A Constraint-Enforcing Reward for Adversarial Attacks on Text Classifiers

0

Sign in to get full access
Overview
- This paper proposes a novel approach to generating adversarial attacks on text classifiers that enforces certain constraints on the generated text, such as preserving the original semantic meaning and ensuring grammatical correctness.
- The authors develop a reinforcement learning-based framework that learns to craft adversarial examples while satisfying these constraints, aiming to improve the robustness of text classification models.
- The proposed method is evaluated on several text classification tasks and demonstrates improved performance in generating effective and realistic adversarial examples compared to existing approaches.
Plain English Explanation
Adversarial attacks are a type of cyber attack where attackers try to trick machine learning models, like text classifiers, into making mistakes. In this paper, the researchers developed a new way to create these adversarial attacks on text classifiers that also ensures the generated text is still meaningful and grammatically correct.
Typically, adversarial attacks can produce text that is unnatural or nonsensical, which makes them easy to detect. The researchers wanted to create a system that could generate more realistic-looking adversarial examples. To do this, they used a reinforcement learning approach, where the model learns to craft adversarial attacks that satisfy certain constraints, like preserving the original meaning of the text and maintaining proper grammar.
By enforcing these constraints, the researchers were able to generate adversarial examples that were more effective at fooling the text classifiers, while also being more human-like and harder to detect. This could help improve the robustness of these models against real-world attacks.
Technical Explanation
The key innovation in this paper is the development of a constraint-enforcing reward function for training a reinforcement learning-based adversarial attack generator. Typically, adversarial attacks on text classifiers are generated by optimizing for a loss function that maximizes the classifier's prediction error. However, this can lead to the generation of text that is grammatically incorrect or semantically incoherent.
To address this, the authors introduce additional constraints into the reward function, such as preserving the original semantic meaning of the text and ensuring grammatical correctness. They achieve this by incorporating pre-trained language models and other auxiliary metrics into the reward calculation. The adversarial attack generator is then trained using proximal policy optimization (PPO) to learn to craft perturbations that fool the target classifier while satisfying these constraints.
The proposed approach is evaluated on several text classification tasks, including sentiment analysis, topic classification, and natural language inference. The results show that the constrained adversarial examples generated by the authors' method are more effective at fooling the target classifiers compared to unconstrained attacks, while also being more realistic and harder to detect.
Critical Analysis
The authors present a compelling approach to generating more realistic and effective adversarial attacks on text classifiers. By incorporating linguistic constraints into the reward function, they are able to produce perturbations that are both adversarial and human-like, which is an important consideration for evaluating the robustness of these models in real-world scenarios.
However, the paper does not address the potential ethical implications of this research. Adversarial attacks, even those that are constrained to be more realistic, could still be used maliciously to bypass content moderation systems or spread misinformation. The authors could have discussed potential safeguards or responsible use cases for their technique.
Additionally, the paper lacks a thorough analysis of the linguistic properties of the generated adversarial examples. It would be valuable to understand how the constraints impact the syntactic, semantic, and pragmatic qualities of the text, and whether there are any unintended consequences or biases introduced by the approach.
Conclusion
This paper presents a novel reinforcement learning-based method for generating adversarial attacks on text classifiers that enforces linguistic constraints, such as preserving semantic meaning and grammatical correctness. By incorporating these constraints into the reward function, the authors are able to produce more realistic and effective adversarial examples compared to unconstrained attacks.
The proposed technique could help improve the robustness of text classification models by exposing their vulnerabilities in a more human-like manner. However, the potential ethical implications of this research should be carefully considered, and further analysis of the linguistic properties of the generated adversarial examples would be beneficial.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Constraint-Enforcing Reward for Adversarial Attacks on Text Classifiers
