CoReS: Orchestrating the Dance of Reasoning and Segmentation

0

Sign in to get full access
Overview
- This paper presents CoReS, a model that combines reasoning and segmentation to address complex multi-modal tasks.
- CoReS leverages a chain-of-thought approach to integrate reasoning and segmentation in a unified framework.
- The model demonstrates strong performance on various benchmarks, showcasing the benefits of orchestrating reasoning and segmentation.
Plain English Explanation
CoReS is a new machine learning model that combines two important abilities: reasoning and segmentation. Reasoning is the skill of understanding and drawing conclusions, while segmentation is the ability to break down complex information into smaller, meaningful parts.
The researchers behind CoReS realized that many real-world problems require both reasoning and segmentation to solve effectively. For example, if you're trying to understand a medical image, you might need to reason about what the different parts of the image represent, and then segment the image to focus on the most important regions.
CoReS tackles this challenge by using a "chain-of-thought" approach. This means the model doesn't just provide a single answer, but instead goes through a step-by-step process of reasoning and segmentation to arrive at the final solution. This allows CoReS to handle more complex, multi-faceted problems than models that only do one or the other.
The researchers tested CoReS on a variety of benchmarks, and found that it outperformed other state-of-the-art models. This suggests that orchestrating reasoning and segmentation in this way can lead to significant improvements in performance on tasks that require both skills.
Technical Explanation
The CoReS model leverages a chain-of-thought approach to integrate reasoning and segmentation in a unified framework. The model consists of two main components: a Reasoning Module and a Segmentation Module.
The Reasoning Module takes in the input data (e.g., an image and a question) and generates a series of intermediate reasoning steps. These steps capture the model's step-by-step thought process as it tries to understand and reason about the problem.
The Segmentation Module then takes the input data and the reasoning steps, and generates a segmentation of the input. This segmentation reflects the model's understanding of the different parts or components of the input that are relevant to solving the problem.
The outputs of the Reasoning and Segmentation Modules are then combined to produce the final solution. This multi-modal approach allows CoReS to leverage both reasoning and segmentation capabilities to tackle complex, real-world tasks.
The researchers evaluate CoReS on a variety of benchmarks, including Paris3D for 3D part segmentation and LLM-Reasoners for multi-step reasoning. The results demonstrate the effectiveness of CoReS in orchestrating the dance of reasoning and segmentation to achieve state-of-the-art performance on these challenging tasks.
Critical Analysis
The researchers provide a comprehensive evaluation of CoReS, highlighting its strong performance across multiple benchmarks. However, the paper does not delve deeply into the limitations or potential issues with the model.
One area that could benefit from further exploration is the interpretability of the reasoning steps generated by the Reasoning Module. While the chain-of-thought approach is compelling, it's unclear how transparent and understandable these reasoning steps are to human users. Improving the interpretability of the model's decision-making process could enhance its real-world applicability and trust.
Additionally, the paper does not discuss the computational complexity and resource requirements of CoReS, which could be an important consideration for deployment in practical scenarios. Exploring trade-offs between model performance and efficiency would help provide a more well-rounded assessment of the model's capabilities and limitations.
Conclusion
The CoReS model presents a promising approach to combining reasoning and segmentation for complex, multi-modal tasks. By orchestrating these two key capabilities in a unified framework, the model demonstrates strong performance on a variety of benchmarks, highlighting the potential benefits of this integrated approach.
As the field of AI continues to advance, the ability to seamlessly combine different cognitive skills will become increasingly important. The insights and techniques developed in the CoReS research could inspire further advancements in multi-modal learning and the development of more versatile and capable AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CoReS: Orchestrating the Dance of Reasoning and Segmentation
Xiaoyi Bao, Siyang Sun, Shuailei Ma, Kecheng Zheng, Yuxin Guo, Guosheng Zhao, Yun Zheng, Xingang Wang
The reasoning segmentation task, which demands a nuanced comprehension of intricate queries to accurately pinpoint object regions, is attracting increasing attention. However, Multi-modal Large Language Models (MLLM) often find it difficult to accurately localize the objects described in complex reasoning contexts. We believe that the act of reasoning segmentation should mirror the cognitive stages of human visual search, where each step is a progressive refinement of thought toward the final object. Thus we introduce the Chains of Reasoning and Segmenting (CoReS) and find this top-down visual hierarchy indeed enhances the visual search process. Specifically, we propose a dual-chain structure that generates multi-modal, chain-like outputs to aid the segmentation process. Furthermore, to steer the MLLM's outputs into this intended hierarchy, we incorporate in-context inputs as guidance. Extensive experiments demonstrate the superior performance of our CoReS, which surpasses the state-of-the-art method by 6.5% on the ReasonSeg dataset. Project: https://chain-of-reasoning-and-segmentation.github.io/.
