A Dual Perspective of Reinforcement Learning for Imposing Policy Constraints
2404.16468
0
0
🏅
Abstract
Model-free reinforcement learning methods lack an inherent mechanism to impose behavioural constraints on the trained policies. While certain extensions exist, they remain limited to specific types of constraints, such as value constraints with additional reward signals or visitation density constraints. In this work we try to unify these existing techniques and bridge the gap with classical optimization and control theory, using a generic primal-dual framework for value-based and actor-critic reinforcement learning methods. The obtained dual formulations turn out to be especially useful for imposing additional constraints on the learned policy, as an intrinsic relationship between such dual constraints (or regularization terms) and reward modifications in the primal is reveiled. Furthermore, using this framework, we are able to introduce some novel types of constraints, allowing to impose bounds on the policy's action density or on costs associated with transitions between consecutive states and actions. From the adjusted primal-dual optimization problems, a practical algorithm is derived that supports various combinations of policy constraints that are automatically handled throughout training using trainable reward modifications. The resulting $texttt{DualCRL}$ method is examined in more detail and evaluated under different (combinations of) constraints on two interpretable environments. The results highlight the efficacy of the method, which ultimately provides the designer of such systems with a versatile toolbox of possible policy constraints.
Create account to get full access
Overview
- Reinforcement learning (RL) methods lack a built-in way to impose constraints on the policies they learn.
- While some extensions exist, they are limited to specific types of constraints, such as value constraints or visitation density constraints.
- This work aims to unify these existing techniques and bridge the gap with classical optimization and control theory using a generic primal-dual framework.
- The obtained dual formulations enable the imposition of various types of constraints on the learned policy, including bounds on action density or costs between states and actions.
- A practical algorithm called DualCRL is derived from the primal-dual optimization problems, which can handle different combinations of policy constraints during training.
Plain English Explanation
Reinforcement learning (RL) is a powerful technique for training agents to solve complex tasks, but it can be challenging to ensure that the learned policies follow certain rules or constraints. For example, you might want the agent to avoid taking actions that are too risky or expensive.
Traditional RL methods don't have a built-in way to impose these kinds of constraints on the policies they learn. While some researchers have developed extensions to address this, the solutions are often limited to specific types of constraints, such as bounding the value of the policy or restricting the density of states the agent visits.
In this work, the researchers try to unify these existing techniques and connect them to classical optimization and control theory. They use a general mathematical framework called "primal-dual" to derive new formulations that can handle a wider variety of constraints on the learned policies.
The key insight is that by looking at the "dual" version of the optimization problem, they can find a direct relationship between the constraints they want to impose and changes to the reward function that the RL agent is trained on. This allows them to automatically adjust the rewards during training to satisfy the desired constraints, without having to modify the RL algorithm itself.
Using this framework, the researchers introduce some novel types of constraints, such as bounding the density of actions the agent takes or the costs associated with transitions between states and actions. They then derive a practical algorithm called DualCRL that can handle various combinations of these constraints.
The key benefit of this approach is that it gives the designer of the RL system a "toolbox" of different constraints they can easily incorporate, without having to come up with custom solutions for each one. This could be especially useful for applications where safety or resource constraints are important, such as in robotics, autonomous vehicles, or financial trading.
Technical Explanation
The paper presents a generic primal-dual framework for imposing constraints on the policies learned by value-based and actor-critic RL methods. This framework unifies and generalizes existing techniques for constrained RL, such as value constraints with additional reward signals or visitation density constraints.
The key idea is to derive dual formulations of the RL optimization problems, which reveal an intrinsic relationship between the dual constraints (or regularization terms) and reward modifications in the primal problem. This allows the introduction of novel types of constraints, such as:
- Bounds on the policy's action density
- Bounds on costs associated with transitions between consecutive states and actions
From the primal-dual optimization problems, the researchers derive a practical algorithm called DualCRL that can handle various combinations of these policy constraints. The constraints are automatically handled during training through trainable reward modifications.
