Controlling Large Language Model Agents with Entropic Activation Steering

0

Sign in to get full access
Overview
- This paper introduces a new method called "Entropic Activation Steering" for controlling the behavior of large language models (LLMs) in a more nuanced and controllable way.
- The key idea is to use an "activation function" that can be tuned to steer the LLM's outputs in desired directions, rather than relying on prompting or other external constraints.
- The authors show that this method can be used to improve the truthfulness, coherence, and other desirable properties of LLM outputs, while maintaining the models' broad capabilities.
Plain English Explanation
Large language models (LLMs) like GPT-3 are incredibly powerful, but can sometimes produce outputs that are untruthful, incoherent, or undesirable in other ways. This paper introduces a new technique called "Entropic Activation Steering" that aims to give us more control over these models.
The core idea is to use a special type of "activation function" - a mathematical function that determines how the model's internal neurons fire - to steer the model's behavior in a desired direction. For example, you could tune the activation function to make the model more truthful, or to produce more coherent and logical outputs. This is similar to the "steering" techniques discussed in other papers, but with some key differences.
One key benefit of this approach is that it doesn't require retraining the entire model from scratch. Instead, you can just update the activation function, which is much faster and easier. This is an advance over prior "tuning-free" approaches that also aimed to control LLM behavior without retraining.
The authors show through experiments that this Entropic Activation Steering method can indeed improve properties like truthfulness and coherence, while still allowing the LLM to maintain its broad capabilities. This builds on prior work on adding "causal explainable guardrails" to LLMs.
Overall, this is an interesting new technique that could help us get more control and predictability out of these powerful but sometimes unpredictable language models. The authors also discuss how this could potentially be combined with personalized steering approaches for even more fine-grained control.
Technical Explanation
The core idea of the paper is to use an "activation function" to steer the behavior of a large language model (LLM) in desired directions, rather than relying on prompting or other external constraints.
Specifically, the authors propose a new activation function called "Entropic Activation Steering" (EAS). This function takes into account the entropy (uncertainty) of the model's output distribution, and can be tuned to encourage more truthful, coherent, or otherwise desirable outputs.
The authors evaluate EAS on a range of benchmark tasks, comparing it to standard activation functions as well as other LLM control techniques like prompt engineering and reinforcement learning. They find that EAS can improve metrics like truthfulness and logical consistency, while maintaining the model's broad capabilities.
Importantly, EAS does not require retraining the entire LLM model. Instead, the activation function can be updated separately, which is much more efficient. This builds on prior work on "tuning-free" LLM control methods.
The authors also discuss how EAS could potentially be combined with personalized steering approaches, allowing for even finer-grained control over the model's behavior. Overall, this work represents an interesting new direction for improving the reliability and predictability of large language models.
Critical Analysis
The paper makes a compelling case for using Entropic Activation Steering as a way to gain more nuanced control over large language models. The experimental results are promising, showing improvements in key metrics like truthfulness and coherence.
However, the authors do acknowledge some limitations of their approach. For example, they note that EAS may be less effective at controlling very high-level properties of the model's outputs, such as overall "coherence" or "informativeness." More research would be needed to understand the full scope and limitations of the method.
Additionally, the authors do not explore the potential for unintended consequences or misuse of this technology. As with any technique for controlling the outputs of powerful AI systems, there are valid concerns about potential abuse or harmful applications. The paper would have been strengthened by a more in-depth discussion of these issues.
Overall, though, this seems like an important contribution to the field of LLM control and reliability. The core idea of using activation functions to steer model behavior is novel and promising. With further research and careful consideration of the ethical implications, techniques like Entropic Activation Steering could play a valuable role in making large language models more robust and reliable.
Conclusion
This paper introduces a new method called "Entropic Activation Steering" for improving the controllability and reliability of large language models. The key insight is to use a specialized activation function that can steer the model's outputs in desired directions, such as toward more truthful and coherent responses.
The authors show through experiments that this approach can enhance properties like truthfulness and logical consistency, while preserving the models' broad capabilities. Importantly, EAS can be implemented without retraining the entire model, making it a more efficient alternative to some other LLM control techniques.
