Transformers Learn Temporal Difference Methods for In-Context Reinforcement Learning

0
🏅
Sign in to get full access
Overview
- In-context learning refers to a model's ability to learn and apply new information during inference, without needing to update its parameters.
- The model is given both a context (previous instance-label pairs) and a new query instance, and can then output a label for the query based on the provided context.
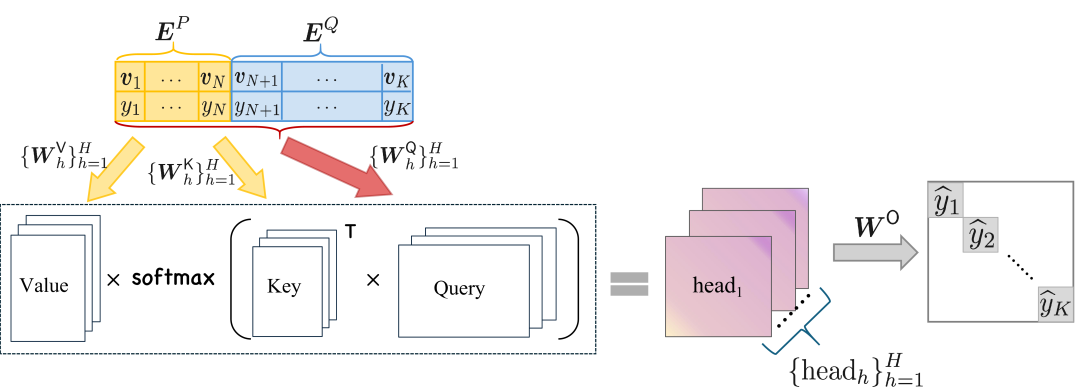
- This paper explores the theoretical underpinnings of in-context learning, showing that transformers can implement various reinforcement learning algorithms, like temporal difference (TD) learning, within their forward pass.
Plain English Explanation
Imagine you have a friend who is really good at math. They can quickly solve complex equations just by looking at them, without needing to do any extra training or practice beforehand. This is similar to how in-context learning works in artificial intelligence (AI) models like transformers.
These models are able to take in some background information or "context" (like previous math problems and their solutions) and then use that context to solve a new, related problem that they're presented with. They don't need to go back and re-train on all the old problems - they can just apply what they've learned from the context to the new situation.
This paper looks at how transformers are able to do this kind of in-context learning. The researchers show that the way the transformer model is set up, it can actually implement different types of learning algorithms, like temporal difference (TD) learning, within its own forward pass. This helps explain how transformers can be so good at quickly adapting to new information.
The paper also explores how transformers might be able to implement other learning algorithms, like residual gradient and average-reward TD, in a similar way. Overall, it provides some important insights into the inner workings of these powerful AI models and how they're able to learn and adapt so effectively.
Technical Explanation
The key idea behind in-context learning is that a model, like a transformer, can utilize the information provided in the input (the "context") to generate an output for a new query, without needing to update its own parameters.
The context typically consists of a set of instance-label pairs, which the model can then use to infer the appropriate label for a new query instance. Previous research has suggested that the forward pass of linear transformers may implement iterations of gradient descent on the context information.
This paper takes the analysis a step further, proving that transformers can also implement temporal difference (TD) learning within their forward pass. The researchers demonstrate this by training a transformer model using a multi-task TD algorithm, which leads to the emergence of in-context TD learning.
Furthermore, the paper shows that transformers are expressive enough to implement a variety of other policy evaluation algorithms, including residual gradient, TD with eligibility trace, and average-reward TD. This suggests that the in-context learning capabilities of transformers are quite general and versatile.
Critical Analysis
The paper provides a strong theoretical foundation for understanding the in-context learning abilities of transformer models. By proving that transformers can implement various reinforcement learning algorithms, the authors offer valuable insights into the inner workings of these models.
However, it's important to note that the analysis is primarily focused on the theoretical aspects and does not include extensive empirical evaluations. While the authors demonstrate the emergence of in-context TD learning, it would be helpful to see how this capability translates to real-world applications and whether it provides tangible performance benefits over other learning approaches.
Additionally, the paper does not address potential limitations or caveats of the in-context learning framework. For example, it's unclear how the performance of in-context learning might scale as the complexity of the context or the query increases, or how sensitive the approach is to the quality and diversity of the context information.
Further research could explore the practical implications of in-context learning, investigate its performance on a wider range of tasks, and address any potential shortcomings or edge cases. Nonetheless, this paper lays an important foundation for understanding the inner workings of transformer models and their ability to adapt to new information during inference.
Conclusion
This paper presents a compelling analysis of the in-context learning capabilities of transformer models. By showing that transformers can implement various reinforcement learning algorithms, such as temporal difference (TD) learning, within their forward pass, the authors provide a deeper understanding of how these models are able to adapt to new information without updating their parameters.
The findings have the potential to impact the way we design and utilize transformer-based models, especially in applications where the ability to quickly incorporate new context information is critical. Additionally, the insights gained from this research could inform the development of even more powerful and versatile AI systems in the future.
Overall, this paper makes a significant contribution to the field of machine learning by shedding light on the powerful in-context learning capabilities of transformers and opening up new avenues for further exploration and innovation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
0
Transformers Learn Temporal Difference Methods for In-Context Reinforcement Learning
Jiuqi Wang, Ethan Blaser, Hadi Daneshmand, Shangtong Zhang
In-context learning refers to the learning ability of a model during inference time without adapting its parameters. The input (i.e., prompt) to the model (e.g., transformers) consists of both a context (i.e., instance-label pairs) and a query instance. The model is then able to output a label for the query instance according to the context during inference. A possible explanation for in-context learning is that the forward pass of (linear) transformers implements iterations of gradient descent on the instance-label pairs in the context. In this paper, we prove by construction that transformers can also implement temporal difference (TD) learning in the forward pass, a phenomenon we refer to as in-context TD. We demonstrate the emergence of in-context TD after training the transformer with a multi-task TD algorithm, accompanied by theoretical analysis. Furthermore, we prove that transformers are expressive enough to implement many other policy evaluation algorithms in the forward pass, including residual gradient, TD with eligibility trace, and average-reward TD.
Read more8/2/2024

