Convex SGD: Generalization Without Early Stopping
2401.04067
0
0
👁️
Abstract
We consider the generalization error associated with stochastic gradient descent on a smooth convex function over a compact set. We show the first bound on the generalization error that vanishes when the number of iterations $T$ and the dataset size $n$ go to zero at arbitrary rates; our bound scales as $tilde{O}(1/sqrt{T} + 1/sqrt{n})$ with step-size $alpha_t = 1/sqrt{t}$. In particular, strong convexity is not needed for stochastic gradient descent to generalize well.
Create account to get full access
Overview
- The paper investigates the generalization error associated with stochastic gradient descent (SGD) on a smooth convex function over a compact set.
- It presents the first bound on the generalization error that vanishes as the number of iterations (T) and dataset size (n) approach zero at any rate.
- The bound scales as
tilde{O}(1/sqrt{T} + 1/sqrt{n})with a step-size ofalpha_t = 1/sqrt{t}. - The key finding is that strong convexity is not required for SGD to generalize well.
Plain English Explanation
In this study, the researchers looked at how well a machine learning technique called stochastic gradient descent (SGD) can "generalize" or perform on new, unseen data when applied to a smooth, convex function over a limited set of values. Convex functions are a special type of function that have a specific mathematical property, and they're commonly used in optimization problems.
The researchers were able to show a new mathematical bound, or limit, on the generalization error of SGD. This bound becomes smaller as the number of times SGD is run (the "number of iterations", denoted T) and the size of the dataset (n) increase, but it can do so at any rate. Importantly, they found that SGD can generalize well without the function being "strongly convex" - a stricter mathematical property that was previously thought to be necessary.
The researchers' bound scales in a specific way: it goes down as 1 divided by the square root of T, plus 1 divided by the square root of n. This means the generalization error decreases more slowly as the dataset size increases, compared to how quickly it decreases as the number of iterations increases. The step-size, or learning rate, used in SGD also plays a role, with the optimal choice being 1 divided by the square root of the current iteration.
Technical Explanation
The paper analyzes the generalization error of stochastic gradient descent (SGD) when optimizing a smooth, convex function over a compact set. They derive the first bound on the generalization error that vanishes as the number of iterations T and dataset size n approach zero at arbitrary rates.
Specifically, they show that the generalization error scales as tilde{O}(1/sqrt{T} + 1/sqrt{n}), using a step-size of alpha_t = 1/sqrt{t}. This bound holds without requiring strong convexity of the objective function, in contrast to previous results that relied on strong convexity assumptions.
The key technical innovations include:
- Analyzing the generalization error directly, rather than bounding the excess risk or optimization error as in prior work. This allows the bound to be independent of the strong convexity parameter.
- Carefully controlling the martingale terms that arise in the stochastic optimization setting, using tools from empirical process theory.
- Leveraging the smooth and convex structure of the objective function to obtain improved dependence on the number of iterations
Tand dataset sizen.
The results demonstrate that SGD can generalize well even without strong convexity, providing new insights into the generalization properties of this widely-used optimization algorithm. The findings have implications for a variety of machine learning problems where convex optimization techniques are applied.
Critical Analysis
The paper provides a strong theoretical analysis of the generalization properties of stochastic gradient descent (SGD) under mild convexity assumptions. The authors are able to derive a novel bound on the generalization error that improves upon previous results which required stronger assumptions, such as strong convexity.
One potential limitation is that the analysis is focused on the asymptotic regime where the number of iterations T and dataset size n approach infinity. It would be valuable to understand the practical implications of the bounds for realistic problem sizes. Additionally, the paper does not provide any experimental validation of the theoretical results.
Further research could explore extensions to other optimization algorithms, such as accelerated gradient methods or constrained optimization. Investigating the role of other problem structure, such as sparsity or low-rank, could also lead to tighter generalization bounds.
Overall, the paper makes an important theoretical contribution by providing new insights into the generalization properties of SGD without strong convexity assumptions. The results highlight the robust nature of this widely-used optimization technique and open up avenues for further research.
Conclusion
This paper presents a novel analysis of the generalization error associated with stochastic gradient descent (SGD) on smooth, convex functions. The key finding is that SGD can generalize well without requiring strong convexity of the objective function, in contrast to prior results.
The researchers derive a bound on the generalization error that scales as tilde{O}(1/sqrt{T} + 1/sqrt{n}), where T is the number of iterations and n is the dataset size. This bound holds for any choice of these parameters, providing a flexible and practical result.
The theoretical analysis sheds new light on the generalization properties of SGD, a widely-used optimization method in machine learning. The findings have implications for a variety of applications where convex optimization techniques are employed, such as linear and logistic regression, neural network training, and decentralized optimization. Further research could explore extensions to other algorithms and problem structures to continue advancing our understanding of generalization in machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

The Sample Complexity of Gradient Descent in Stochastic Convex Optimization
Roi Livni
0
0
We analyze the sample complexity of full-batch Gradient Descent (GD) in the setup of non-smooth Stochastic Convex Optimization. We show that the generalization error of GD, with common choice of hyper-parameters, can be $tilde Theta(d/m + 1/sqrt{m})$, where $d$ is the dimension and $m$ is the sample size. This matches the sample complexity of emph{worst-case} empirical risk minimizers. That means that, in contrast with other algorithms, GD has no advantage over naive ERMs. Our bound follows from a new generalization bound that depends on both the dimension as well as the learning rate and number of iterations. Our bound also shows that, for general hyper-parameters, when the dimension is strictly larger than number of samples, $T=Omega(1/epsilon^4)$ iterations are necessary to avoid overfitting. This resolves an open problem by Schlisserman et al.23 and Amir er Al.21, and improves over previous lower bounds that demonstrated that the sample size must be at least square root of the dimension.
