STEER: Assessing the Economic Rationality of Large Language Models

0

Sign in to get full access
Overview
- This paper proposes a framework for assessing the economic rationality of large language models (LLMs).
- It introduces the concept of "rationality report cards" to evaluate how well LLMs make decisions in economic contexts.
- The framework examines different aspects of economic rationality, such as preference coherence, risk attitudes, and consistent decision-making.
- The authors apply this framework to analyze the economic rationality of several prominent LLMs, including GPT-3, Chinchilla, and PaLM.
Plain English Explanation
The paper is about evaluating how well large language models (LLMs), which are advanced AI systems that can engage in human-like text generation, make economic decisions. The researchers developed a framework called "rationality report cards" to assess different aspects of economic rationality, such as whether the models have consistent preferences, how they handle risk, and whether their decisions are logically sound.
The researchers then used this framework to analyze the economic decision-making of several well-known LLMs, including GPT-3, Chinchilla, and PaLM. This allows them to identify strengths and weaknesses in the economic rationality of these models, which could be important as LLMs are increasingly used in real-world economic applications, such as generating business strategies or providing financial advice.
Technical Explanation
The paper first taxonomizes the key elements of economic rationality, including preference coherence, risk attitudes, and decision-making consistency. It then outlines a framework for constructing "rationality report cards" to assess how well LLMs perform on these different dimensions of rationality.
The researchers apply this framework to analyze the economic rationality of several prominent LLMs, including GPT-3, Chinchilla, and PaLM. They do this by designing a series of economic tasks and decision-making scenarios, and then evaluating how the models respond. For example, to assess preference coherence, they might present the models with a series of choices between different goods or services and ensure the models' preferences are logically consistent.
The results of these evaluations are then compiled into the rationality report cards, which provide a detailed assessment of each model's economic rationality. The paper discusses both the strengths and weaknesses identified in the models' decision-making, and how these insights could inform the development of more economically rational AI systems.
Critical Analysis
The paper provides a valuable and novel framework for evaluating the economic rationality of LLMs, which is an important consideration as these models are increasingly deployed in real-world economic applications. The authors acknowledge several limitations, such as the challenge of scaling the framework to larger models and the potential for biases in the evaluation tasks.
One potential area for further research would be to explore how the economic rationality of LLMs may evolve as the models are fine-tuned or retrained on different datasets. Additionally, it would be interesting to see how the framework could be extended to assess the economic rationality of other types of AI systems, such as reinforcement learning agents or multi-agent systems.
Overall, this paper represents an important step towards better understanding the economic decision-making capabilities of LLMs, and the authors' framework could have significant implications for the responsible development and deployment of these powerful AI systems.
Conclusion
This paper introduces a novel framework for assessing the economic rationality of large language models (LLMs), which is an important consideration as these models are increasingly used in real-world economic applications. The researchers developed "rationality report cards" to evaluate LLMs' performance on key dimensions of economic rationality, such as preference coherence, risk attitudes, and decision-making consistency.
The authors then applied this framework to analyze several prominent LLMs, including GPT-3, Chinchilla, and PaLM. The results provide valuable insights into the strengths and weaknesses of these models' economic decision-making, which could inform the development of more economically rational AI systems in the future.
While the paper acknowledges some limitations, such as the challenge of scaling the framework to larger models, it represents an important step towards a better understanding of how LLMs handle economic tasks and decisions. As these powerful AI systems continue to be deployed in real-world economic scenarios, the ability to critically evaluate their economic rationality will become increasingly crucial.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
STEER: Assessing the Economic Rationality of Large Language Models
Narun Raman, Taylor Lundy, Samuel Amouyal, Yoav Levine, Kevin Leyton-Brown, Moshe Tennenholtz
There is increasing interest in using LLMs as decision-making agents. Doing so includes many degrees of freedom: which model should be used; how should it be prompted; should it be asked to introspect, conduct chain-of-thought reasoning, etc? Settling these questions -- and more broadly, determining whether an LLM agent is reliable enough to be trusted -- requires a methodology for assessing such an agent's economic rationality. In this paper, we provide one. We begin by surveying the economic literature on rational decision making, taxonomizing a large set of fine-grained elements that an agent should exhibit, along with dependencies between them. We then propose a benchmark distribution that quantitatively scores an LLMs performance on these elements and, combined with a user-provided rubric, produces a STEER report card. Finally, we describe the results of a large-scale empirical experiment with 14 different LLMs, characterizing the both current state of the art and the impact of different model sizes on models' ability to exhibit rational behavior.
Read more5/29/2024

