Cost Function Unrolling in Unsupervised Optical Flow
2011.14814
0
0
🤷
Abstract
Steepest descent algorithms, which are commonly used in deep learning, use the gradient as the descent direction, either as-is or after a direction shift using preconditioning. In many scenarios calculating the gradient is numerically hard due to complex or non-differentiable cost functions, specifically next to singular points. In this work we focus on the derivation of the Total Variation semi-norm commonly used in unsupervised cost functions. Specifically, we derive a differentiable proxy to the hard L1 smoothness constraint in a novel iterative scheme which we refer to as Cost Unrolling. Producing more accurate gradients during training, our method enables finer predictions of a given DNN model through improved convergence, without modifying its architecture or increasing computational complexity. We demonstrate our method in the unsupervised optical flow task. Replacing the L1 smoothness constraint with our unrolled cost during the training of a well known baseline, we report improved results on both MPI Sintel and KITTI 2015 unsupervised optical flow benchmarks. Particularly, we report EPE reduced by up to 15.82% on occluded pixels, where the smoothness constraint is dominant, enabling the detection of much sharper motion edges.
Create account to get full access
Overview
- Steepest descent algorithms, commonly used in deep learning, rely on the gradient as the descent direction
- Calculating the gradient can be numerically challenging due to complex or non-differentiable cost functions, especially near singular points
- This paper focuses on deriving a differentiable proxy for the Total Variation semi-norm, which is commonly used in unsupervised cost functions
Plain English Explanation
In deep learning, a common technique called the "steepest descent algorithm" is used to train models. This algorithm relies on the gradient - a measure of how the cost function changes as the model parameters are adjusted - to determine the direction in which to update the parameters.
However, calculating the gradient can be tricky when the cost function is complex or not easily differentiable, especially near certain points called "singular points." This paper introduces a new method to address this challenge.
The key idea is to derive a differentiable proxy, or stand-in, for a mathematical concept called the "Total Variation semi-norm." This is a common component of unsupervised cost functions, which are used to train models without labeled data. By finding a differentiable version of this component, the authors can compute more accurate gradients during training, leading to better model performance without increasing the computational complexity.
The authors demonstrate their method on the task of unsupervised optical flow, which involves estimating the motion of objects in a video. By replacing the original smoothness constraint with their new differentiable version, they are able to achieve improved results on standard benchmarks, particularly in detecting sharp motion edges.
Technical Explanation
The paper focuses on the Total Variation semi-norm, a mathematical construct commonly used in unsupervised cost functions. The authors derive a differentiable proxy for this term, which they call "Cost Unrolling," and integrate it into the training of a deep neural network for unsupervised optical flow estimation.
The key contributions are:
- Deriving a differentiable approximation of the Total Variation semi-norm through an iterative scheme, which enables more accurate gradient computation during training.
- Incorporating this differentiable proxy into the training of a well-known unsupervised optical flow model, leading to improved results on standard benchmarks like MPI Sintel and KITTI 2015.
- Demonstrating that the method is particularly effective in improving the detection of sharp motion edges, where the smoothness constraint is dominant.
The authors show that their "Cost Unrolling" approach outperforms the original L1 smoothness constraint by up to 15.82% on occluded pixels, indicating that the new differentiable proxy can better capture the underlying structure of the data.
Critical Analysis
The paper presents a compelling approach to addressing the numerical challenges associated with calculating gradients for complex cost functions in deep learning. The authors' focus on deriving a differentiable proxy for the Total Variation semi-norm is a valuable contribution, as this term is widely used in unsupervised learning.
One potential limitation is the specific application to unsupervised optical flow estimation. While the results on standard benchmarks are promising, it would be interesting to see how the "Cost Unrolling" method performs on a wider range of unsupervised learning tasks, such as image segmentation or adversarial training.
Additionally, the authors mention that their method relies on a specific form of the Total Variation semi-norm, and it's unclear how it would generalize to other variants or more complex regularization terms. Further research could explore the broader applicability of the "Cost Unrolling" approach.
Overall, this paper makes a valuable contribution to the field of deep learning by addressing a fundamental challenge in gradient computation. The authors' novel solution and its demonstrated success in improving unsupervised optical flow estimation suggest promising avenues for future research and development.
Conclusion
This paper presents a new method called "Cost Unrolling" that addresses the challenge of computing accurate gradients for deep learning models with complex or non-differentiable cost functions. By deriving a differentiable proxy for the Total Variation semi-norm, a common component of unsupervised cost functions, the authors enable more precise gradient estimation during training.
