Debiased Collaborative Filtering with Kernel-Based Causal Balancing
2404.19596
0
0
🤔
Abstract
Debiased collaborative filtering aims to learn an unbiased prediction model by removing different biases in observational datasets. To solve this problem, one of the simple and effective methods is based on the propensity score, which adjusts the observational sample distribution to the target one by reweighting observed instances. Ideally, propensity scores should be learned with causal balancing constraints. However, existing methods usually ignore such constraints or implement them with unreasonable approximations, which may affect the accuracy of the learned propensity scores. To bridge this gap, in this paper, we first analyze the gaps between the causal balancing requirements and existing methods such as learning the propensity with cross-entropy loss or manually selecting functions to balance. Inspired by these gaps, we propose to approximate the balancing functions in reproducing kernel Hilbert space and demonstrate that, based on the universal property and representer theorem of kernel functions, the causal balancing constraints can be better satisfied. Meanwhile, we propose an algorithm that adaptively balances the kernel function and theoretically analyze the generalization error bound of our methods. We conduct extensive experiments to demonstrate the effectiveness of our methods, and to promote this research direction, we have released our project at https://github.com/haoxuanli-pku/ICLR24-Kernel-Balancing.
Create account to get full access
Overview
- The research paper focuses on debiasing collaborative filtering, which aims to learn an unbiased prediction model by removing different biases in observational datasets.
- One effective method is based on the propensity score, which adjusts the observational sample distribution to the target one by reweighting observed instances.
- Existing methods usually ignore the causal balancing constraints or implement them with unreasonable approximations, which may affect the accuracy of the learned propensity scores.
Plain English Explanation
The paper discusses a way to improve the accuracy of recommendation systems by addressing bias in the data they're trained on. Recommendation systems, like those used by e-commerce sites to suggest products, can be skewed by various types of bias present in the data they're trained on. For example, the data may over-represent certain demographics or popular products.
To address this, the researchers use a technique called propensity score adjustment. This adjusts the distribution of the training data to better match the target distribution, reducing the impact of bias. Ideally, the propensity scores should be learned in a way that satisfies certain "causal balancing" constraints, which ensure the adjusted data properly represents the underlying relationships.
However, the researchers found that existing methods often ignore these constraints or implement them poorly, which can limit the effectiveness of the debiasing. To address this, the paper proposes a new approach that approximates the balancing functions in a way that better satisfies the causal constraints. This is done by representing the balancing functions in a mathematical space called a "reproducing kernel Hilbert space", which has useful theoretical properties.
Technical Explanation
The key technical contributions of the paper are:
-
Analyzing the gaps between the causal balancing requirements and existing propensity score learning methods, which often ignore the constraints or use poor approximations.
-
Proposing to approximate the balancing functions in a reproducing kernel Hilbert space, leveraging the universal property and representer theorem of kernel functions to better satisfy the causal balancing constraints.
-
Developing an algorithm that adaptively balances the kernel function, and providing a theoretical analysis of the generalization error bound of their method.
The researchers evaluate their approach through extensive experiments, and have released the code for their method as an open-source project to promote further research in this direction.
Critical Analysis
The paper provides a well-grounded theoretical approach to address the limitations of existing propensity score-based debiasing methods. By focusing on satisfying the causal balancing constraints, the proposed kernel-based approximation appears to be a promising direction.
However, the paper does not discuss the potential computational complexity of the kernel-based optimization, which could be a concern for large-scale recommendation systems. Additionally, the experiments are limited to simulated datasets, and further validation on real-world recommendation scenarios would be valuable.
Another area for further research is exploring how the proposed debiasing method could be combined with other fairness-enhancing techniques, such as those that address other sources of bias or unfairness in recommender systems.
Conclusion
This research paper presents an innovative approach to debiasing collaborative filtering by focusing on satisfying causal balancing constraints in the propensity score learning process. The kernel-based approximation method shows promise in improving the accuracy of the debiased prediction model, though further research is needed to understand its practical implications and potential integration with other fairness-aware techniques in recommender systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
Calibrated and Conformal Propensity Scores for Causal Effect Estimation
Shachi Deshpande, Volodymyr Kuleshov
0
0
Propensity scores are commonly used to estimate treatment effects from observational data. We argue that the probabilistic output of a learned propensity score model should be calibrated -- i.e., a predictive treatment probability of 90% should correspond to 90% of individuals being assigned the treatment group -- and we propose simple recalibration techniques to ensure this property. We prove that calibration is a necessary condition for unbiased treatment effect estimation when using popular inverse propensity weighted and doubly robust estimators. We derive error bounds on causal effect estimates that directly relate to the quality of uncertainties provided by the probabilistic propensity score model and show that calibration strictly improves this error bound while also avoiding extreme propensity weights. We demonstrate improved causal effect estimation with calibrated propensity scores in several tasks including high-dimensional image covariates and genome-wide association studies (GWASs). Calibrated propensity scores improve the speed of GWAS analysis by more than two-fold by enabling the use of simpler models that are faster to train.
