Contextual Cross-Modal Attention for Audio-Visual Deepfake Detection and Localization

0

Sign in to get full access
Overview
- Provides a contextual cross-modal attention approach for audio-visual deepfake detection and localization
- Leverages the interdependence between audio and visual modalities to enhance deepfake identification
- Includes experiments on public datasets to evaluate performance
Plain English Explanation
This research paper introduces a new method for detecting and localizing deepfake videos, which are manipulated media that appear genuine. The key idea is to use cross-modal attention - analyzing how the audio and visual information in a video relate to and depend on each other.
By understanding these cross-modal relationships, the model can better identify inconsistencies that indicate a deepfake. For example, if the lip movements don't match the audio, or the background doesn't coherently integrate with the person, the model can use these contextual cues to flag the video as potentially manipulated.
The paper tests this approach on standard deepfake datasets and shows it outperforms previous methods in both detecting the presence of deepfakes and pinpointing where in the video the manipulation occurs. This is an important advance, as deepfakes pose growing risks of misinformation and fraud, so improved detection is crucial.
Technical Explanation
The proposed model uses a cross-attentional fusion architecture to combine audio and visual features. It first extracts visual and audio embeddings from the input video using pre-trained backbone networks.
These embeddings are then passed through a dynamic cross-attention module that learns to attend to the relevant cross-modal relationships. This allows the model to focus on the interdependencies between the audio and visual cues, which are critical for deepfake detection.
The fused representation is then used for two tasks: 1) classifying whether the video is a deepfake or real, and 2) localizing the manipulated regions within the video. The localization is achieved through a pixel-wise segmentation map that highlights the areas most likely to be deepfaked.
Experiments on benchmark datasets demonstrate the effectiveness of this contextual cross-modal approach, outperforming prior state-of-the-art methods for both deepfake detection and localization. The model is able to leverage the complementary audio-visual information to better identify inconsistencies indicative of manipulation.
Critical Analysis
The paper provides a thorough evaluation of the proposed method, exploring its performance on multiple public deepfake datasets. However, the authors acknowledge that the datasets may not fully represent the evolving landscape of deepfake techniques, and further testing on more diverse and challenging samples would be valuable.
Additionally, the paper does not delve into the generalization capabilities of the model - it's unclear how well the approach would scale to detect deepfakes in the wild, where the audio-visual characteristics may differ significantly from the training data. Exploring the model's robustness to distribution shift would be an important area for future research.
The authors also note that the cross-attention mechanism, while effective, adds computational complexity to the model. Investigating more efficient ways to capture the critical cross-modal relationships could make the approach more practical for real-world deployment.
Conclusion
This research presents a novel contextual cross-modal attention approach for audio-visual deepfake detection and localization. By modeling the interdependencies between the audio and visual modalities, the model is able to identify inconsistencies that are indicative of manipulated media.
The demonstrated performance improvements over prior state-of-the-art methods highlight the value of this cross-modal understanding for deepfake identification. As deepfakes continue to evolve and pose growing threats, this work represents an important step forward in developing robust and reliable detection systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Contextual Cross-Modal Attention for Audio-Visual Deepfake Detection and Localization
Vinaya Sree Katamneni, Ajita Rattani
In the digital age, the emergence of deepfakes and synthetic media presents a significant threat to societal and political integrity. Deepfakes based on multi-modal manipulation, such as audio-visual, are more realistic and pose a greater threat. Current multi-modal deepfake detectors are often based on the attention-based fusion of heterogeneous data streams from multiple modalities. However, the heterogeneous nature of the data (such as audio and visual signals) creates a distributional modality gap and poses a significant challenge in effective fusion and hence multi-modal deepfake detection. In this paper, we propose a novel multi-modal attention framework based on recurrent neural networks (RNNs) that leverages contextual information for audio-visual deepfake detection. The proposed approach applies attention to multi-modal multi-sequence representations and learns the contributing features among them for deepfake detection and localization. Thorough experimental validations on audio-visual deepfake datasets, namely FakeAVCeleb, AV-Deepfake1M, TVIL, and LAV-DF datasets, demonstrate the efficacy of our approach. Cross-comparison with the published studies demonstrates superior performance of our approach with an improved accuracy and precision by 3.47% and 2.05% in deepfake detection and localization, respectively. Thus, obtaining state-of-the-art performance. To facilitate reproducibility, the code and the datasets information is available at https://github.com/vcbsl/audiovisual-deepfake/.