The authors demonstrate the effectiveness of their approach on the task of unsupervised optical flow estimation, where they achieve improved results on standard benchmarks, particularly in detecting sharp motion edges. This work represents an important step forward in overcoming the numerical challenges associated with gradient computation, and its potential extends beyond the specific application presented here.
As deep learning continues to tackle increasingly complex problems, techniques like "Cost Unrolling" that can improve the stability and accuracy of training will become increasingly valuable. This paper serves as a valuable contribution to the ongoing efforts to advance the state of the art in deep learning research and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤷
Unsupervised Learning of the Total Variation Flow
Tamara G. Grossmann, Soren Dittmer, Yury Korolev, Carola-Bibiane Schonlieb
0
0
The total variation (TV) flow generates a scale-space representation of an image based on the TV functional. This gradient flow observes desirable features for images, such as sharp edges and enables spectral, scale, and texture analysis. Solving the TV flow is challenging; one reason is the the non-uniqueness of the subgradients. The standard numerical approach for TV flow requires solving multiple non-smooth optimisation problems. Even with state-of-the-art convex optimisation techniques, this is often prohibitively expensive and strongly motivates the use of alternative, faster approaches. Inspired by and extending the framework of physics-informed neural networks (PINNs), we propose the TVflowNET, an unsupervised neural network approach, to approximate the solution of the TV flow given an initial image and a time instance. The TVflowNET requires no ground truth data but rather makes use of the PDE for optimisation of the network parameters. We circumvent the challenges related to the non-uniqueness of the subgradients by additionally learning the related diffusivity term. Our approach significantly speeds up the computation time and we show that the TVflowNET approximates the TV flow solution with high fidelity for different image sizes and image types. Additionally, we give a full comparison of different network architecture designs as well as training regimes to underscore the effectiveness of our approach.
