Context-Specific Refinements of Bayesian Network Classifiers
2405.18298
0
0

Abstract
Supervised classification is one of the most ubiquitous tasks in machine learning. Generative classifiers based on Bayesian networks are often used because of their interpretability and competitive accuracy. The widely used naive and TAN classifiers are specific instances of Bayesian network classifiers with a constrained underlying graph. This paper introduces novel classes of generative classifiers extending TAN and other famous types of Bayesian network classifiers. Our approach is based on staged tree models, which extend Bayesian networks by allowing for complex, context-specific patterns of dependence. We formally study the relationship between our novel classes of classifiers and Bayesian networks. We introduce and implement data-driven learning routines for our models and investigate their accuracy in an extensive computational study. The study demonstrates that models embedding asymmetric information can enhance classification accuracy.
Create account to get full access
Overview
- Bayesian network classifiers are a type of machine learning model that use Bayesian probability to make predictions.
- This paper proposes a method for refining Bayesian network classifiers to improve their performance in specific contexts.
- The key idea is to use context-specific information to selectively refine parts of the Bayesian network rather than updating the entire model.
Plain English Explanation
Bayesian network classifiers are a kind of machine learning model that use probability to make predictions. This paper suggests a way to improve the performance of these models in certain situations. The main idea is to use information about the specific context to selectively refine or update parts of the Bayesian network, rather than changing the entire model.
For example, imagine you have a Bayesian network that predicts whether a patient has a certain disease based on their symptoms. In a hospital setting, the model might perform well. But in a community health clinic, the patient population and symptoms could be different, so the model may not work as well. The approach in this paper would allow you to refine the model for the community health clinic context, without having to rebuild the entire network from scratch.
This selective refinement can make the Bayesian network classifiers more accurate and useful in a variety of real-world applications, like disease diagnosis or image recognition, where the context can vary.
Technical Explanation
The key innovation in this paper is a method for context-specific refinements of Bayesian network classifiers. The authors propose a framework that allows selective updates to the parameters of a Bayesian network model based on the current context, rather than updating the entire model.
Specifically, the authors introduce a set of context-specific parameter refinement functions that can be applied to targeted parts of the Bayesian network. These functions leverage information about the current context, such as the distribution of input features or the class priors, to adjust the model parameters in a way that improves performance for that particular setting.
The authors demonstrate the effectiveness of their approach through experiments on several real-world datasets, including tasks in disease diagnosis and image recognition. They show that the context-specific refinements can lead to significant improvements in classification accuracy compared to standard Bayesian network classifiers or global model updates.
Critical Analysis
One potential limitation of the proposed approach is that it requires the availability of contextual information to guide the refinement process. In some applications, this contextual data may not be readily available or easily incorporated into the model. The authors acknowledge this and suggest that further research is needed to explore ways of automatically identifying relevant context or learning the refinement functions in a more data-driven manner.
Additionally, the computational overhead of the context-specific refinements may be a concern, especially for large-scale or real-time applications. The authors do not provide a detailed analysis of the computational complexity or runtime implications of their approach, which would be useful for assessing its practical feasibility.
Overall, the context-specific refinements proposed in this paper represent a promising direction for improving the performance of Bayesian network classifiers in diverse real-world settings. However, further research is needed to address the potential limitations and ensure the approach is scalable and practical for a wide range of applications.
Conclusion
This paper presents a method for refining Bayesian network classifiers in a context-specific manner, allowing the model to be selectively updated to improve performance in different settings. By leveraging information about the current context, the approach can make targeted adjustments to the Bayesian network rather than requiring a complete model update.
