In-Context Example Selection via Similarity Search Improves Low-Resource Machine Translation

0

Sign in to get full access
Overview
- This paper explores how selecting relevant in-context examples can improve the performance of low-resource machine translation models.
- The researchers propose a similarity search-based approach to identify the most relevant examples from a large corpus to include in the model's context.
- They find that this technique leads to significant improvements in translation quality compared to standard fine-tuning approaches, especially for low-resource language pairs.
Plain English Explanation
Machine translation models are trained to translate text from one language to another. However, these models often struggle when translating between languages that have limited available training data, known as "low-resource" language pairs.
The researchers in this paper hypothesized that providing the translation model with relevant examples during inference could help boost its performance on low-resource tasks. To do this, they developed a [object Object] technique to automatically identify the most relevant in-context examples from a large corpus to include alongside the input text.
The key idea is that by surfacing examples that are semantically similar to the current input, the model can leverage this contextual information to generate a higher quality translation, even when limited training data is available. This approach contrasts with standard fine-tuning techniques, which simply train the model on all available data without any dynamic example selection.
Through experiments on several low-resource translation benchmarks, the researchers showed that their similarity search-based approach significantly outperformed standard fine-tuning, leading to [object Object]. This suggests that dynamically selecting relevant in-context examples can be a powerful way to enhance the performance of machine translation models, especially in data-scarce scenarios.
Technical Explanation
The paper proposes an [object Object] approach to improve low-resource machine translation. The core idea is to dynamically retrieve the most relevant in-context examples from a large corpus and incorporate them into the translation model's input during inference.
To achieve this, the researchers first train a base translation model using standard fine-tuning on all available parallel data. They then use a [object Object] technique to identify the top-k most similar examples from a large monolingual corpus for a given input sentence. These examples are then concatenated with the input and fed into the base translation model to generate the final translation.
The similarity search is performed using a cross-lingual sentence embedding model, which allows the system to efficiently retrieve examples that are semantically similar to the input, rather than just lexically similar. The researchers experiment with various similarity scoring functions and find that a simple cosine similarity metric works well in practice.
Through extensive evaluations on several low-resource translation benchmarks, the authors demonstrate that their [object Object] standard fine-tuning baselines, often by a large margin. They attribute this improvement to the model's ability to leverage the relevant in-context information to generate higher quality translations, especially for language pairs with limited training data.
Critical Analysis
The paper presents a compelling approach for improving low-resource machine translation by dynamically selecting relevant in-context examples. The key strength of this work is the [object Object] similarity search-based example selection technique, which allows the model to effectively leverage auxiliary information from a large monolingual corpus.
That said, the authors acknowledge some limitations of their approach. [object Object] as the amount of available parallel data increases, as the base translation model will become stronger and less reliant on the in-context examples.
Additionally, the researchers only evaluated their technique on a limited set of low-resource language pairs, so it remains to be seen how well it would generalize to a broader range of scenarios. There could also be [object Object] introduced by the similarity search approach, which the authors did not fully explore.
Overall, this work presents a promising direction for enhancing low-resource machine translation, but further research is needed to fully understand the strengths, limitations, and broader applicability of this approach.
Conclusion
This paper introduces a novel example selection technique based on similarity search to improve the performance of low-resource machine translation models. By dynamically retrieving the most relevant in-context examples and incorporating them into the model's input, the researchers were able to achieve significant improvements in translation quality compared to standard fine-tuning approaches.
The key insight of this work is that leveraging relevant contextual information, even from monolingual sources, can be a powerful way to compensate for the lack of parallel training data in low-resource settings. As machine translation continues to be an important problem in the field of natural language processing, techniques like the one proposed in this paper could play an increasingly important role in making these models more robust and effective, especially for underserved language pairs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
In-Context Example Selection via Similarity Search Improves Low-Resource Machine Translation
Armel Zebaze, Beno^it Sagot, Rachel Bawden
The ability of generative large language models (LLMs) to perform in-context learning has given rise to a large body of research into how best to prompt models for various natural language processing tasks. In this paper, we focus on machine translation (MT), a task that has been shown to benefit from in-context translation examples. However no systematic studies have been published on how best to select examples, and mixed results have been reported on the usefulness of similarity-based selection over random selection. We provide a study covering multiple LLMs and multiple in-context example retrieval strategies, comparing multilingual sentence embeddings. We cover several language directions, representing different levels of language resourcedness (English into French, German, Swahili and Wolof). Contrarily to previously published results, we find that sentence embedding similarity can improve MT, especially for low-resource language directions, and discuss the balance between selection pool diversity and quality. We also highlight potential problems with the evaluation of LLM-based MT and suggest a more appropriate evaluation protocol, adapting the COMET metric to the evaluation of LLMs. Code and outputs are freely available at https://github.com/ArmelRandy/ICL-MT.
Read more8/2/2024
📈
0
An Empirical Study of In-context Learning in LLMs for Machine Translation
Pranjal A. Chitale, Jay Gala, Raj Dabre
Recent interest has surged in employing Large Language Models (LLMs) for machine translation (MT) via in-context learning (ICL) (Vilar et al., 2023). Most prior studies primarily focus on optimizing translation quality, with limited attention to understanding the specific aspects of ICL that influence the said quality. To this end, we perform the first of its kind, an exhaustive study of in-context learning for machine translation. We first establish that ICL is primarily example-driven and not instruction-driven. Following this, we conduct an extensive exploration of various aspects of the examples to understand their influence on downstream performance. Our analysis includes factors such as quality and quantity of demonstrations, spatial proximity, and source versus target originality. Further, we also investigate challenging scenarios involving indirectness and misalignment of examples to understand the limits of ICL. While we establish the significance of the quality of the target distribution over the source distribution of demonstrations, we further observe that perturbations sometimes act as regularizers, resulting in performance improvements. Surprisingly, ICL does not necessitate examples from the same task, and a related task with the same target distribution proves sufficient. We hope that our study acts as a guiding resource for considerations in utilizing ICL for MT. Our code is available on https://github.com/PranjalChitale/in-context-mt-analysis.
