Going Beyond Word Matching: Syntax Improves In-context Example Selection for Machine Translation
2403.19285
0
0
Abstract
In-context learning (ICL) is the trending prompting strategy in the era of large language models (LLMs), where a few examples are demonstrated to evoke LLMs' power for a given task. How to select informative examples remains an open issue. Previous works on in-context example selection for machine translation (MT) focus on superficial word-level features while ignoring deep syntax-level knowledge. In this paper, we propose a syntax-based in-context example selection method for MT, by computing the syntactic similarity between dependency trees using Polynomial Distance. In addition, we propose an ensemble strategy combining examples selected by both word-level and syntax-level criteria. Experimental results between English and 6 common languages indicate that syntax can effectively enhancing ICL for MT, obtaining the highest COMET scores on 11 out of 12 translation directions.
Create account to get full access
Overview
- This paper explores how using syntactic information can improve the selection of in-context examples for machine translation, going beyond just word matching.
- The researchers propose a novel approach that incorporates both lexical and syntactic similarity to select the most relevant examples for a given translation task.
- Their experiments show that this combined approach outperforms previous methods that rely solely on word-level matching.
Plain English Explanation
When translating text from one language to another, it can be helpful to have examples of similar sentences that have already been translated. These examples can provide useful context and guidance for the machine translation system. However, simply matching words between the input and example sentences may not be enough to find the most relevant examples.
This paper suggests that looking at the overall syntactic structure of the sentences, not just the individual words, can provide valuable additional information. By considering both the words used and the grammatical structure of the sentences, the researchers were able to more accurately identify examples that would be most helpful for translating a given input.
Their approach uses machine learning techniques to analyze the syntax and semantics of the sentences, going beyond just looking for matching keywords. This allows the system to find examples that may use different words but have a similar overall structure, which can be very useful for translation.
The key idea is that the context provided by relevant example sentences can greatly improve the quality of machine translations, but to get the most benefit, the examples need to be well-matched to the input both lexically and syntactically. This paper demonstrates a way to achieve that by considering the full linguistic structure of the sentences, not just the surface-level word choices.
Technical Explanation
The researchers propose a novel approach for selecting the most relevant in-context examples to assist with machine translation tasks. Their method incorporates both lexical (word-level) and syntactic similarity to identify the examples that best match the input sentence.
Traditionally, example selection for machine translation has relied primarily on word-level matching between the input and candidate examples. However, the authors argue that this can miss important structural similarities that are crucial for providing appropriate context.
Their system first parses the input and example sentences to extract their syntactic structures. It then computes a combined similarity score that takes into account both the lexical overlap and the syntactic alignment between the sentences. The most similar examples, as determined by this hybrid similarity metric, are then selected to provide contextual information for the translation.
The researchers evaluate their approach on several machine translation benchmarks, comparing it to previous methods that use only word-level matching. Their experiments demonstrate that the combined lexical and syntactic similarity leads to significant improvements in translation quality, as measured by standard evaluation metrics.
Critical Analysis
The paper makes a compelling case for the importance of considering syntactic structure, beyond just lexical content, when selecting examples to inform machine translation. The authors provide a thorough technical description of their approach and present convincing experimental results to support their claims.
That said, the paper does not delve into potential limitations or caveats of their method. For example, it would be helpful to understand how their system might perform on more complex or ambiguous sentences, where the syntactic analysis could be more challenging. Additionally, the paper does not discuss how the approach might scale to very large example databases or handle multiple languages.
Further research could also explore ways to integrate the syntactic similarity measures more seamlessly into the overall machine translation pipeline, rather than treating example selection as a separate preprocessing step. This could potentially lead to even greater gains in translation quality.
Overall, this paper represents an important step forward in leveraging syntactic information to improve context-aware machine translation. While there are still opportunities for refinement and extension, the authors have demonstrated the value of moving beyond simple word-level matching to capture the deeper linguistic structures that are crucial for effective translation.
Conclusion
This paper presents a novel approach for selecting the most relevant in-context examples to assist with machine translation. By incorporating both lexical and syntactic similarity, the researchers were able to identify examples that better match the input sentences, leading to significant improvements in translation quality.
The key insight is that the grammatical structure of sentences, not just the individual words used, can provide valuable context for translation tasks. The authors' hybrid similarity metric, which considers both word-level and syntactic information, represents an important advance in example-based machine translation.