4/23/2024
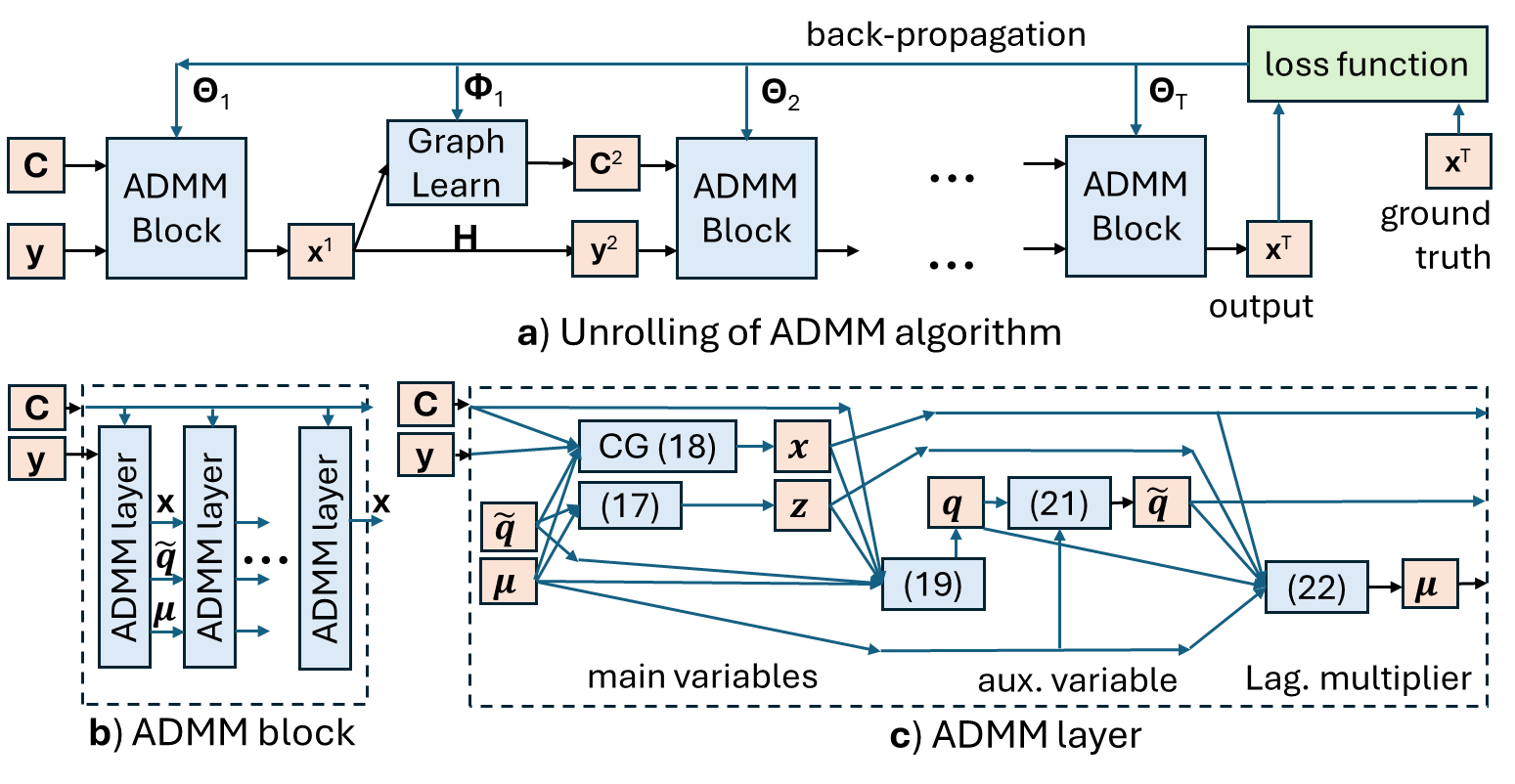
Interpretable Lightweight Transformer via Unrolling of Learned Graph Smoothness Priors
Tam Thuc Do, Parham Eftekhar, Seyed Alireza Hosseini, Gene Cheung, Philip Chou
0
0
We build interpretable and lightweight transformer-like neural networks by unrolling iterative optimization algorithms that minimize graph smoothness priors -- the quadratic graph Laplacian regularizer (GLR) and the $ell_1$-norm graph total variation (GTV) -- subject to an interpolation constraint. The crucial insight is that a normalized signal-dependent graph learning module amounts to a variant of the basic self-attention mechanism in conventional transformers. Unlike black-box transformers that require learning of large key, query and value matrices to compute scaled dot products as affinities and subsequent output embeddings, resulting in huge parameter sets, our unrolled networks employ shallow CNNs to learn low-dimensional features per node to establish pairwise Mahalanobis distances and construct sparse similarity graphs. At each layer, given a learned graph, the target interpolated signal is simply a low-pass filtered output derived from the minimization of an assumed graph smoothness prior, leading to a dramatic reduction in parameter count. Experiments for two image interpolation applications verify the restoration performance, parameter efficiency and robustness to covariate shift of our graph-based unrolled networks compared to conventional transformers.
6/7/2024
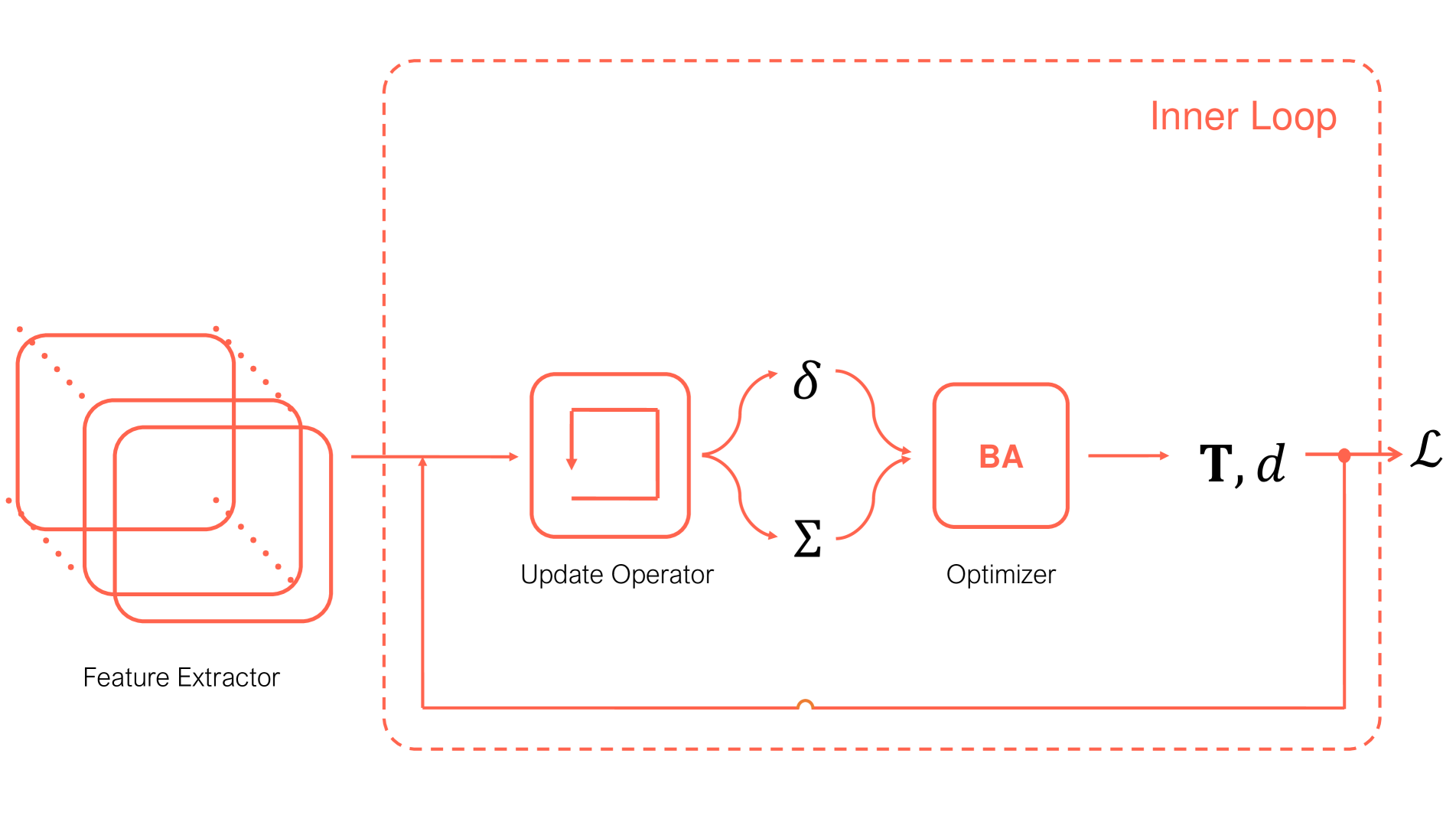
From Variance to Veracity: Unbundling and Mitigating Gradient Variance in Differentiable Bundle Adjustment Layers
Swaminathan Gurumurthy, Karnik Ram, Bingqing Chen, Zachary Manchester, Zico Kolter
0
0
Various pose estimation and tracking problems in robotics can be decomposed into a correspondence estimation problem (often computed using a deep network) followed by a weighted least squares optimization problem to solve for the poses. Recent work has shown that coupling the two problems by iteratively refining one conditioned on the other's output yields SOTA results