Read more7/12/2024
0
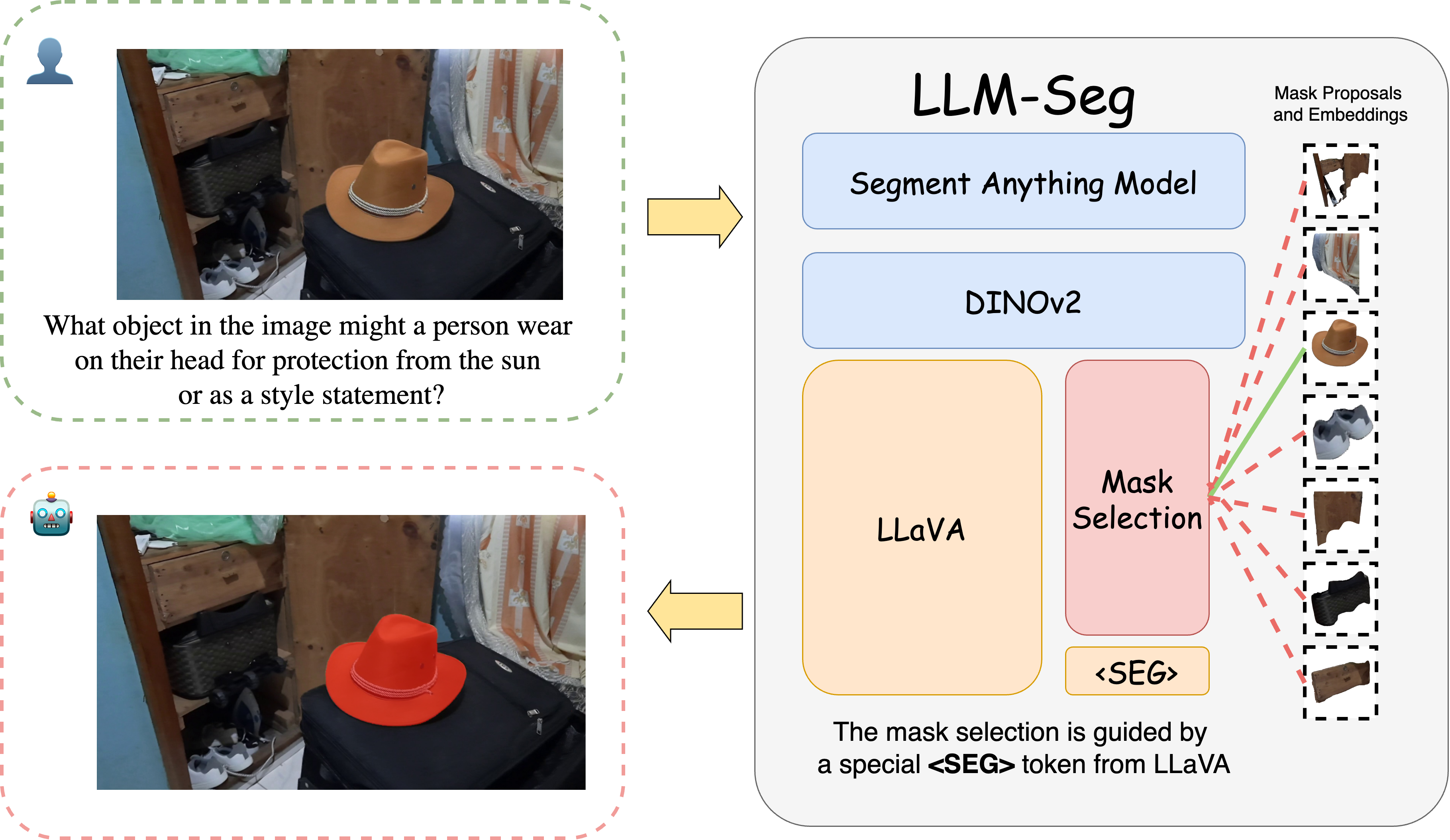
LLM-Seg: Bridging Image Segmentation and Large Language Model Reasoning
Junchi Wang, Lei Ke
Understanding human instructions to identify the target objects is vital for perception systems. In recent years, the advancements of Large Language Models (LLMs) have introduced new possibilities for image segmentation. In this work, we delve into reasoning segmentation, a novel task that enables segmentation system to reason and interpret implicit user intention via large language model reasoning and then segment the corresponding target. Our work on reasoning segmentation contributes on both the methodological design and dataset labeling. For the model, we propose a new framework named LLM-Seg. LLM-Seg effectively connects the current foundational Segmentation Anything Model and the LLM by mask proposals selection. For the dataset, we propose an automatic data generation pipeline and construct a new reasoning segmentation dataset named LLM-Seg40K. Experiments demonstrate that our LLM-Seg exhibits competitive performance compared with existing methods. Furthermore, our proposed pipeline can efficiently produce high-quality reasoning segmentation datasets. The LLM-Seg40K dataset, developed through this pipeline, serves as a new benchmark for training and evaluating various reasoning segmentation approaches. Our code, models and dataset are at https://github.com/wangjunchi/LLMSeg.
Read more4/16/2024
💬
0
LISA: Reasoning Segmentation via Large Language Model
Xin Lai, Zhuotao Tian, Yukang Chen, Yanwei Li, Yuhui Yuan, Shu Liu, Jiaya Jia
Although perception systems have made remarkable advancements in recent years, they still rely on explicit human instruction or pre-defined categories to identify the target objects before executing visual recognition tasks. Such systems cannot actively reason and comprehend implicit user intention. In this work, we propose a new segmentation task -- reasoning segmentation. The task is designed to output a segmentation mask given a complex and implicit query text. Furthermore, we establish a benchmark comprising over one thousand image-instruction-mask data