ConU: Conformal Uncertainty in Large Language Models with Correctness Coverage Guarantees

0

Sign in to get full access
Overview
- This paper introduces ConU, a novel approach to providing conformal uncertainty estimates for large language models (LLMs) that come with correctness coverage guarantees.
- ConU addresses the challenge of quantifying the reliability and uncertainty of LLM outputs, which is crucial for safely deploying these models in real-world applications.
- The paper presents experiments demonstrating that ConU can effectively assess the uncertainty of LLM predictions and provide accurate correctness coverage, outperforming existing uncertainty estimation methods.
Plain English Explanation
Conformal prediction is a statistical technique that can be used to quantify the uncertainty of machine learning model predictions. In the context of large language models (LLMs) like GPT-3, this is important because these models can sometimes make mistakes or provide unreliable outputs, and it's crucial to be able to identify when that's happening.
The researchers in this paper have developed a new method called ConU (Conformal Uncertainty) that can assess the uncertainty of LLM predictions and provide a "correctness coverage guarantee". This means that ConU can tell you how likely it is that the model's output is actually correct, which is a key requirement for safely deploying LLMs in real-world applications like customer service chatbots or medical diagnosis systems.
The key innovation of ConU is that it can provide these uncertainty estimates without requiring any changes to the underlying LLM architecture. This makes it more practical to use than some other uncertainty estimation methods that require retraining or modifying the model itself.
The paper shows through experiments that ConU outperforms existing uncertainty estimation techniques, allowing LLMs to provide reliable and well-calibrated uncertainty estimates alongside their predictions. This is an important step forward in making these powerful language models more trustworthy and robust for real-world use cases.
Technical Explanation
The paper introduces a novel approach called ConU (Conformal Uncertainty) that provides uncertainty estimates for large language model (LLM) predictions along with correctness coverage guarantees. Conformal prediction is a framework that can be used to quantify the reliability of machine learning model outputs, and the authors apply this technique to the context of LLMs.
The key innovation of ConU is that it can provide these uncertainty estimates without requiring any modifications to the underlying LLM architecture. This is achieved by training a separate "conformal predictor" model that learns to map LLM outputs to reliable uncertainty scores. The conformal predictor is trained using a novel approach that ensures the resulting uncertainty estimates come with rigorous statistical guarantees on their correctness coverage.
Through extensive experiments, the authors demonstrate that ConU significantly outperforms existing uncertainty estimation methods for LLMs. ConU is able to provide well-calibrated uncertainty estimates that accurately reflect the likelihood of the LLM's output being correct. This is a crucial capability for safely deploying LLMs in high-stakes applications like medical diagnosis or legal decision-making.
The paper also introduces several technical innovations, including a new way of constructing the conformal predictor's prediction sets and an efficient algorithm for online adaptation of the uncertainty estimates. These advances help make ConU a practical and effective solution for reliable LLM deployment.
Critical Analysis
The ConU approach represents an important step forward in quantifying the reliability of large language models, which is a critical requirement for their safe and responsible deployment. By providing well-calibrated uncertainty estimates along with LLM predictions, ConU addresses a key limitation of current LLM systems, which can sometimes make overconfident or erroneous outputs without any indication of their reliability.
That said, the paper does acknowledge some limitations and areas for future work. For example, the current ConU implementation is limited to classification tasks, and extending it to other types of LLM outputs (e.g., open-ended text generation) remains an open challenge. Additionally, the paper notes that the computational overhead of ConU may be non-trivial, and further optimizations may be needed for real-time applications.
It would also be valuable to see more real-world evaluations of ConU, beyond the controlled laboratory experiments reported in the paper. Assessing the performance of ConU in deployed, high-stakes applications would provide a more comprehensive understanding of its strengths and weaknesses.
Overall, the ConU approach is a significant contribution to the field of reliable and trustworthy natural language processing. By providing correctness coverage guarantees, it has the potential to unlock new use cases for large language models and inspire further research into uncertainty quantification for these powerful AI systems.