While there are opportunities for further refinement and exploration, this work highlights the importance of moving beyond surface-level matching to capture the deeper linguistic characteristics that are crucial for effective translation. As machine translation systems continue to evolve, incorporating syntactic awareness will likely become an increasingly important capability.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
An Empirical Study of In-context Learning in LLMs for Machine Translation
Pranjal A. Chitale, Jay Gala, Raj Dabre
0
0
Recent interest has surged in employing Large Language Models (LLMs) for machine translation (MT) via in-context learning (ICL) (Vilar et al., 2023). Most prior studies primarily focus on optimizing translation quality, with limited attention to understanding the specific aspects of ICL that influence the said quality. To this end, we perform the first of its kind, an exhaustive study of in-context learning for machine translation. We first establish that ICL is primarily example-driven and not instruction-driven. Following this, we conduct an extensive exploration of various aspects of the examples to understand their influence on downstream performance. Our analysis includes factors such as quality and quantity of demonstrations, spatial proximity, and source versus target originality. Further, we also investigate challenging scenarios involving indirectness and misalignment of examples to understand the limits of ICL. While we establish the significance of the quality of the target distribution over the source distribution of demonstrations, we further observe that perturbations sometimes act as regularizers, resulting in performance improvements. Surprisingly, ICL does not necessitate examples from the same task, and a related task with the same target distribution proves sufficient. We hope that our study acts as a guiding resource for considerations in utilizing ICL for MT. Our code is available on https://github.com/PranjalChitale/in-context-mt-analysis.
6/6/2024
🌿
A Survey on In-context Learning
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Baobao Chang, Xu Sun, Lei Li, Zhifang Sui
0
0
With the increasing capabilities of large language models (LLMs), in-context learning (ICL) has emerged as a new paradigm for natural language processing (NLP), where LLMs make predictions based on contexts augmented with a few examples. It has been a significant trend to explore ICL to evaluate and extrapolate the ability of LLMs. In this paper, we aim to survey and summarize the progress and challenges of ICL. We first present a formal definition of ICL and clarify its correlation to related studies. Then, we organize and discuss advanced techniques, including training strategies, prompt designing strategies, and related analysis. Additionally, we explore various ICL application scenarios, such as data engineering and knowledge updating. Finally, we address the challenges of ICL and suggest potential directions for further research. We hope that our work can encourage more research on uncovering how ICL works and improving ICL.
6/19/2024
🌀
In-context Learning Generalizes, But Not Always Robustly: The Case of Syntax
Aaron Mueller, Albert Webson, Jackson Petty, Tal Linzen
0
0
In-context learning (ICL) is now a common method for teaching large language models (LLMs) new tasks: given labeled examples in the input context, the LLM learns to perform the task without weight updates. Do models guided via ICL infer the underlying structure of the task defined by the context, or do they rely on superficial heuristics that only generalize to identically distributed examples? We address this question using transformations tasks and an NLI task that assess sensitivity to syntax - a requirement for robust language understanding. We further investigate whether out-of-distribution generalization can be improved via chain-of-thought prompting, where the model is provided with a sequence of intermediate computation steps that illustrate how the task ought to be performed. In experiments with models from the GPT, PaLM, and Llama 2 families, we find large variance across LMs. The variance is explained more by the composition of the pre-training corpus and supervision methods than by model size; in particular, models pre-trained on code generalize better, and benefit more from chain-of-thought prompting.