Tom Roth, Inigo Jauregi Unanue, Alsharif Abuadbba, Massimo Piccardi
Text classifiers are vulnerable to adversarial examples -- correctly-classified examples that are deliberately transformed to be misclassified while satisfying acceptability constraints. The conventional approach to finding adversarial examples is to define and solve a combinatorial optimisation problem over a space of allowable transformations. While effective, this approach is slow and limited by the choice of transformations. An alternate approach is to directly generate adversarial examples by fine-tuning a pre-trained language model, as is commonly done for other text-to-text tasks. This approach promises to be much quicker and more expressive, but is relatively unexplored. For this reason, in this work we train an encoder-decoder paraphrase model to generate a diverse range of adversarial examples. For training, we adopt a reinforcement learning algorithm and propose a constraint-enforcing reward that promotes the generation of valid adversarial examples. Experimental results over two text classification datasets show that our model has achieved a higher success rate than the original paraphrase model, and overall has proved more effective than other competitive attacks. Finally, we show how key design choices impact the generated examples and discuss the strengths and weaknesses of the proposed approach.
Read more5/21/2024
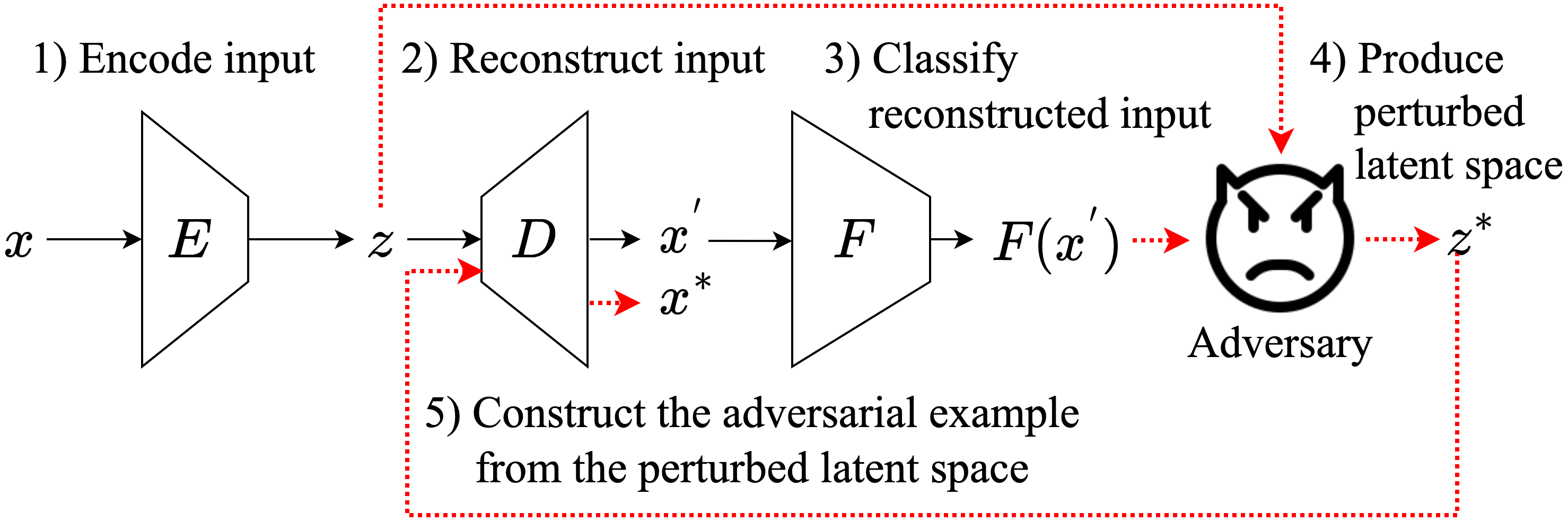
0
On Adversarial Examples for Text Classification by Perturbing Latent Representations
Korn Sooksatra, Bikram Khanal, Pablo Rivas
Recently, with the advancement of deep learning, several applications in text classification have advanced significantly. However, this improvement comes with a cost because deep learning is vulnerable to adversarial examples. This weakness indicates that deep learning is not very robust. Fortunately, the input of a text classifier is discrete. Hence, it can prevent the classifier from state-of-the-art attacks. Nonetheless, previous works have generated black-box attacks that successfully manipulate the discrete values of the input to find adversarial examples. Therefore, instead of changing the discrete values, we transform the input into its embedding vector containing real values to perform the state-of-the-art white-box attacks. Then, we convert the perturbed embedding vector back into a text and name it an adversarial example. In summary, we create a framework that measures the robustness of a text classifier by using the gradients of the classifier.
Read more5/8/2024
🔄
0
Adversarial Attacks and Defense for Conversation Entailment Task
Zhenning Yang, Ryan Krawec, Liang-Yuan Wu
As the deployment of NLP systems in critical applications grows, ensuring the robustness of large language models (LLMs) against adversarial attacks becomes increasingly important. Large language models excel in various NLP tasks but remain vulnerable to low-cost adversarial attacks. Focusing on the domain of conversation entailment, where multi-turn dialogues serve as premises to verify hypotheses, we fine-tune a transformer model to accurately discern the truthfulness of these hypotheses. Adversaries manipulate hypotheses through synonym swapping, aiming to deceive the model into making incorrect predictions. To counteract these attacks, we implemented innovative fine-tuning techniques and introduced an embedding perturbation loss method to significantly bolster the model's robustness. Our findings not only emphasize the importance of defending against adversarial attacks in NLP but also highlight the real-world implications, suggesting that enhancing model robustness is critical for reliable NLP applications.
Read more5/3/2024

0
READ: Improving Relation Extraction from an ADversarial Perspective
Dawei Li, William Hogan, Jingbo Shang
Recent works in relation extraction (RE) have achieved promising benchmark accuracy; however, our adversarial attack experiments show that these works excessively rely on entities, making their generalization capability questionable. To address this issue, we propose an adversarial training method specifically designed for RE. Our approach introduces both sequence- and token-level perturbations to the sample and uses a separate perturbation vocabulary to improve the search for entity and context perturbations. Furthermore, we introduce a probabilistic strategy for leaving clean tokens in the context during adversarial training. This strategy enables a larger attack budget for entities and coaxes the model to leverage relational patterns embedded in the context. Extensive experiments show that compared to various adversarial training methods, our method significantly improves both the accuracy and robustness of the model. Additionally, experiments on different data availability settings highlight the effectiveness of our method in low-resource scenarios. We also perform in-depth analyses of our proposed method and provide further hints. We will release our code at https://github.com/David-Li0406/READ.
Read more4/5/2024