0
The Economic Implications of Large Language Model Selection on Earnings and Return on Investment: A Decision Theoretic Model
Geraldo Xex'eo, Filipe Braida, Marcus Parreiras, Paulo Xavier
Selecting language models in business contexts requires a careful analysis of the final financial benefits of the investment. However, the emphasis of academia and industry analysis of LLM is solely on performance. This work introduces a framework to evaluate LLMs, focusing on the earnings and return on investment aspects that should be taken into account in business decision making. We use a decision-theoretic approach to compare the financial impact of different LLMs, considering variables such as the cost per token, the probability of success in the specific task, and the gain and losses associated with LLMs use. The study reveals how the superior accuracy of more expensive models can, under certain conditions, justify a greater investment through more significant earnings but not necessarily a larger RoI. This article provides a framework for companies looking to optimize their technology choices, ensuring that investment in cutting-edge technology aligns with strategic financial objectives. In addition, we discuss how changes in operational variables influence the economics of using LLMs, offering practical insights for enterprise settings, finding that the predicted gain and loss and the different probabilities of success and failure are the variables that most impact the sensitivity of the models.
Read more5/29/2024
0
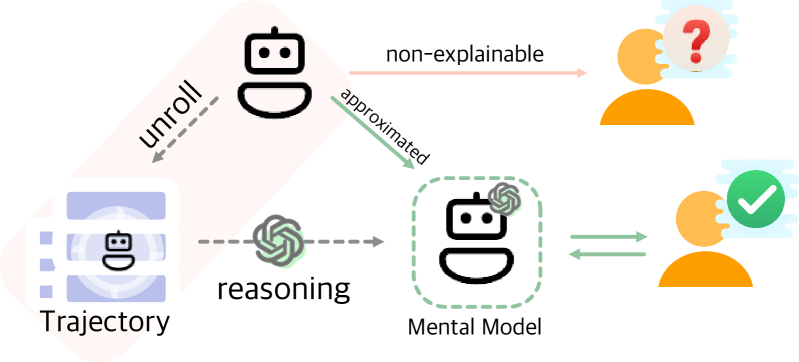
Mental Modeling of Reinforcement Learning Agents by Language Models
Wenhao Lu, Xufeng Zhao, Josua Spisak, Jae Hee Lee, Stefan Wermter
Can emergent language models faithfully model the intelligence of decision-making agents? Though modern language models exhibit already some reasoning ability, and theoretically can potentially express any probable distribution over tokens, it remains underexplored how the world knowledge these pretrained models have memorized can be utilized to comprehend an agent's behaviour in the physical world. This study empirically examines, for the first time, how well large language models (LLMs) can build a mental model of agents, termed agent mental modelling, by reasoning about an agent's behaviour and its effect on states from agent interaction history. This research may unveil the potential of leveraging LLMs for elucidating RL agent behaviour, addressing a key challenge in eXplainable reinforcement learning (XRL). To this end, we propose specific evaluation metrics and test them on selected RL task datasets of varying complexity, reporting findings on agent mental model establishment. Our results disclose that LLMs are not yet capable of fully mental modelling agents through inference alone without further innovations. This work thus provides new insights into the capabilities and limitations of modern LLMs.
Read more6/27/2024

0
New!An Experimental Study of Competitive Market Behavior Through LLMs
Jingru Jia, Zehua Yuan
This study explores the potential of large language models (LLMs) to conduct market experiments, aiming to understand their capability to comprehend competitive market dynamics. We model the behavior of market agents in a controlled experimental setting, assessing their ability to converge toward competitive equilibria. The results reveal the challenges current LLMs face in replicating the dynamic decision-making processes characteristic of human trading behavior. Unlike humans, LLMs lacked the capacity to achieve market equilibrium. The research demonstrates that while LLMs provide a valuable tool for scalable and reproducible market simulations, their current limitations necessitate further advancements to fully capture the complexities of market behavior. Future work that enhances dynamic learning capabilities and incorporates elements of behavioral economics could improve the effectiveness of LLMs in the economic domain, providing new insights into market dynamics and aiding in the refinement of economic policies.
Read more9/16/2024