samples, incorporating intricate reasoning and world knowledge for evaluation purposes. Finally, we present LISA: large Language Instructed Segmentation Assistant, which inherits the language generation capabilities of multimodal Large Language Models (LLMs) while also possessing the ability to produce segmentation masks. We expand the original vocabulary with a token and propose the embedding-as-mask paradigm to unlock the segmentation capability. Remarkably, LISA can handle cases involving complex reasoning and world knowledge. Also, it demonstrates robust zero-shot capability when trained exclusively on reasoning-free datasets. In addition, fine-tuning the model with merely 239 reasoning segmentation data samples results in further performance enhancement. Both quantitative and qualitative experiments show our method effectively unlocks new reasoning segmentation capabilities for multimodal LLMs. Code, models, and data are available at https://github.com/dvlab-research/LISA.
Read more5/2/2024
💬
28
Multimodal Chain-of-Thought Reasoning in Language Models
Zhuosheng Zhang, Aston Zhang, Mu Li, Hai Zhao, George Karypis, Alex Smola
Large language models (LLMs) have shown impressive performance on complex reasoning by leveraging chain-of-thought (CoT) prompting to generate intermediate reasoning chains as the rationale to infer the answer. However, existing CoT studies have primarily focused on the language modality. We propose Multimodal-CoT that incorporates language (text) and vision (images) modalities into a two-stage framework that separates rationale generation and answer inference. In this way, answer inference can leverage better generated rationales that are based on multimodal information. Experimental results on ScienceQA and A-OKVQA benchmark datasets show the effectiveness of our proposed approach. With Multimodal-CoT, our model under 1 billion parameters achieves state-of-the-art performance on the ScienceQA benchmark. Our analysis indicates that Multimodal-CoT offers the advantages of mitigating hallucination and enhancing convergence speed. Code is publicly available at https://github.com/amazon-science/mm-cot.
Read more5/21/2024