across domains. However, training these models has proved challenging, requiring a litany of tricks to stabilize and speed up training. In this work, we take the visual odometry problem as an example and identify three plausible causes: (1) flow loss interference, (2) linearization errors in the bundle adjustment (BA) layer, and (3) dependence of weight gradients on the BA residual. We show how these issues result in noisy and higher variance gradients, potentially leading to a slow down in training and instabilities. We then propose a simple, yet effective solution to reduce the gradient variance by using the weights predicted by the network in the inner optimization loop to weight the correspondence objective in the training problem. This helps the training objective `focus' on the more important points, thereby reducing the variance and mitigating the influence of outliers. We show that the resulting method leads to faster training and can be more flexibly trained in varying training setups without sacrificing performance. In particular we show $2$--$2.5times$ training speedups over a baseline visual odometry model we modify.
6/13/2024
🤷
UnSAMFlow: Unsupervised Optical Flow Guided by Segment Anything Model
Shuai Yuan, Lei Luo, Zhuo Hui, Can Pu, Xiaoyu Xiang, Rakesh Ranjan, Denis Demandolx
0
0
Traditional unsupervised optical flow methods are vulnerable to occlusions and motion boundaries due to lack of object-level information. Therefore, we propose UnSAMFlow, an unsupervised flow network that also leverages object information from the latest foundation model Segment Anything Model (SAM). We first include a self-supervised semantic augmentation module tailored to SAM masks. We also analyze the poor gradient landscapes of traditional smoothness losses and propose a new smoothness definition based on homography instead. A simple yet effective mask feature module has also been added to further aggregate features on the object level. With all these adaptations, our method produces clear optical flow estimation with sharp boundaries around objects, which outperforms state-of-the-art methods on both KITTI and Sintel datasets. Our method also generalizes well across domains and runs very efficiently.
5/7/2024