The proposed context-specific refinements have the potential to enhance the real-world applicability of Bayesian network classifiers, making them more robust and adaptable to diverse use cases, such as disease diagnosis and image recognition. Further research is needed to address the potential limitations and ensure the scalability and practicality of this approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Implicit Generative Prior for Bayesian Neural Networks
Yijia Liu, Xiao Wang
0
0
Predictive uncertainty quantification is crucial for reliable decision-making in various applied domains. Bayesian neural networks offer a powerful framework for this task. However, defining meaningful priors and ensuring computational efficiency remain significant challenges, especially for complex real-world applications. This paper addresses these challenges by proposing a novel neural adaptive empirical Bayes (NA-EB) framework. NA-EB leverages a class of implicit generative priors derived from low-dimensional distributions. This allows for efficient handling of complex data structures and effective capture of underlying relationships in real-world datasets. The proposed NA-EB framework combines variational inference with a gradient ascent algorithm. This enables simultaneous hyperparameter selection and approximation of the posterior distribution, leading to improved computational efficiency. We establish the theoretical foundation of the framework through posterior and classification consistency. We demonstrate the practical applications of our framework through extensive evaluations on a variety of tasks, including the two-spiral problem, regression, 10 UCI datasets, and image classification tasks on both MNIST and CIFAR-10 datasets. The results of our experiments highlight the superiority of our proposed framework over existing methods, such as sparse variational Bayesian and generative models, in terms of prediction accuracy and uncertainty quantification.
4/30/2024
🛠️
The Bayesian Learning Rule
Mohammad Emtiyaz Khan, H{aa}vard Rue
0
0
We show that many machine-learning algorithms are specific instances of a single algorithm called the emph{Bayesian learning rule}. The rule, derived from Bayesian principles, yields a wide-range of algorithms from fields such as optimization, deep learning, and graphical models. This includes classical algorithms such as ridge regression, Newton's method, and Kalman filter, as well as modern deep-learning algorithms such as stochastic-gradient descent, RMSprop, and Dropout. The key idea in deriving such algorithms is to approximate the posterior using candidate distributions estimated by using natural gradients. Different candidate distributions result in different algorithms and further approximations to natural gradients give rise to variants of those algorithms. Our work not only unifies, generalizes, and improves existing algorithms, but also helps us design new ones.
