Understanding Different Design Choices in Training Large Time Series Models
2406.14045
0
0
Abstract
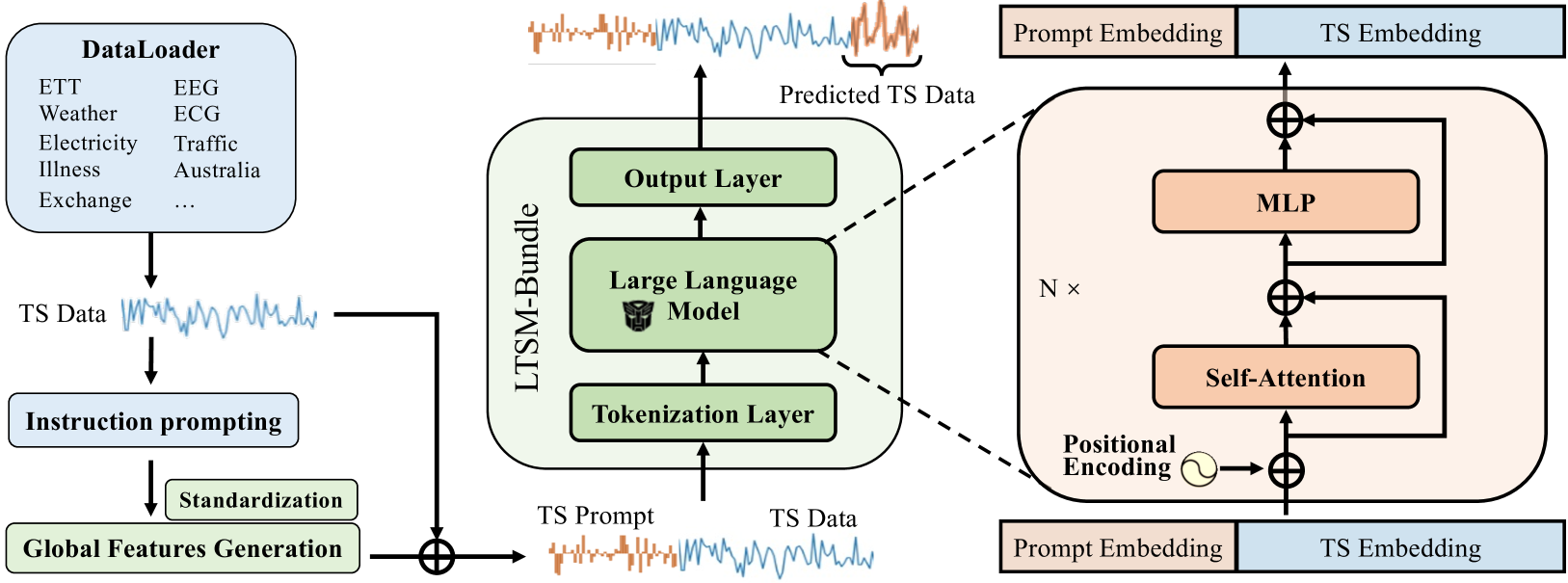
Inspired by Large Language Models (LLMs), Time Series Forecasting (TSF), a long-standing task in time series analysis, is undergoing a transition towards Large Time Series Models (LTSMs), aiming to train universal transformer-based models for TSF. However, training LTSMs on heterogeneous time series data poses unique challenges, including diverse frequencies, dimensions, and patterns across datasets. Recent endeavors have studied and evaluated various design choices aimed at enhancing LTSM training and generalization capabilities, spanning pre-processing techniques, model configurations, and dataset configurations. In this work, we comprehensively analyze these design choices and aim to identify the best practices for training LTSM. Moreover, we propose emph{time series prompt}, a novel statistical prompting strategy tailored to time series data. Furthermore, based on the observations in our analysis, we introduce texttt{LTSM-bundle}, which bundles the best design choices we have identified. Empirical results demonstrate that texttt{LTSM-bundle} achieves superior zero-shot and few-shot performances compared to state-of-the-art LSTMs and traditional TSF methods on benchmark datasets.
