraints to learn the correct optimal policy in these settings. The field of Inverse Constraint Reinforcement Learning (ICRL) deals with this problem and provides algorithms that aim to estimate the constraints from expert demonstrations collected offline. Practitioners prefer to know a measure of confidence in the estimated constraints, before deciding to use these constraints, which allows them to only use the constraints that satisfy a desired level of confidence. However, prior works do not allow users to provide the desired level of confidence for the inferred constraints. This work provides a principled ICRL method that can take a confidence level with a set of expert demonstrations and outputs a constraint that is at least as constraining as the true underlying constraint with the desired level of confidence. Further, unlike previous methods, this method allows a user to know if the number of expert trajectories is insufficient to learn a constraint with a desired level of confidence, and therefore collect more expert trajectories as required to simultaneously learn constraints with the desired level of confidence and a policy that achieves the desired level of performance.
6/26/2024