Read more8/9/2024
0
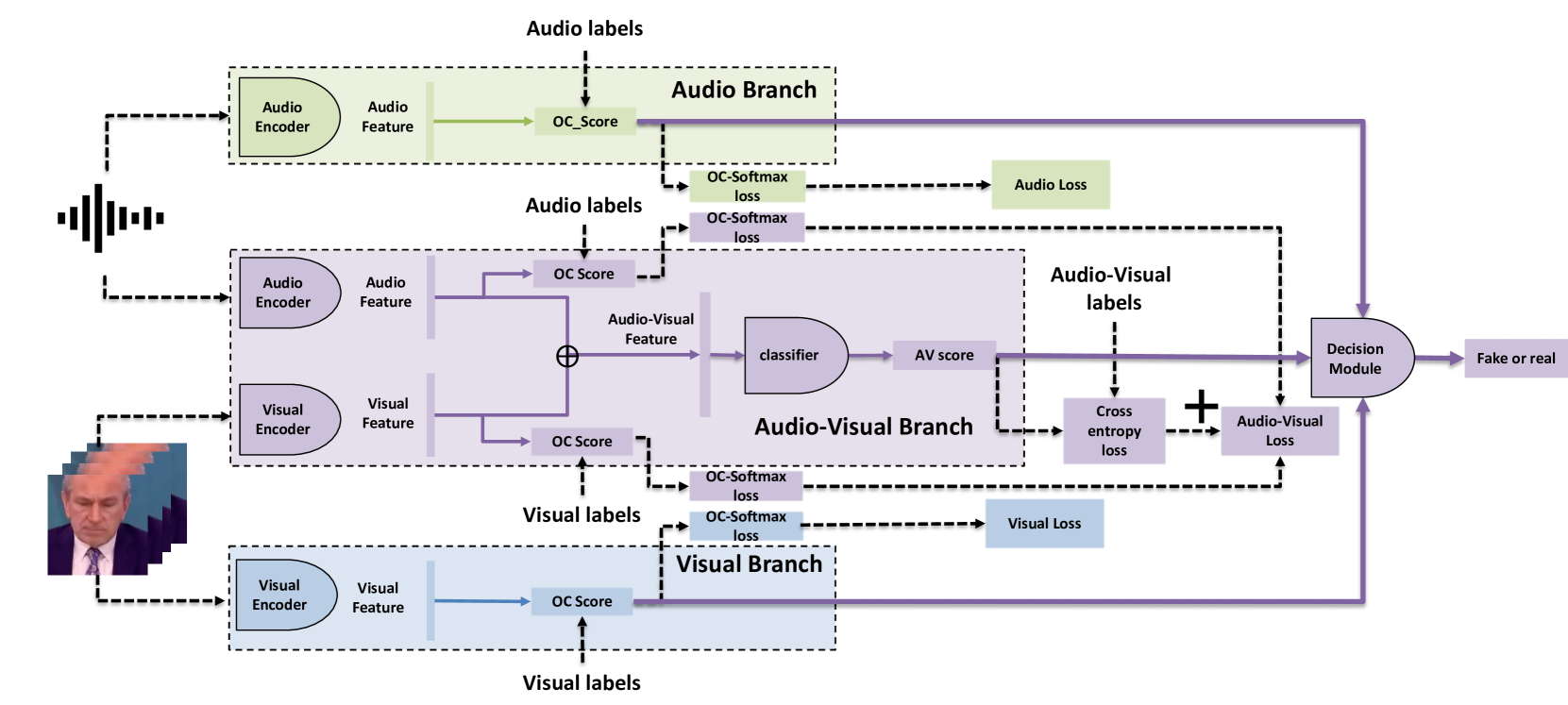
A Multi-Stream Fusion Approach with One-Class Learning for Audio-Visual Deepfake Detection
Kyungbok Lee, You Zhang, Zhiyao Duan
This paper addresses the challenge of developing a robust audio-visual deepfake detection model. In practical use cases, new generation algorithms are continually emerging, and these algorithms are not encountered during the development of detection methods. This calls for the generalization ability of the method. Additionally, to ensure the credibility of detection methods, it is beneficial for the model to interpret which cues from the video indicate it is fake. Motivated by these considerations, we then propose a multi-stream fusion approach with one-class learning as a representation-level regularization technique. We study the generalization problem of audio-visual deepfake detection by creating a new benchmark by extending and re-splitting the existing FakeAVCeleb dataset. The benchmark contains four categories of fake videos (Real Audio-Fake Visual, Fake Audio-Fake Visual, Fake Audio-Real Visual, and Unsynchronized videos). The experimental results demonstrate that our approach surpasses the previous models by a large margin. Furthermore, our proposed framework offers interpretability, indicating which modality the model identifies as more likely to be fake. The source code is released at https://github.com/bok-bok/MSOC.
