GraphER: A Structure-aware Text-to-Graph Model for Entity and Relation Extraction
2404.12491
0
0
Abstract
Information extraction (IE) is an important task in Natural Language Processing (NLP), involving the extraction of named entities and their relationships from unstructured text. In this paper, we propose a novel approach to this task by formulating it as graph structure learning (GSL). By formulating IE as GSL, we enhance the model's ability to dynamically refine and optimize the graph structure during the extraction process. This formulation allows for better interaction and structure-informed decisions for entity and relation prediction, in contrast to previous models that have separate or untied predictions for these tasks. When compared against state-of-the-art baselines on joint entity and relation extraction benchmarks, our model, GraphER, achieves competitive results.
Create account to get full access
Overview
- Presents a new model called GraphER for extracting entities and relations from text in a structured way
- Leverages graph neural networks to capture the inherent structure of the entities and relations in the text
- Achieves state-of-the-art performance on standard entity and relation extraction benchmarks
Plain English Explanation
The paper introduces a new model called GraphER that aims to extract information from text in a more structured way. When humans read text, we naturally understand the relationships between different entities (people, organizations, locations, etc.) and how they are connected. GraphER tries to mimic this by using a graph neural network to capture the inherent structure of the entities and relations in the text.
Rather than just identifying individual entities or relations in isolation, GraphER models the whole network of entities and how they interact. This allows it to make more informed and coherent predictions about what the key entities are and how they are related. The authors show that GraphER outperforms other state-of-the-art approaches on standard benchmarks for entity and relation extraction.
The key innovation of GraphER is its use of a graph neural network, which is a type of deep learning model well-suited for analyzing interconnected data like the relationships between entities in text. This allows GraphER to go beyond just identifying individual entities or relations, and instead uncover the broader context and structure of the information present.
Technical Explanation
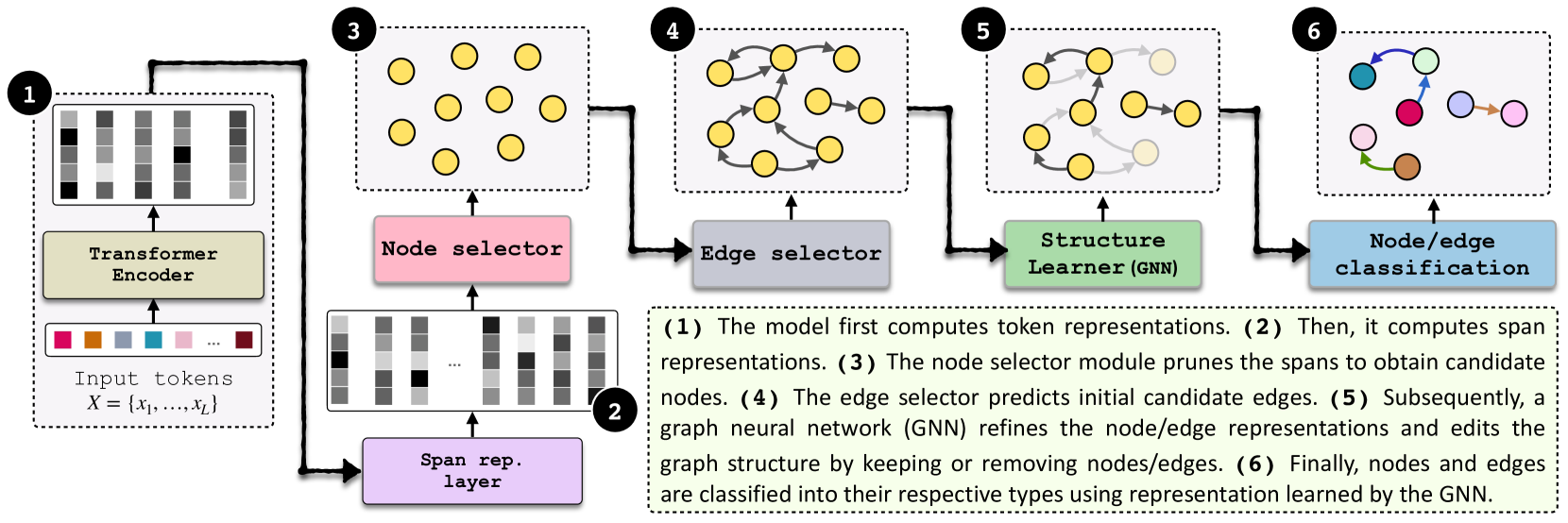
The GraphER model leverages graph neural networks to capture the structural information in text for the task of entity and relation extraction. It takes a sequence of text as input and outputs a graph-structured representation of the entities and the relations between them.
The model consists of three key components:
- Text Encoder: A BERT-based encoder that generates contextualized representations of the input text.
- Graph Constructor: This component uses the text representations to construct a graph-structured representation of the entities and relations in the text.
- Graph Neural Network: A graph neural network processes the constructed graph to jointly predict the entities and the relations between them.
The graph neural network allows GraphER to capture the interdependencies between entities and relations, going beyond the limitations of traditional sequence-to-sequence models mentioned in the survey paper.
The authors evaluate GraphER on standard entity and relation extraction benchmarks, including CoNLL-2003 and SciERC. They demonstrate that GraphER outperforms previous state-of-the-art models, showcasing the benefits of the graph-based approach for jointly modeling entities and relations.