Create account to get full access
Overview
- This paper examines different design choices when training large time series models, which are machine learning models used to make predictions on time-varying data.
- The authors explore factors like model architecture, training data, and hyperparameter tuning to understand their impact on the performance of these models.
- They aim to provide guidance for researchers and practitioners on effective strategies for building high-performing time series models at scale.
Plain English Explanation
Time series data, which shows how a variable changes over time, is common in fields like finance, weather forecasting, and manufacturing. Large language models for time series have proven effective at making predictions on this type of data. However, designing and training these large models involves many complex choices.
This paper investigates several of those design choices to understand their impact on model performance. For example, the authors explore how the model architecture - the specific neural network layers and connections - affects the accuracy of time series forecasts. They also look at how the quantity and characteristics of the training data, as well as hyperparameter tuning (adjusting the model's internal settings), influence the model's capabilities.
By systematically analyzing these factors, the researchers aim to provide guidance to others building large time series models. The insights from this work can help practitioners make more informed decisions about model design and training to improve the real-world performance of their time series forecasting systems.
Technical Explanation
The paper begins by defining the time series forecasting problem and introducing key notations and assumptions. The authors then describe several model design choices they investigate:
-
Model Architecture: The paper compares the performance of different transformer-based architectures, including TimeCMA and TIMER, for time series forecasting tasks.
-
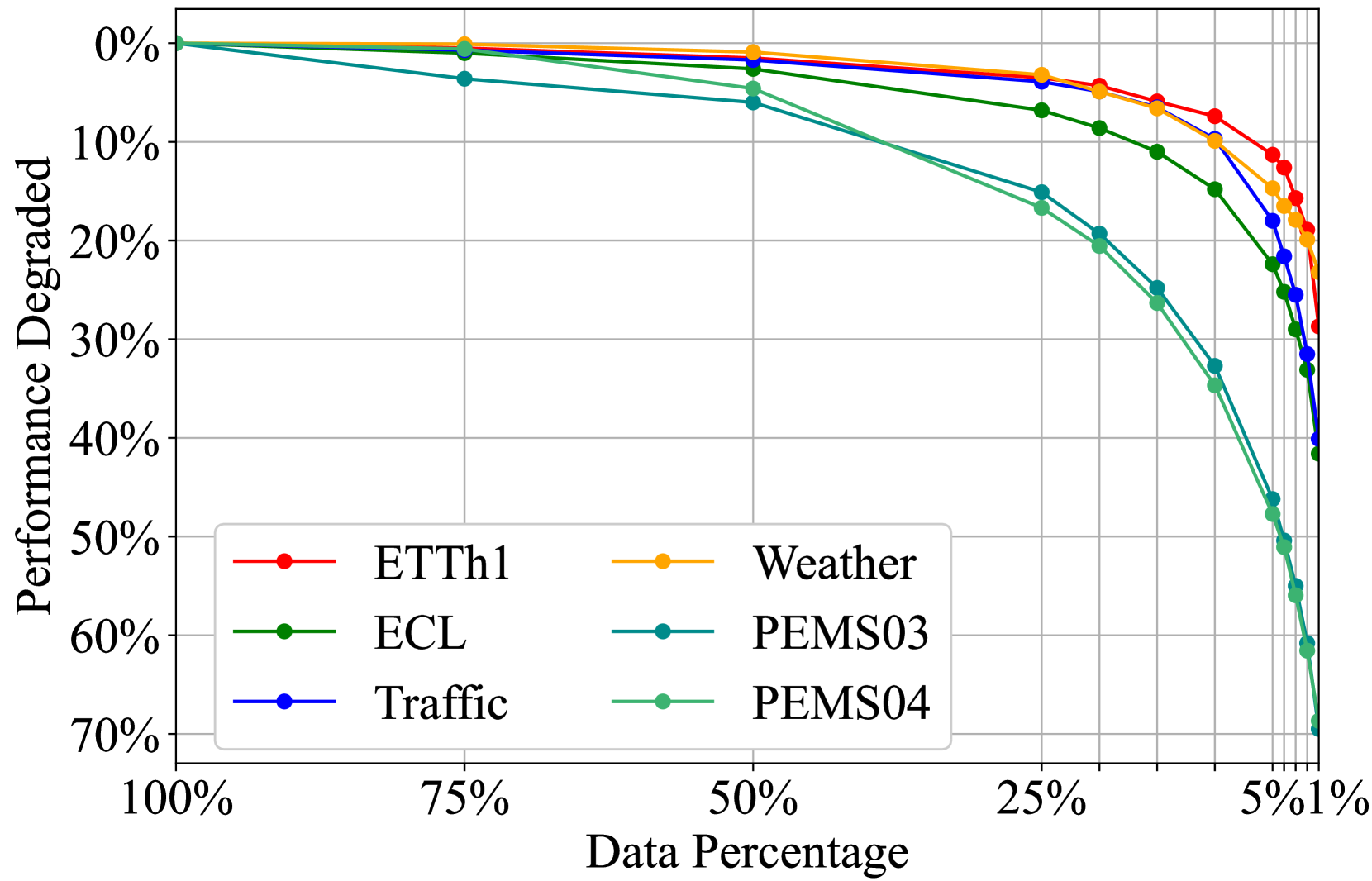
Training Data: The researchers experiment with varying the amount and characteristics of the training data, including dataset size, temporal granularity, and the presence of missing values.
-
Hyperparameter Tuning: The paper explores the impact of tuning hyperparameters like learning rate, batch size, and the number of training epochs on model performance.
The authors conduct extensive experiments on several real-world time series datasets to assess the effects of these design choices. They report metrics like mean squared error and R-squared to evaluate the models' forecasting accuracy.
The results indicate that model architecture, training data, and hyperparameter tuning can all significantly impact the performance of large time series models. The paper provides practical guidance and recommendations for practitioners based on these findings.
Critical Analysis
The paper provides a thorough and systematic investigation of important design choices for training large time series models. The experimental setup is well-designed, and the authors clearly communicate the motivations, methods, and key insights from their work.