Overall, this work represents an interesting advance in the effort to make large language models more reliable and predictable. While the method has some limitations, and raises important ethical questions, it is a promising step forward. Further research and development in this area could yield substantial benefits for a wide range of applications of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Controlling Large Language Model Agents with Entropic Activation Steering
Nate Rahn, Pierluca D'Oro, Marc G. Bellemare
The generality of pretrained large language models (LLMs) has prompted increasing interest in their use as in-context learning agents. To be successful, such agents must form beliefs about how to achieve their goals based on limited interaction with their environment, resulting in uncertainty about the best action to take at each step. In this paper, we study how LLM agents form and act on these beliefs by conducting experiments in controlled sequential decision-making tasks. To begin, we find that LLM agents are overconfident: They draw strong conclusions about what to do based on insufficient evidence, resulting in inadequately explorative behavior. We dig deeper into this phenomenon and show how it emerges from a collapse in the entropy of the action distribution implied by sampling from the LLM. We then demonstrate that existing token-level sampling techniques are by themselves insufficient to make the agent explore more. Motivated by this fact, we introduce Entropic Activation Steering (EAST), an activation steering method for in-context LLM agents. EAST computes a steering vector as an entropy-weighted combination of representations, and uses it to manipulate an LLM agent's uncertainty over actions by intervening on its activations during the forward pass. We show that EAST can reliably increase the entropy in an LLM agent's actions, causing more explorative behavior to emerge. Finally, EAST modifies the subjective uncertainty an LLM agent expresses, paving the way to interpreting and controlling how LLM agents represent uncertainty about their decisions.
Read more6/4/2024
💬
0
Activation Addition: Steering Language Models Without Optimization
Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J. Vazquez, Ulisse Mini, Monte MacDiarmid
Reliably controlling the behavior of large language models is a pressing open problem. Existing methods include supervised finetuning, reinforcement learning from human feedback, prompt engineering and guided decoding. We instead investigate activation engineering: modifying activations at inference-time to predictably alter model behavior. We bias the forward pass with a 'steering vector' implicitly specified through natural language. Past work learned these steering vectors; our Activation Addition (ActAdd) method instead computes them by taking activation differences resulting from pairs of prompts. We demonstrate ActAdd on a range of LLMs (LLaMA-3, OPT, GPT-2, and GPT-J), obtaining SOTA on detoxification and negative-to-positive sentiment control. Our approach yields inference-time control over high-level properties of output like topic and sentiment while preserving performance on off-target tasks. ActAdd takes far less compute and implementation effort than finetuning or RLHF, allows users control through natural language, and its computational overhead (as a fraction of inference time) appears stable or improving over increasing model size.
Read more6/5/2024
🔎
0
Programming Refusal with Conditional Activation Steering
Bruce W. Lee, Inkit Padhi, Karthikeyan Natesan Ramamurthy, Erik Miehling, Pierre Dognin, Manish Nagireddy, Amit Dhurandhar
LLMs have shown remarkable capabilities, but precisely controlling their response behavior remains challenging. Existing activation steering methods alter LLM behavior indiscriminately, limiting their practical applicability in settings where selective responses are essential, such as content moderation or domain-specific assistants. In this paper, we propose Conditional Activation Steering (CAST), which analyzes LLM activation patterns during inference to selectively apply or withhold activation steering based on the input context. Our method is based on the observation that different categories of prompts activate distinct patterns in the model's hidden states. Using CAST, one can systematically control LLM behavior with rules like if input is about hate speech or adult content, then refuse or if input is not about legal advice, then refuse. This allows for selective modification of responses to specific content while maintaining normal responses to other content, all without requiring weight optimization. We release an open-source implementation of our framework.