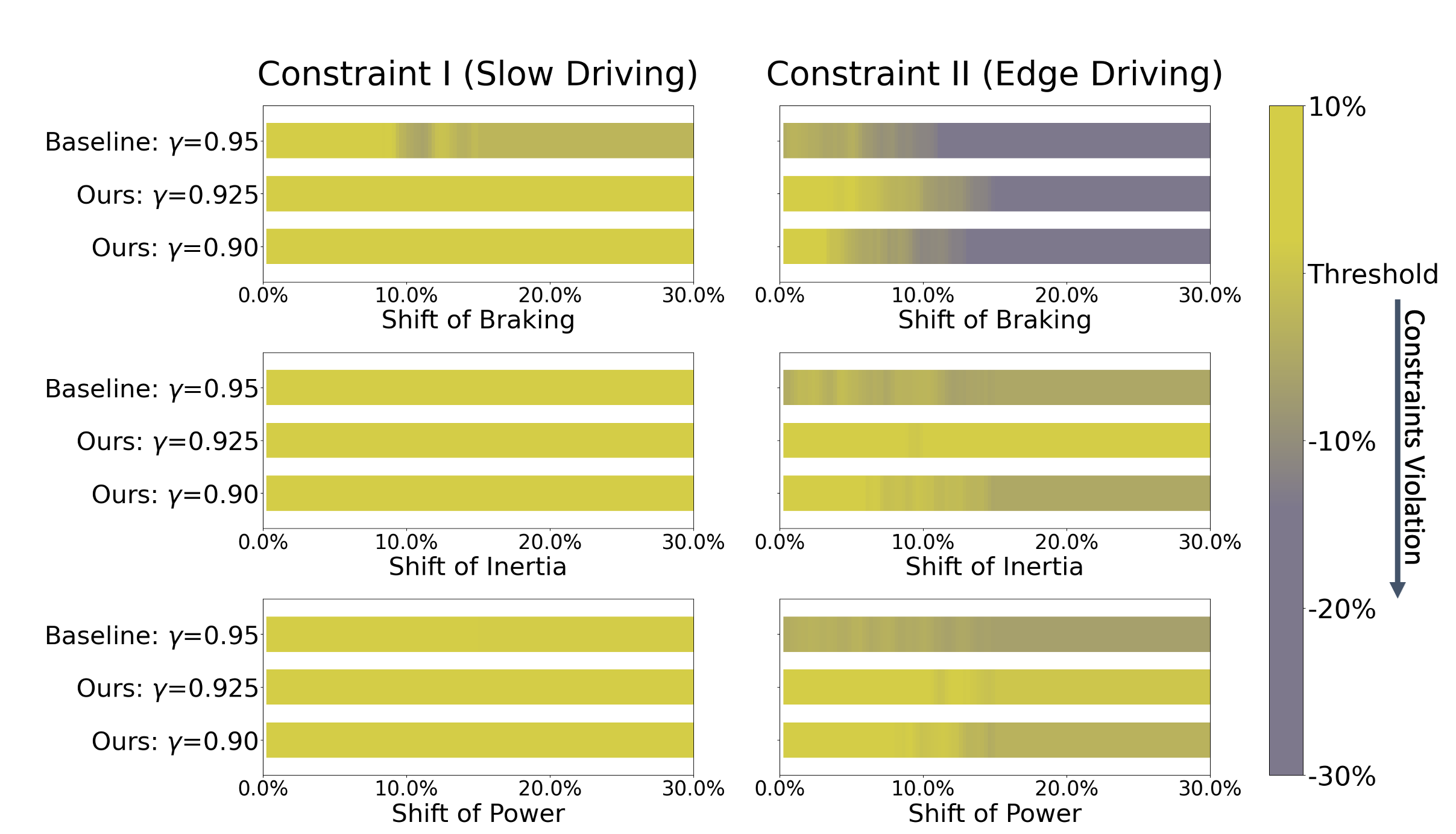
The authors evaluate DualCRL on two interpretable environments under different (combinations of) constraints. The results demonstrate the efficacy of the method and provide the designer of such systems with a versatile toolbox of possible policy constraints.
Critical Analysis
The paper presents a promising approach for incorporating a wide range of constraints into RL policies, but there are a few potential limitations and areas for further research:
-
Scalability to complex environments: The experiments in the paper are conducted on relatively simple, interpretable environments. It's unclear how well the DualCRL algorithm would scale to more complex, high-dimensional problems, where the representation of constraints and reward modifications may become more challenging.
-
Theoretical guarantees: While the primal-dual framework provides a principled way to derive the constrained RL algorithms, the paper does not provide strong theoretical guarantees about the convergence or optimality of the solutions obtained. Further analysis in this direction could strengthen the theoretical foundations of the approach.
-
Generalization to other RL algorithms: The current work focuses on value-based and actor-critic methods. It would be interesting to see if the primal-dual framework can be extended to other RL paradigms, such as policy gradient or multi-agent methods, to further broaden the applicability of the approach.
-
Practical implementation challenges: While the paper presents a general framework, the implementation of the DualCRL algorithm may still require careful tuning of hyperparameters and constraint-specific reward modifications. Addressing these practical concerns could further improve the usability of the method.
Overall, this work represents an important step towards more versatile and constrained RL systems, which could have significant implications for safety-critical applications and real-world deployment of RL agents.
Conclusion
This paper proposes a generic primal-dual framework for incorporating a wide range of constraints into reinforcement learning policies. By deriving dual formulations of the RL optimization problems, the researchers unify and generalize existing techniques for constrained RL, enabling the introduction of novel types of constraints, such as bounds on action density or transition costs.