Read more6/6/2024
0
Going Beyond Word Matching: Syntax Improves In-context Example Selection for Machine Translation
Chenming Tang, Zhixiang Wang, Yunfang Wu
In-context learning (ICL) is the trending prompting strategy in the era of large language models (LLMs), where a few examples are demonstrated to evoke LLMs' power for a given task. How to select informative examples remains an open issue. Previous works on in-context example selection for machine translation (MT) focus on superficial word-level features while ignoring deep syntax-level knowledge. In this paper, we propose a syntax-based in-context example selection method for MT, by computing the syntactic similarity between dependency trees using Polynomial Distance. In addition, we propose an ensemble strategy combining examples selected by both word-level and syntax-level criteria. Experimental results between English and 6 common languages indicate that syntax can effectively enhancing ICL for MT, obtaining the highest COMET scores on 11 out of 12 translation directions.
Read more5/30/2024
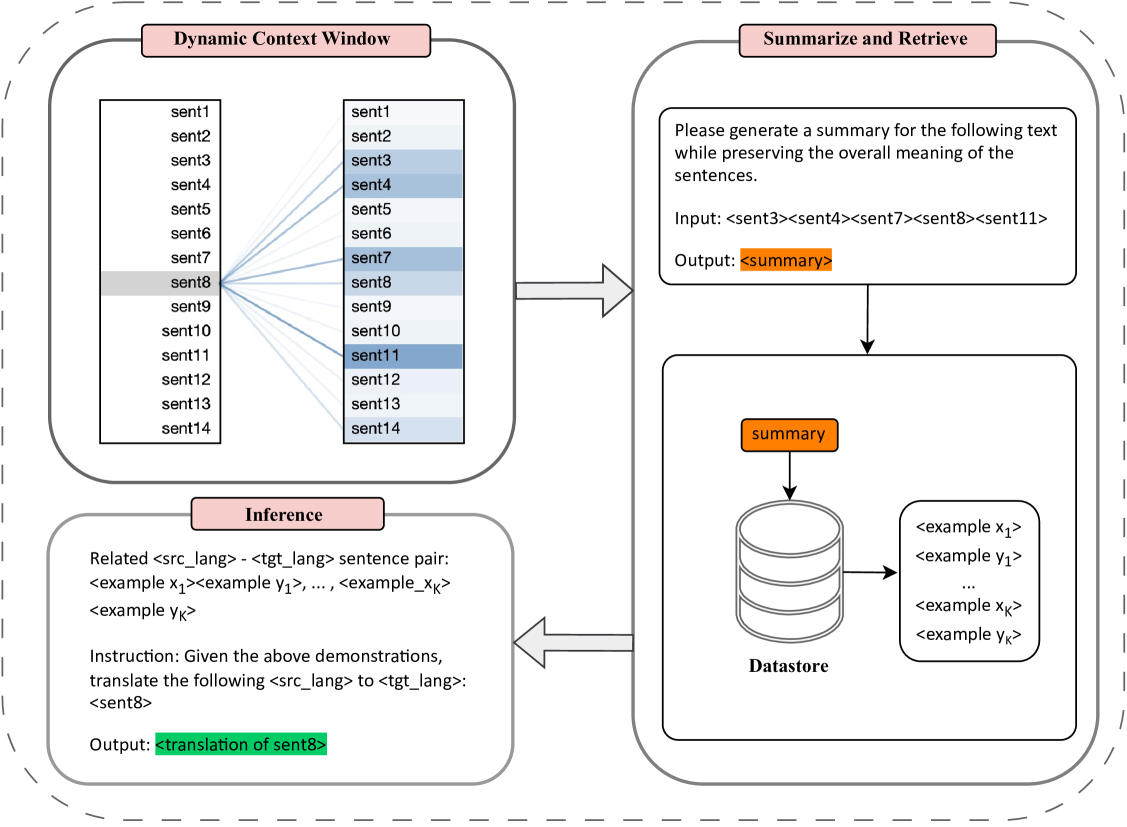
0
Efficiently Exploring Large Language Models for Document-Level Machine Translation with In-context Learning
Menglong Cui, Jiangcun Du, Shaolin Zhu, Deyi Xiong
Large language models (LLMs) exhibit outstanding performance in machine translation via in-context learning. In contrast to sentence-level translation, document-level translation (DOCMT) by LLMs based on in-context learning faces two major challenges: firstly, document translations generated by LLMs are often incoherent; secondly, the length of demonstration for in-context learning is usually limited. To address these issues, we propose a Context-Aware Prompting method (CAP), which enables LLMs to generate more accurate, cohesive, and coherent translations via in-context learning. CAP takes into account multi-level attention, selects the most relevant sentences to the current one as context, and then generates a summary from these collected sentences. Subsequently, sentences most similar to the summary are retrieved from the datastore as demonstrations, which effectively guide LLMs in generating cohesive and coherent translations. We conduct extensive experiments across various DOCMT tasks, and the results demonstrate the effectiveness of our approach, particularly in zero pronoun translation (ZPT) and literary translation tasks.
Read more6/12/2024