Conclusion
The ConU paper presents a novel method for quantifying the uncertainty of large language model (LLM) predictions and providing correctness coverage guarantees. This is a crucial capability for safely deploying LLMs in real-world applications, where reliable and well-calibrated uncertainty estimates are essential.
The key innovation of ConU is that it can provide these uncertainty estimates without requiring any changes to the underlying LLM architecture, making it a practical solution for improving the trustworthiness of these powerful AI systems. Experimental results show that ConU outperforms existing uncertainty estimation techniques, demonstrating its effectiveness at assessing LLM reliability.
While the paper identifies some limitations and areas for future work, the ConU approach represents an important step forward in the quest for reliable and responsible natural language processing. By quantifying the uncertainty of LLM outputs, ConU has the potential to unlock new applications and use cases for these transformative AI technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ConU: Conformal Uncertainty in Large Language Models with Correctness Coverage Guarantees
Zhiyuan Wang, Jinhao Duan, Lu Cheng, Yue Zhang, Qingni Wang, Hengtao Shen, Xiaofeng Zhu, Xiaoshuang Shi, Kaidi Xu
Uncertainty quantification (UQ) in natural language generation (NLG) tasks remains an open challenge, exacerbated by the intricate nature of the recent large language models (LLMs). This study investigates adapting conformal prediction (CP), which can convert any heuristic measure of uncertainty into rigorous theoretical guarantees by constructing prediction sets, for black-box LLMs in open-ended NLG tasks. We propose a sampling-based uncertainty measure leveraging self-consistency and develop a conformal uncertainty criterion by integrating the uncertainty condition aligned with correctness into the design of the CP algorithm. Experimental results indicate that our uncertainty measure generally surpasses prior state-of-the-art methods. Furthermore, we calibrate the prediction sets within the model's unfixed answer distribution and achieve strict control over the correctness coverage rate across 6 LLMs on 4 free-form NLG datasets, spanning general-purpose and medical domains, while the small average set size further highlights the efficiency of our method in providing trustworthy guarantees for practical open-ended NLG applications.
Read more7/2/2024
🔮
0
Conformal Prediction for Natural Language Processing: A Survey
Margarida M. Campos, Ant'onio Farinhas, Chrysoula Zerva, M'ario A. T. Figueiredo, Andr'e F. T. Martins
The rapid proliferation of large language models and natural language processing (NLP) applications creates a crucial need for uncertainty quantification to mitigate risks such as hallucinations and to enhance decision-making reliability in critical applications. Conformal prediction is emerging as a theoretically sound and practically useful framework, combining flexibility with strong statistical guarantees. Its model-agnostic and distribution-free nature makes it particularly promising to address the current shortcomings of NLP systems that stem from the absence of uncertainty quantification. This paper provides a comprehensive survey of conformal prediction techniques, their guarantees, and existing applications in NLP, pointing to directions for future research and open challenges.
Read more5/6/2024

0
Conformal Language Modeling
Victor Quach, Adam Fisch, Tal Schuster, Adam Yala, Jae Ho Sohn, Tommi S. Jaakkola, Regina Barzilay
We propose a novel approach to conformal prediction for generative language models (LMs). Standard conformal prediction produces prediction sets -- in place of single predictions -- that have rigorous, statistical performance guarantees. LM responses are typically sampled from the model's predicted distribution over the large, combinatorial output space of natural language. Translating this process to conformal prediction, we calibrate a stopping rule for sampling different outputs from the LM that get added to a growing set of candidates until we are confident that the output set is sufficient. Since some samples may be low-quality, we also simultaneously calibrate and apply a rejection rule for removing candidates from the output set to reduce noise. Similar to conformal prediction, we prove that the sampled set returned by our procedure contains at least one acceptable answer with high probability, while still being empirically precise (i.e., small) on average. Furthermore, within this set of candidate responses, we show that we can also accurately identify subsets of individual components -- such as phrases or sentences -- that are each independently correct (e.g., that are not hallucinations), again with statistical guarantees. We demonstrate the promise of our approach on multiple tasks in open-domain question answering, text summarization, and radiology report generation using different LM variants.