6/6/2024
✅
Kernel Ridge Riesz Representers: Generalization Error and Mis-specification
Rahul Singh
0
0
Kernel balancing weights provide confidence intervals for average treatment effects, based on the idea of balancing covariates for the treated group and untreated group in feature space, often with ridge regularization. Previous works on the classical kernel ridge balancing weights have certain limitations: (i) not articulating generalization error for the balancing weights, (ii) typically requiring correct specification of features, and (iii) providing inference for only average effects. I interpret kernel balancing weights as kernel ridge Riesz representers (KRRR) and address these limitations via a new characterization of the counterfactual effective dimension. KRRR is an exact generalization of kernel ridge regression and kernel ridge balancing weights. I prove strong properties similar to kernel ridge regression: population $L_2$ rates controlling generalization error, and a standalone closed form solution that can interpolate. The framework relaxes the stringent assumption that the underlying regression model is correctly specified by the features. It extends inference beyond average effects to heterogeneous effects, i.e. causal functions. I use KRRR to infer heterogeneous treatment effects, by age, of 401(k) eligibility on assets.
6/4/2024
📉
Fair Mixed Effects Support Vector Machine
Jo~ao Vitor Pamplona, Jan Pablo Burgard
0
0
To ensure unbiased and ethical automated predictions, fairness must be a core principle in machine learning applications. Fairness in machine learning aims to mitigate biases present in the training data and model imperfections that could lead to discriminatory outcomes. This is achieved by preventing the model from making decisions based on sensitive characteristics like ethnicity or sexual orientation. A fundamental assumption in machine learning is the independence of observations. However, this assumption often does not hold true for data describing social phenomena, where data points are often clustered based. Hence, if the machine learning models do not account for the cluster correlations, the results may be biased. Especially high is the bias in cases where the cluster assignment is correlated to the variable of interest. We present a fair mixed effects support vector machine algorithm that can handle both problems simultaneously. With a reproducible simulation study we demonstrate the impact of clustered data on the quality of fair machine learning predictions.
5/24/2024
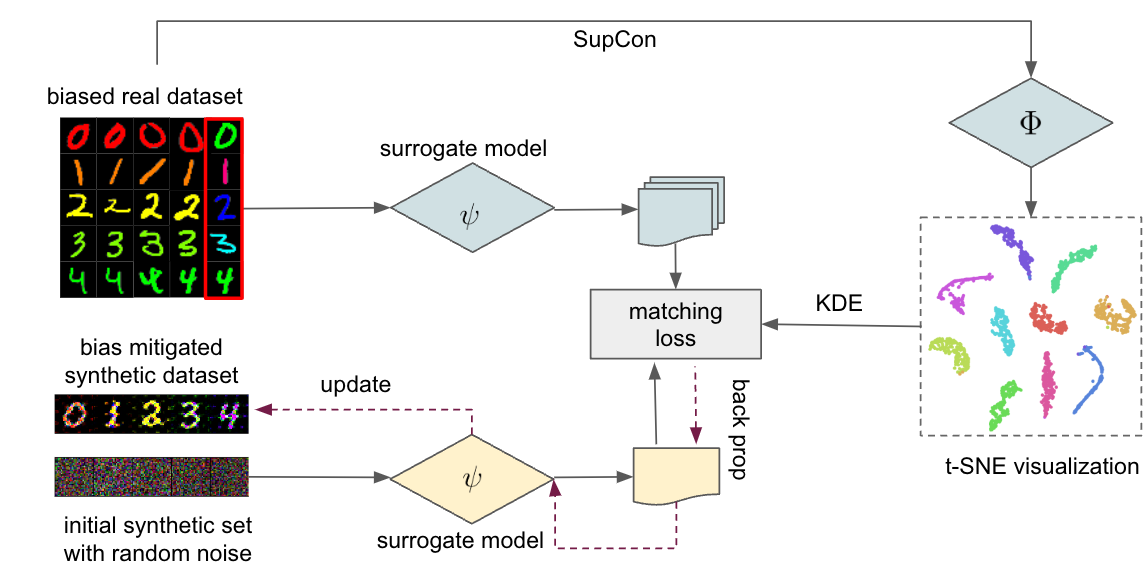
Ameliorate Spurious Correlations in Dataset Condensation
Justin Cui, Ruochen Wang, Yuanhao Xiong, Cho-Jui Hsieh
0
0
Dataset Condensation has emerged as a technique for compressing large datasets into smaller synthetic counterparts, facilitating downstream training tasks. In this paper, we study the impact of bias inside the original dataset on the performance of dataset condensation. With a comprehensive empirical evaluation on canonical datasets with color, corruption and background biases, we found that color and background biases in the original dataset will be amplified through the condensation process, resulting in a notable decline in the performance of models trained on the condensed dataset, while corruption bias is suppressed through the condensation process. To reduce bias amplification in dataset condensation, we introduce a simple yet highly effective approach based on a sample reweighting scheme utilizing kernel density estimation. Empirical results on multiple real-world and synthetic datasets demonstrate the effectiveness of the proposed method. Notably, on CMNIST with 5% bias-conflict ratio and IPC 50, our method achieves 91.5% test accuracy compared to 23.8% from vanilla DM, boosting the performance by 67.7%, whereas applying state-of-the-art debiasing method on the same dataset only achieves 53.7% accuracy. Our findings highlight the importance of addressing biases in dataset condensation and provide a promising avenue to address bias amplification in the process.
6/12/2024