Critical Analysis
The paper presents a compelling approach for structured information extraction from text, but there are a few potential limitations and areas for further research:
-
Scalability to longer documents: The experiments in the paper focus on relatively short text snippets. It's unclear how well the GraphER model would scale to longer, more complex documents with a larger number of entities and relations.
-
Interpretability: While the graph-based representation can provide more structured insights, the authors do not discuss the interpretability of the model's predictions. Investigating the transparency of the model's decision-making process could be an important area for future work.
-
Domain-specificity: The experiments are conducted on general-domain and scientific text. Exploring the performance of GraphER on more specialized domains, such as biomedical literature, could uncover additional challenges and opportunities.
Overall, the GraphER model represents an interesting and promising step towards more structured and contextual information extraction from text. Further research into scaling, interpretability, and domain-specific applications could help unlock the full potential of this approach.
Conclusion
The GraphER model presented in this paper introduces a novel graph-based approach to the task of entity and relation extraction from text. By leveraging the inherent structure of the entities and their relationships, GraphER is able to outperform previous state-of-the-art models on standard benchmarks.
The key innovation of GraphER is its use of a graph neural network to jointly model the entities and relations, going beyond the limitations of traditional sequence-to-sequence models. This graph-based representation allows the model to capture the interdependencies between different elements of the text, leading to more coherent and contextual predictions.
While the paper demonstrates the effectiveness of the GraphER approach on short text snippets, further research is needed to explore its scalability to longer documents, interpretability, and performance on specialized domains. Nonetheless, this work represents an important step towards more structured and intelligent information extraction from text, with potential applications in a wide range of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
A Continual Relation Extraction Approach for Knowledge Graph Completeness
Sefika Efeoglu
0
0
Representing unstructured data in a structured form is most significant for information system management to analyze and interpret it. To do this, the unstructured data might be converted into Knowledge Graphs, by leveraging an information extraction pipeline whose main tasks are named entity recognition and relation extraction. This thesis aims to develop a novel continual relation extraction method to identify relations (interconnections) between entities in a data stream coming from the real world. Domain-specific data of this thesis is corona news from German and Austrian newspapers.
4/30/2024
Large Language Models for Generative Information Extraction: A Survey
Derong Xu, Wei Chen, Wenjun Peng, Chao Zhang, Tong Xu, Xiangyu Zhao, Xian Wu, Yefeng Zheng, Yang Wang, Enhong Chen
0
0
Information extraction (IE) aims to extract structural knowledge (such as entities, relations, and events) from plain natural language texts. Recently, generative Large Language Models (LLMs) have demonstrated remarkable capabilities in text understanding and generation, allowing for generalization across various domains and tasks. As a result, numerous works have been proposed to harness abilities of LLMs and offer viable solutions for IE tasks based on a generative paradigm. To conduct a comprehensive systematic review and exploration of LLM efforts for IE tasks, in this study, we survey the most recent advancements in this field. We first present an extensive overview by categorizing these works in terms of various IE subtasks and learning paradigms, then we empirically analyze the most advanced methods and discover the emerging trend of IE tasks with LLMs. Based on thorough review conducted, we identify several insights in technique and promising research directions that deserve further exploration in future studies. We maintain a public repository and consistently update related resources at: url{https://github.com/quqxui/Awesome-LLM4IE-Papers}.
6/5/2024

Knowledge Graphs and Pre-trained Language Models enhanced Representation Learning for Conversational Recommender Systems
Zhangchi Qiu, Ye Tao, Shirui Pan, Alan Wee-Chung Liew
0
0
Conversational recommender systems (CRS) utilize natural language interactions and dialogue history to infer user preferences and provide accurate recommendations. Due to the limited conversation context and background knowledge, existing CRSs rely on external sources such as knowledge graphs to enrich the context and model entities based on their inter-relations. However, these methods ignore the rich intrinsic information within entities. To address this, we introduce the Knowledge-Enhanced Entity Representation Learning (KERL) framework, which leverages both the knowledge graph and a pre-trained language model to improve the semantic understanding of entities for CRS. In our KERL framework, entity textual descriptions are encoded via a pre-trained language model, while a knowledge graph helps reinforce the representation of these entities. We also employ positional encoding to effectively capture the temporal information of entities in a conversation. The enhanced entity representation is then used to develop a recommender component that fuses both entity and contextual representations for more informed recommendations, as well as a dialogue component that generates informative entity-related information in the response text. A high-quality knowledge graph with aligned entity descriptions is constructed to facilitate our study, namely the Wiki Movie Knowledge Graph (WikiMKG). The experimental results show that KERL achieves state-of-the-art results in both recommendation and response generation tasks.
5/2/2024
💬
Learning to Extract Structured Entities Using Language Models
Haolun Wu, Ye Yuan, Liana Mikaelyan, Alexander Meulemans, Xue Liu, James Hensman, Bhaskar Mitra
0
0
Recent advances in machine learning have significantly impacted the field of information extraction, with Language Models (LMs) playing a pivotal role in extracting structured information from unstructured text. Prior works typically represent information extraction as triplet-centric and use classical metrics such as precision and recall for evaluation. We reformulate the task to be entity-centric, enabling the use of diverse metrics that can provide more insights from various perspectives. We contribute to the field by introducing Structured Entity Extraction and proposing the Approximate Entity Set OverlaP (AESOP) metric, designed to appropriately assess model performance. Later, we introduce a new model that harnesses the power of LMs for enhanced effectiveness and efficiency by decomposing the extraction task into multiple stages. Quantitative and human side-by-side evaluations confirm that our model outperforms baselines, offering promising directions for future advancements in structured entity extraction.
6/21/2024