Read more8/20/2024
📈
0
A Joint Cross-Attention Model for Audio-Visual Fusion in Dimensional Emotion Recognition
R. Gnana Praveen, Wheidima Carneiro de Melo, Nasib Ullah, Haseeb Aslam, Osama Zeeshan, Th'eo Denorme, Marco Pedersoli, Alessandro Koerich, Simon Bacon, Patrick Cardinal, Eric Granger
Multimodal emotion recognition has recently gained much attention since it can leverage diverse and complementary relationships over multiple modalities (e.g., audio, visual, biosignals, etc.), and can provide some robustness to noisy modalities. Most state-of-the-art methods for audio-visual (A-V) fusion rely on recurrent networks or conventional attention mechanisms that do not effectively leverage the complementary nature of A-V modalities. In this paper, we focus on dimensional emotion recognition based on the fusion of facial and vocal modalities extracted from videos. Specifically, we propose a joint cross-attention model that relies on the complementary relationships to extract the salient features across A-V modalities, allowing for accurate prediction of continuous values of valence and arousal. The proposed fusion model efficiently leverages the inter-modal relationships, while reducing the heterogeneity between the features. In particular, it computes the cross-attention weights based on correlation between the combined feature representation and individual modalities. By deploying the combined A-V feature representation into the cross-attention module, the performance of our fusion module improves significantly over the vanilla cross-attention module. Experimental results on validation-set videos from the AffWild2 dataset indicate that our proposed A-V fusion model provides a cost-effective solution that can outperform state-of-the-art approaches. The code is available on GitHub: https://github.com/praveena2j/JointCrossAttentional-AV-Fusion.
Read more7/9/2024
0
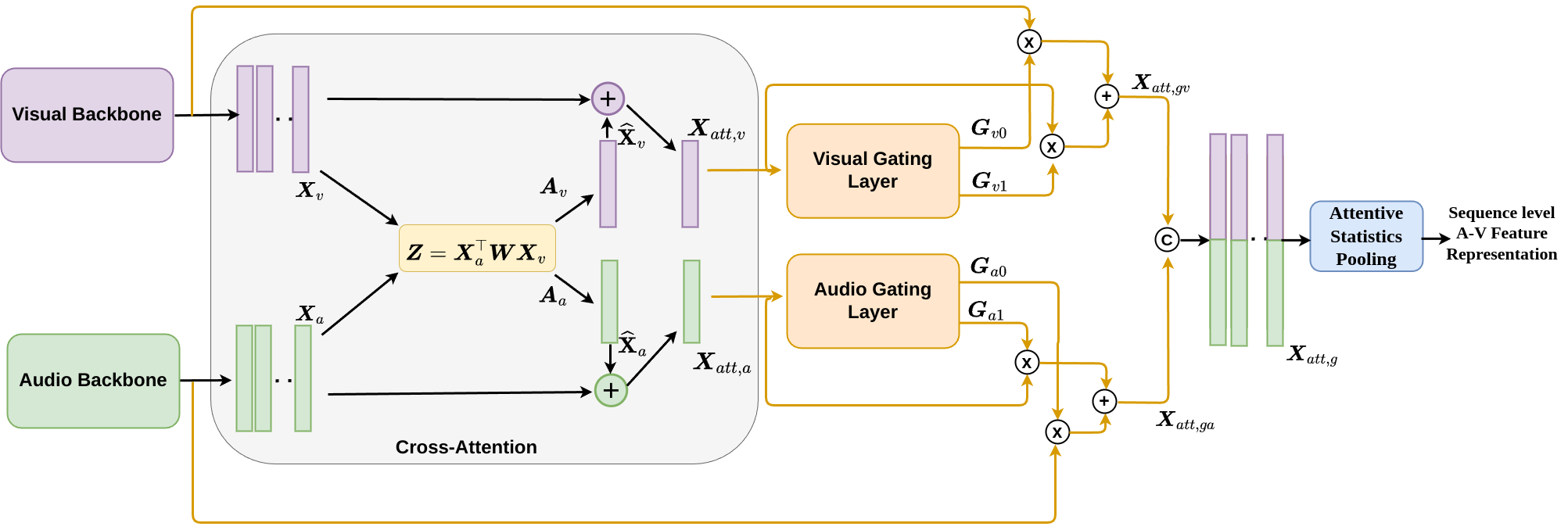
Dynamic Cross Attention for Audio-Visual Person Verification
R. Gnana Praveen, Jahangir Alam
Although person or identity verification has been predominantly explored using individual modalities such as face and voice, audio-visual fusion has recently shown immense potential to outperform unimodal approaches. Audio and visual modalities are often expected to pose strong complementary relationships, which plays a crucial role in effective audio-visual fusion. However, they may not always strongly complement each other, they may also exhibit weak complementary relationships, resulting in poor audio-visual feature representations. In this paper, we propose a Dynamic Cross-Attention (DCA) model that can dynamically select the cross-attended or unattended features on the fly based on the strong or weak complementary relationships, respectively, across audio and visual modalities. In particular, a conditional gating layer is designed to evaluate the contribution of the cross-attention mechanism and choose cross-attended features only when they exhibit strong complementary relationships, otherwise unattended features. Extensive experiments are conducted on the Voxceleb1 dataset to demonstrate the robustness of the proposed model. Results indicate that the proposed model consistently improves the performance on multiple variants of cross-attention while outperforming the state-of-the-art methods.
Read more4/23/2024