4/11/2024
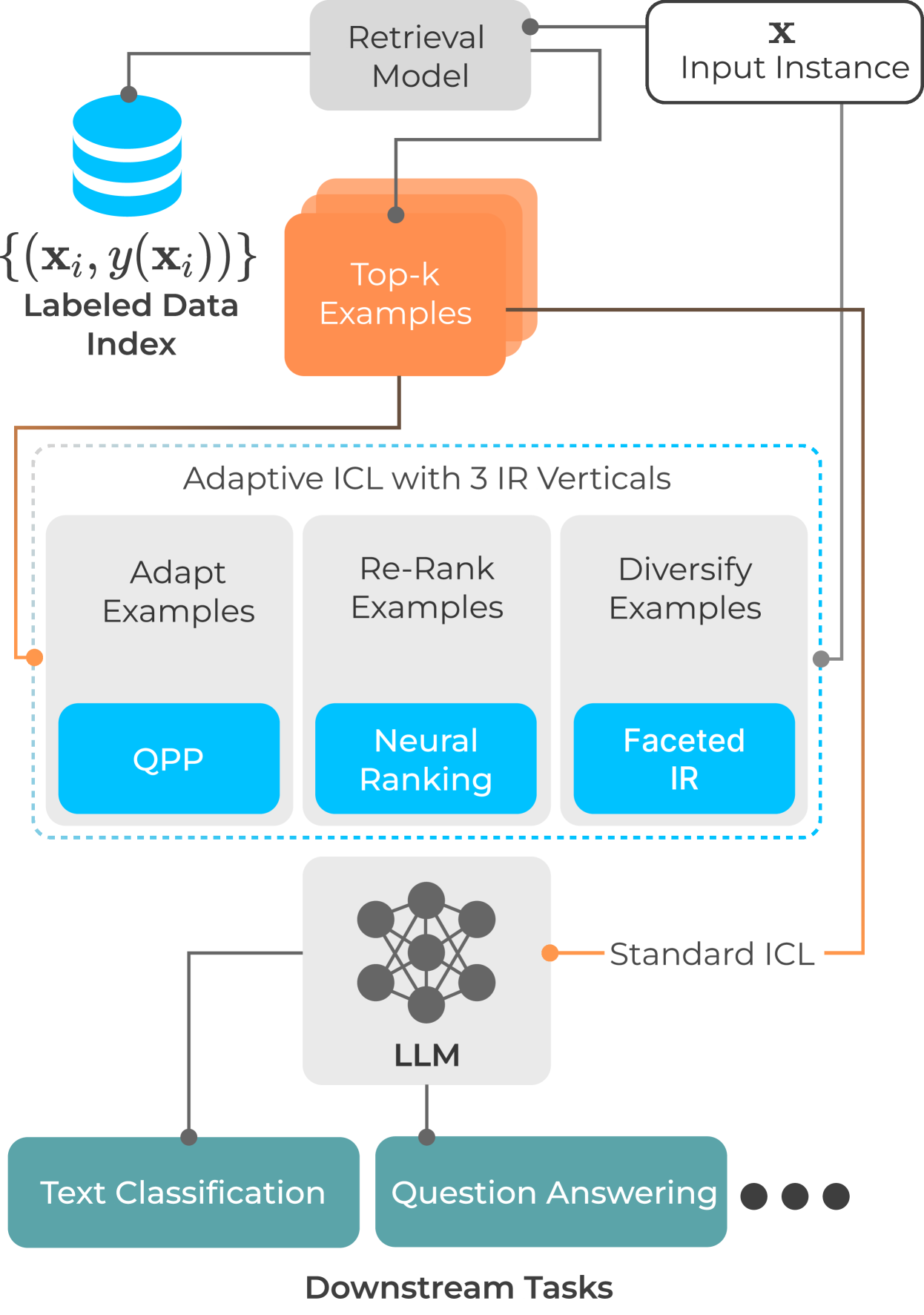
In-Context Learning or: How I learned to stop worrying and love Applied Information Retrieval
Andrew Parry, Debasis Ganguly, Manish Chandra
0
0
With the increasing ability of large language models (LLMs), in-context learning (ICL) has evolved as a new paradigm for natural language processing (NLP), where instead of fine-tuning the parameters of an LLM specific to a downstream task with labeled examples, a small number of such examples is appended to a prompt instruction for controlling the decoder's generation process. ICL, thus, is conceptually similar to a non-parametric approach, such as $k$-NN, where the prediction for each instance essentially depends on the local topology, i.e., on a localised set of similar instances and their labels (called few-shot examples). This suggests that a test instance in ICL is analogous to a query in IR, and similar examples in ICL retrieved from a training set relate to a set of documents retrieved from a collection in IR. While standard unsupervised ranking models can be used to retrieve these few-shot examples from a training set, the effectiveness of the examples can potentially be improved by re-defining the notion of relevance specific to its utility for the downstream task, i.e., considering an example to be relevant if including it in the prompt instruction leads to a correct prediction. With this task-specific notion of relevance, it is possible to train a supervised ranking model (e.g., a bi-encoder or cross-encoder), which potentially learns to optimally select the few-shot examples. We believe that the recent advances in neural rankers can potentially find a use case for this task of optimally choosing examples for more effective downstream ICL predictions.
5/3/2024