4/12/2024
🔍
Improved Stability and Generalization Guarantees of the Decentralized SGD Algorithm
Batiste Le Bars, Aur'elien Bellet, Marc Tommasi, Kevin Scaman, Giovanni Neglia
0
0
This paper presents a new generalization error analysis for Decentralized Stochastic Gradient Descent (D-SGD) based on algorithmic stability. The obtained results overhaul a series of recent works that suggested an increased instability due to decentralization and a detrimental impact of poorly-connected communication graphs on generalization. On the contrary, we show, for convex, strongly convex and non-convex functions, that D-SGD can always recover generalization bounds analogous to those of classical SGD, suggesting that the choice of graph does not matter. We then argue that this result is coming from a worst-case analysis, and we provide a refined optimization-dependent generalization bound for general convex functions. This new bound reveals that the choice of graph can in fact improve the worst-case bound in certain regimes, and that surprisingly, a poorly-connected graph can even be beneficial for generalization.
6/14/2024
🛠️
Dealing with unbounded gradients in stochastic saddle-point optimization
Gergely Neu, Nneka Okolo
0
0
We study the performance of stochastic first-order methods for finding saddle points of convex-concave functions. A notorious challenge faced by such methods is that the gradients can grow arbitrarily large during optimization, which may result in instability and divergence. In this paper, we propose a simple and effective regularization technique that stabilizes the iterates and yields meaningful performance guarantees even if the domain and the gradient noise scales linearly with the size of the iterates (and is thus potentially unbounded). Besides providing a set of general results, we also apply our algorithm to a specific problem in reinforcement learning, where it leads to performance guarantees for finding near-optimal policies in an average-reward MDP without prior knowledge of the bias span.
6/10/2024
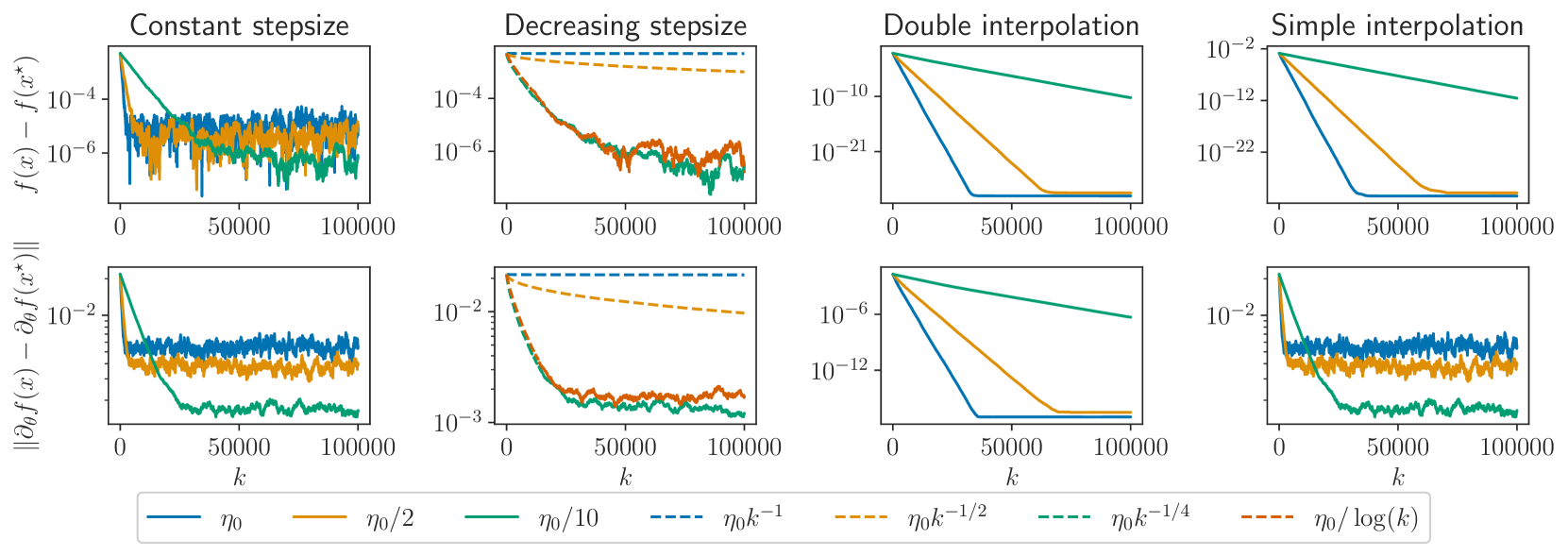
Derivatives of Stochastic Gradient Descent
Franck Iutzeler, Edouard Pauwels, Samuel Vaiter
0
0
We consider stochastic optimization problems where the objective depends on some parameter, as commonly found in hyperparameter optimization for instance. We investigate the behavior of the derivatives of the iterates of Stochastic Gradient Descent (SGD) with respect to that parameter and show that they are driven by an inexact SGD recursion on a different objective function, perturbed by the convergence of the original SGD. This enables us to establish that the derivatives of SGD converge to the derivative of the solution mapping in terms of mean squared error whenever the objective is strongly convex. Specifically, we demonstrate that with constant step-sizes, these derivatives stabilize within a noise ball centered at the solution derivative, and that with vanishing step-sizes they exhibit $O(log(k)^2 / k)$ convergence rates. Additionally, we prove exponential convergence in the interpolation regime. Our theoretical findings are illustrated by numerical experiments on synthetic tasks.
5/28/2024