Read more9/11/2024
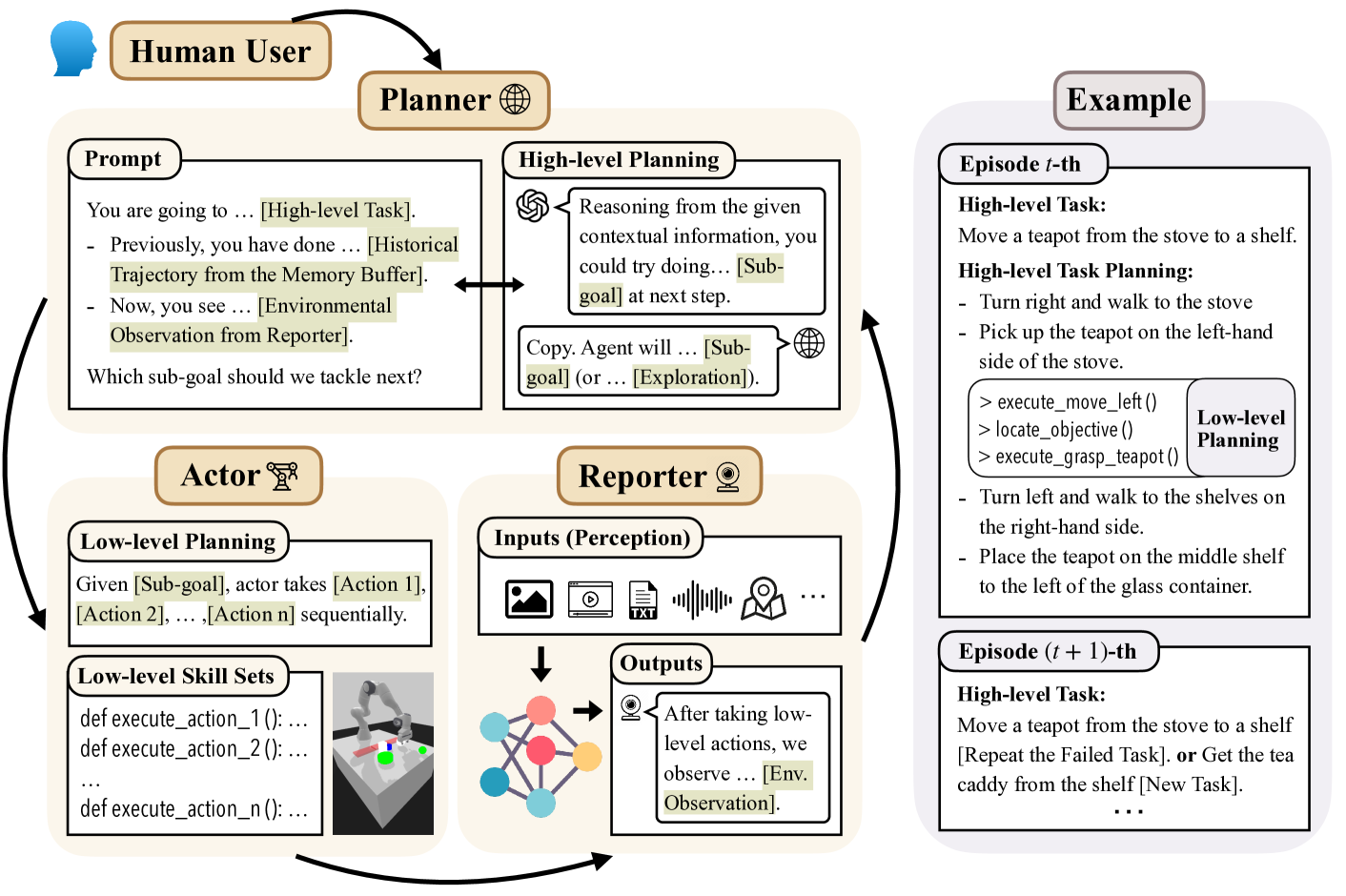
0
From Words to Actions: Unveiling the Theoretical Underpinnings of LLM-Driven Autonomous Systems
Jianliang He, Siyu Chen, Fengzhuo Zhang, Zhuoran Yang
In this work, from a theoretical lens, we aim to understand why large language model (LLM) empowered agents are able to solve decision-making problems in the physical world. To this end, consider a hierarchical reinforcement learning (RL) model where the LLM Planner and the Actor perform high-level task planning and low-level execution, respectively. Under this model, the LLM Planner navigates a partially observable Markov decision process (POMDP) by iteratively generating language-based subgoals via prompting. Under proper assumptions on the pretraining data, we prove that the pretrained LLM Planner effectively performs Bayesian aggregated imitation learning (BAIL) through in-context learning. Additionally, we highlight the necessity for exploration beyond the subgoals derived from BAIL by proving that naively executing the subgoals returned by LLM leads to a linear regret. As a remedy, we introduce an $epsilon$-greedy exploration strategy to BAIL, which is proven to incur sublinear regret when the pretraining error is small. Finally, we extend our theoretical framework to include scenarios where the LLM Planner serves as a world model for inferring the transition model of the environment and to multi-agent settings, enabling coordination among multiple Actors.
Read more7/23/2024