6/11/2024
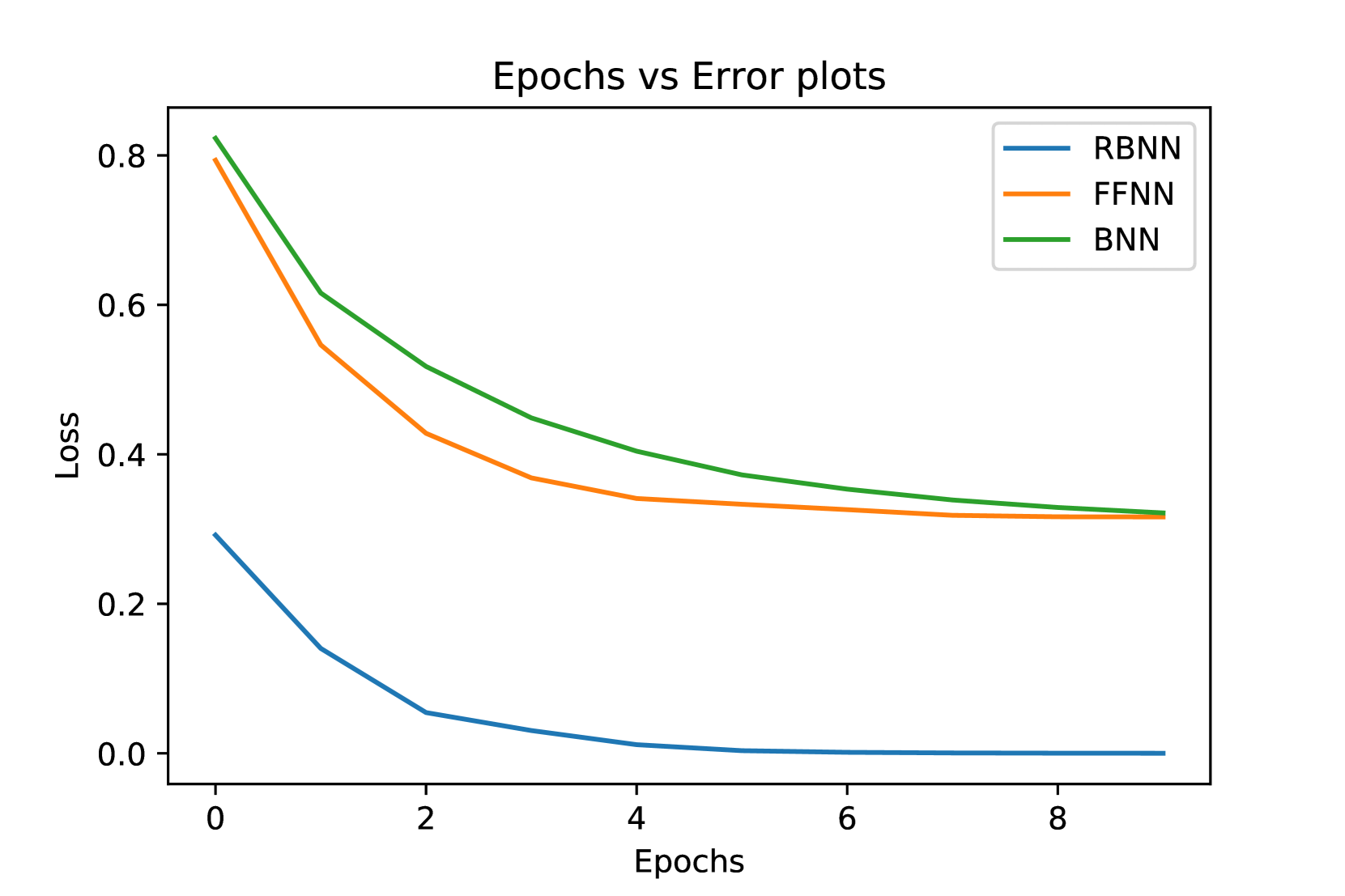
Restricted Bayesian Neural Network
Sourav Ganguly, Saprativa Bhattacharjee
0
0
Modern deep learning tools are remarkably effective in addressing intricate problems. However, their operation as black-box models introduces increased uncertainty in predictions. Additionally, they contend with various challenges, including the need for substantial storage space in large networks, issues of overfitting, underfitting, vanishing gradients, and more. This study explores the concept of Bayesian Neural Networks, presenting a novel architecture designed to significantly alleviate the storage space complexity of a network. Furthermore, we introduce an algorithm adept at efficiently handling uncertainties, ensuring robust convergence values without becoming trapped in local optima, particularly when the objective function lacks perfect convexity.
4/9/2024

Flexible inference in heterogeneous and attributed multilayer networks
Martina Contisciani, Marius Hobbhahn, Eleanor A. Power, Philipp Hennig, Caterina De Bacco
0
0
Networked datasets are often enriched by different types of information about individual nodes or edges. However, most existing methods for analyzing such datasets struggle to handle the complexity of heterogeneous data, often requiring substantial model-specific analysis. In this paper, we develop a probabilistic generative model to perform inference in multilayer networks with arbitrary types of information. Our approach employs a Bayesian framework combined with the Laplace matching technique to ease interpretation of inferred parameters. Furthermore, the algorithmic implementation relies on automatic differentiation, avoiding the need for explicit derivations. This makes our model scalable and flexible to adapt to any combination of input data. We demonstrate the effectiveness of our method in detecting overlapping community structures and performing various prediction tasks on heterogeneous multilayer data, where nodes and edges have different types of attributes. Additionally, we showcase its ability to unveil a variety of patterns in a social support network among villagers in rural India by effectively utilizing all input information in a meaningful way.
6/3/2024