The resulting DualCRL algorithm provides a versatile toolbox for the designer of RL systems to easily impose various combinations of policy constraints, which is particularly important for safety-critical applications. While further research is needed to address scalability, theoretical guarantees, and practical implementation challenges, this work represents a significant step forward in the field of constrained reinforcement learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
Off-Policy Primal-Dual Safe Reinforcement Learning
Zifan Wu, Bo Tang, Qian Lin, Chao Yu, Shangqin Mao, Qianlong Xie, Xingxing Wang, Dong Wang
0
0
Primal-dual safe RL methods commonly perform iterations between the primal update of the policy and the dual update of the Lagrange Multiplier. Such a training paradigm is highly susceptible to the error in cumulative cost estimation since this estimation serves as the key bond connecting the primal and dual update processes. We show that this problem causes significant underestimation of cost when using off-policy methods, leading to the failure to satisfy the safety constraint. To address this issue, we propose conservative policy optimization, which learns a policy in a constraint-satisfying area by considering the uncertainty in cost estimation. This improves constraint satisfaction but also potentially hinders reward maximization. We then introduce local policy convexification to help eliminate such suboptimality by gradually reducing the estimation uncertainty. We provide theoretical interpretations of the joint coupling effect of these two ingredients and further verify them by extensive experiments. Results on benchmark tasks show that our method not only achieves an asymptotic performance comparable to state-of-the-art on-policy methods while using much fewer samples, but also significantly reduces constraint violation during training. Our code is available at https://github.com/ZifanWu/CAL.
4/16/2024
🌿
Natural Policy Gradient and Actor Critic Methods for Constrained Multi-Task Reinforcement Learning
Sihan Zeng, Thinh T. Doan, Justin Romberg
0
0
Multi-task reinforcement learning (RL) aims to find a single policy that effectively solves multiple tasks at the same time. This paper presents a constrained formulation for multi-task RL where the goal is to maximize the average performance of the policy across tasks subject to bounds on the performance in each task. We consider solving this problem both in the centralized setting, where information for all tasks is accessible to a single server, and in the decentralized setting, where a network of agents, each given one task and observing local information, cooperate to find the solution of the globally constrained objective using local communication. We first propose a primal-dual algorithm that provably converges to the globally optimal solution of this constrained formulation under exact gradient evaluations. When the gradient is unknown, we further develop a sampled-based actor-critic algorithm that finds the optimal policy using online samples of state, action, and reward. Finally, we study the extension of the algorithm to the linear function approximation setting.
5/7/2024
Distributionally Robust Constrained Reinforcement Learning under Strong Duality
Zhengfei Zhang, Kishan Panaganti, Laixi Shi, Yanan Sui, Adam Wierman, Yisong Yue
0
0
We study the problem of Distributionally Robust Constrained RL (DRC-RL), where the goal is to maximize the expected reward subject to environmental distribution shifts and constraints. This setting captures situations where training and testing environments differ, and policies must satisfy constraints motivated by safety or limited budgets. Despite significant progress toward algorithm design for the separate problems of distributionally robust RL and constrained RL, there do not yet exist algorithms with end-to-end convergence guarantees for DRC-RL. We develop an algorithmic framework based on strong duality that enables the first efficient and provable solution in a class of environmental uncertainties. Further, our framework exposes an inherent structure of DRC-RL that arises from the combination of distributional robustness and constraints, which prevents a popular class of iterative methods from tractably solving DRC-RL, despite such frameworks being applicable for each of distributionally robust RL and constrained RL individually. Finally, we conduct experiments on a car racing benchmark to evaluate the effectiveness of the proposed algorithm.
6/26/2024
One-Shot Safety Alignment for Large Language Models via Optimal Dualization
Xinmeng Huang, Shuo Li, Edgar Dobriban, Osbert Bastani, Hamed Hassani, Dongsheng Ding
0
0
The growing safety concerns surrounding Large Language Models (LLMs) raise an urgent need to align them with diverse human preferences to simultaneously enhance their helpfulness and safety. A promising approach is to enforce safety constraints through Reinforcement Learning from Human Feedback (RLHF). For such constrained RLHF, common Lagrangian-based primal-dual policy optimization methods are computationally expensive and often unstable. This paper presents a dualization perspective that reduces constrained alignment to an equivalent unconstrained alignment problem. We do so by pre-optimizing a smooth and convex dual function that has a closed form. This shortcut eliminates the need for cumbersome primal-dual policy iterations, thus greatly reducing the computational burden and improving training stability. Our strategy leads to two practical algorithms in model-based and preference-based scenarios (MoCAN and PeCAN, respectively). A broad range of experiments demonstrate the effectiveness of our methods.
5/31/2024