One potential limitation is the focus on transformer-based architectures, which may not capture all the relevant design considerations for time series modeling. The authors acknowledge this and suggest exploring other model types, such as recurrent neural networks, as an area for future research.
Additionally, the paper does not delve deeply into the underlying reasons why certain design choices lead to improved performance. A more in-depth analysis of the mechanisms and trade-offs involved could further strengthen the practical utility of the findings.
Overall, this work makes a valuable contribution to the understanding of effective strategies for training large-scale time series models. The insights provided can help researchers and practitioners navigate the complex design space and develop more accurate and robust forecasting systems.
Conclusion
This paper offers a comprehensive study of key design choices in training large time series models, a crucial task for many real-world applications. By systematically analyzing the impact of model architecture, training data, and hyperparameter tuning, the authors provide valuable guidance to help practitioners build high-performing time series forecasting systems.
The findings demonstrate the significant influence that various design factors can have on model performance, underscoring the importance of careful consideration and experimentation when developing large-scale time series models. The insights from this work can inform the development of more accurate and robust time series forecasting capabilities, with potential benefits across a wide range of industries and domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Large Language Models for Time Series: A Survey
Xiyuan Zhang, Ranak Roy Chowdhury, Rajesh K. Gupta, Jingbo Shang
0
0
Large Language Models (LLMs) have seen significant use in domains such as natural language processing and computer vision. Going beyond text, image and graphics, LLMs present a significant potential for analysis of time series data, benefiting domains such as climate, IoT, healthcare, traffic, audio and finance. This survey paper provides an in-depth exploration and a detailed taxonomy of the various methodologies employed to harness the power of LLMs for time series analysis. We address the inherent challenge of bridging the gap between LLMs' original text data training and the numerical nature of time series data, and explore strategies for transferring and distilling knowledge from LLMs to numerical time series analysis. We detail various methodologies, including (1) direct prompting of LLMs, (2) time series quantization, (3) aligning techniques, (4) utilization of the vision modality as a bridging mechanism, and (5) the combination of LLMs with tools. Additionally, this survey offers a comprehensive overview of the existing multimodal time series and text datasets and delves into the challenges and future opportunities of this emerging field. We maintain an up-to-date Github repository which includes all the papers and datasets discussed in the survey.