Read more6/4/2024
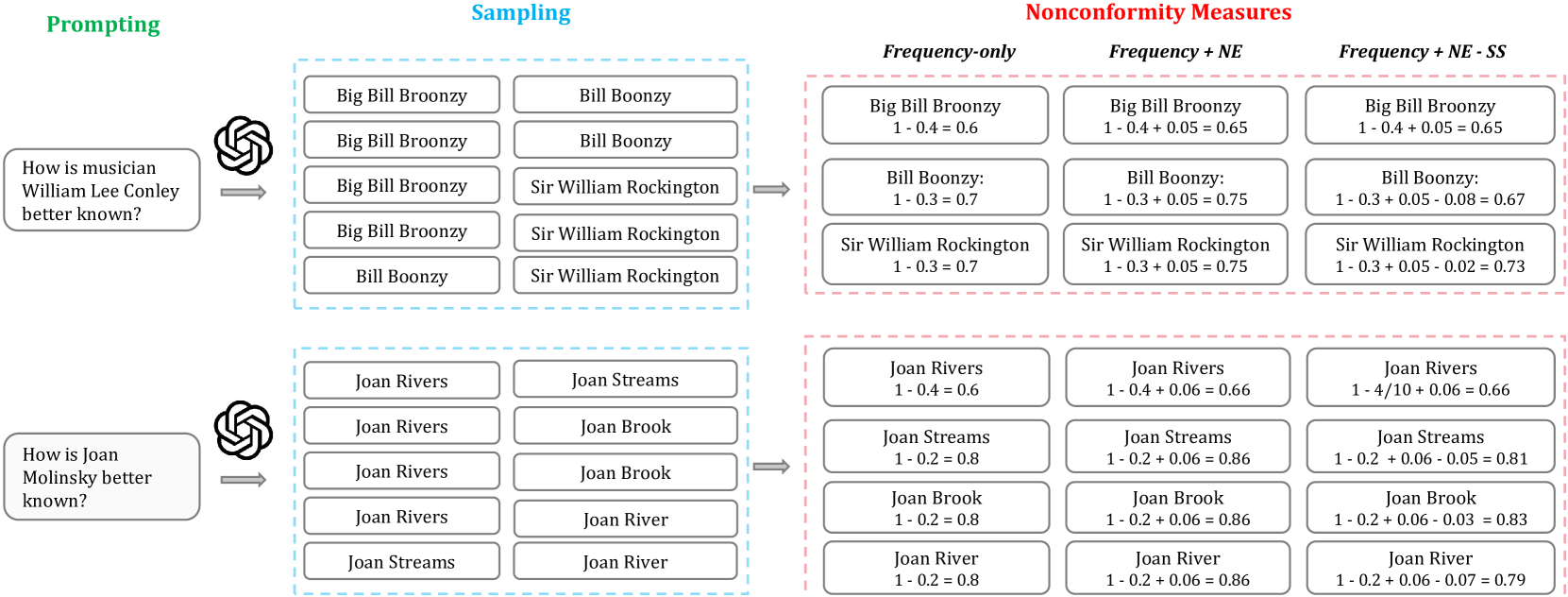
0
API Is Enough: Conformal Prediction for Large Language Models Without Logit-Access
Jiayuan Su, Jing Luo, Hongwei Wang, Lu Cheng
This study aims to address the pervasive challenge of quantifying uncertainty in large language models (LLMs) without logit-access. Conformal Prediction (CP), known for its model-agnostic and distribution-free features, is a desired approach for various LLMs and data distributions. However, existing CP methods for LLMs typically assume access to the logits, which are unavailable for some API-only LLMs. In addition, logits are known to be miscalibrated, potentially leading to degraded CP performance. To tackle these challenges, we introduce a novel CP method that (1) is tailored for API-only LLMs without logit-access; (2) minimizes the size of prediction sets; and (3) ensures a statistical guarantee of the user-defined coverage. The core idea of this approach is to formulate nonconformity measures using both coarse-grained (i.e., sample frequency) and fine-grained uncertainty notions (e.g., semantic similarity). Experimental results on both close-ended and open-ended Question Answering tasks show our approach can mostly outperform the logit-based CP baselines.
Read more4/5/2024