0
In-context Time Series Predictor
Jiecheng Lu, Yan Sun, Shihao Yang
Recent Transformer-based large language models (LLMs) demonstrate in-context learning ability to perform various functions based solely on the provided context, without updating model parameters. To fully utilize the in-context capabilities in time series forecasting (TSF) problems, unlike previous Transformer-based or LLM-based time series forecasting methods, we reformulate time series forecasting tasks as input tokens by constructing a series of (lookback, future) pairs within the tokens. This method aligns more closely with the inherent in-context mechanisms, and is more parameter-efficient without the need of using pre-trained LLM parameters. Furthermore, it addresses issues such as overfitting in existing Transformer-based TSF models, consistently achieving better performance across full-data, few-shot, and zero-shot settings compared to previous architectures.
Read more5/27/2024
0
In-Context Learning with Representations: Contextual Generalization of Trained Transformers
Tong Yang, Yu Huang, Yingbin Liang, Yuejie Chi
In-context learning (ICL) refers to a remarkable capability of pretrained large language models, which can learn a new task given a few examples during inference. However, theoretical understanding of ICL is largely under-explored, particularly whether transformers can be trained to generalize to unseen examples in a prompt, which will require the model to acquire contextual knowledge of the prompt for generalization. This paper investigates the training dynamics of transformers by gradient descent through the lens of non-linear regression tasks. The contextual generalization here can be attained via learning the template function for each task in-context, where all template functions lie in a linear space with $m$ basis functions. We analyze the training dynamics of one-layer multi-head transformers to in-contextly predict unlabeled inputs given partially labeled prompts, where the labels contain Gaussian noise and the number of examples in each prompt are not sufficient to determine the template. Under mild assumptions, we show that the training loss for a one-layer multi-head transformer converges linearly to a global minimum. Moreover, the transformer effectively learns to perform ridge regression over the basis functions. To our knowledge, this study is the first provable demonstration that transformers can learn contextual (i.e., template) information to generalize to both unseen examples and tasks when prompts contain only a small number of query-answer pairs.
Read more9/27/2024

0
In-Context Decision Transformer: Reinforcement Learning via Hierarchical Chain-of-Thought
Sili Huang, Jifeng Hu, Hechang Chen, Lichao Sun, Bo Yang
In-context learning is a promising approach for offline reinforcement learning (RL) to handle online tasks, which can be achieved by providing task prompts. Recent works demonstrated that in-context RL could emerge with self-improvement in a trial-and-error manner when treating RL tasks as an across-episodic sequential prediction problem. Despite the self-improvement not requiring gradient updates, current works still suffer from high computational costs when the across-episodic sequence increases with task horizons. To this end, we propose an In-context Decision Transformer (IDT) to achieve self-improvement in a high-level trial-and-error manner. Specifically, IDT is inspired by the efficient hierarchical structure of human decision-making and thus reconstructs the sequence to consist of high-level decisions instead of low-level actions that interact with environments. As one high-level decision can guide multi-step low-level actions, IDT naturally avoids excessively long sequences and solves online tasks more efficiently. Experimental results show that IDT achieves state-of-the-art in long-horizon tasks over current in-context RL methods. In particular, the online evaluation time of our IDT is textbf{36$times$} times faster than baselines in the D4RL benchmark and textbf{27$times$} times faster in the Grid World benchmark.
Read more6/3/2024