5/8/2024
Timer: Generative Pre-trained Transformers Are Large Time Series Models
Yong Liu, Haoran Zhang, Chenyu Li, Xiangdong Huang, Jianmin Wang, Mingsheng Long
0
0
Deep learning has contributed remarkably to the advancement of time series analysis. Still, deep models can encounter performance bottlenecks in real-world data-scarce scenarios, which can be concealed due to the performance saturation with small models on current benchmarks. Meanwhile, large models have demonstrated great powers in these scenarios through large-scale pre-training. Continuous progress has been achieved with the emergence of large language models, exhibiting unprecedented abilities such as few-shot generalization, scalability, and task generality, which are however absent in small deep models. To change the status quo of training scenario-specific small models from scratch, this paper aims at the early development of large time series models (LTSM). During pre-training, we curate large-scale datasets with up to 1 billion time points, unify heterogeneous time series into single-series sequence (S3) format, and develop the GPT-style architecture toward LTSMs. To meet diverse application needs, we convert forecasting, imputation, and anomaly detection of time series into a unified generative task. The outcome of this study is a Time Series Transformer (Timer), which is generative pre-trained by next token prediction and adapted to various downstream tasks with promising capabilities as an LTSM. Code and datasets are available at: https://github.com/thuml/Large-Time-Series-Model.
6/5/2024

A Survey of Time Series Foundation Models: Generalizing Time Series Representation with Large Language Mode
Jiexia Ye, Weiqi Zhang, Ke Yi, Yongzi Yu, Ziyue Li, Jia Li, Fugee Tsung
0
0
Time series data are ubiquitous across various domains, making time series analysis critically important. Traditional time series models are task-specific, featuring singular functionality and limited generalization capacity. Recently, large language foundation models have unveiled their remarkable capabilities for cross-task transferability, zero-shot/few-shot learning, and decision-making explainability. This success has sparked interest in the exploration of foundation models to solve multiple time series challenges simultaneously. There are two main research lines, namely pre-training foundation models from scratch for time series and adapting large language foundation models for time series. They both contribute to the development of a unified model that is highly generalizable, versatile, and comprehensible for time series analysis. This survey offers a 3E analytical framework for comprehensive examination of related research. Specifically, we examine existing works from three dimensions, namely Effectiveness, Efficiency and Explainability. In each dimension, we focus on discussing how related works devise tailored solution by considering unique challenges in the realm of time series. Furthermore, we provide a domain taxonomy to help followers keep up with the domain-specific advancements. In addition, we introduce extensive resources to facilitate the field's development, including datasets, open-source, time series libraries. A GitHub repository is also maintained for resource updates (https://github.com/start2020/Awesome-TimeSeries-LLM-FM).
5/8/2024

Large Language Models Are Zero-Shot Time Series Forecasters
Nate Gruver, Marc Finzi, Shikai Qiu, Andrew Gordon Wilson
0
0
By encoding time series as a string of numerical digits, we can frame time series forecasting as next-token prediction in text. Developing this approach, we find that large language models (LLMs) such as GPT-3 and LLaMA-2 can surprisingly zero-shot extrapolate time series at a level comparable to or exceeding the performance of purpose-built time series models trained on the downstream tasks. To facilitate this performance, we propose procedures for effectively tokenizing time series data and converting discrete distributions over tokens into highly flexible densities over continuous values. We argue the success of LLMs for time series stems from their ability to naturally represent multimodal distributions, in conjunction with biases for simplicity, and repetition, which align with the salient features in many time series, such as repeated seasonal trends. We also show how LLMs can naturally handle missing data without imputation through non-numerical text, accommodate textual side information, and answer questions to help explain predictions. While we find that increasing model size generally improves performance on time series, we show GPT-4 can perform worse than GPT-3 because of how it tokenizes numbers, and poor uncertainty calibration, which is likely the result of alignment interventions such as RLHF.
6/19/2024