From Variance to Veracity: Unbundling and Mitigating Gradient Variance in Differentiable Bundle Adjustment Layers

0
Sign in to get full access
Overview
- This paper introduces a new technique called "Differentiable Bundle Adjustment Layers" that can be used to improve the performance of machine learning models in computer vision tasks.
- The key innovation is a method for reducing the variance in the gradients used to train these models, which can lead to more stable and effective training.
- The paper also provides insights into the underlying factors that contribute to gradient variance in bundle adjustment layers, and proposes several strategies for mitigating this issue.
Plain English Explanation
Gradient variance is a common problem in machine learning models that use bundle adjustment techniques, such as those used for 3D reconstruction or multi-view disparity estimation. High gradient variance can make it difficult to train these models effectively, as the updates to the model parameters become unstable and unpredictable.
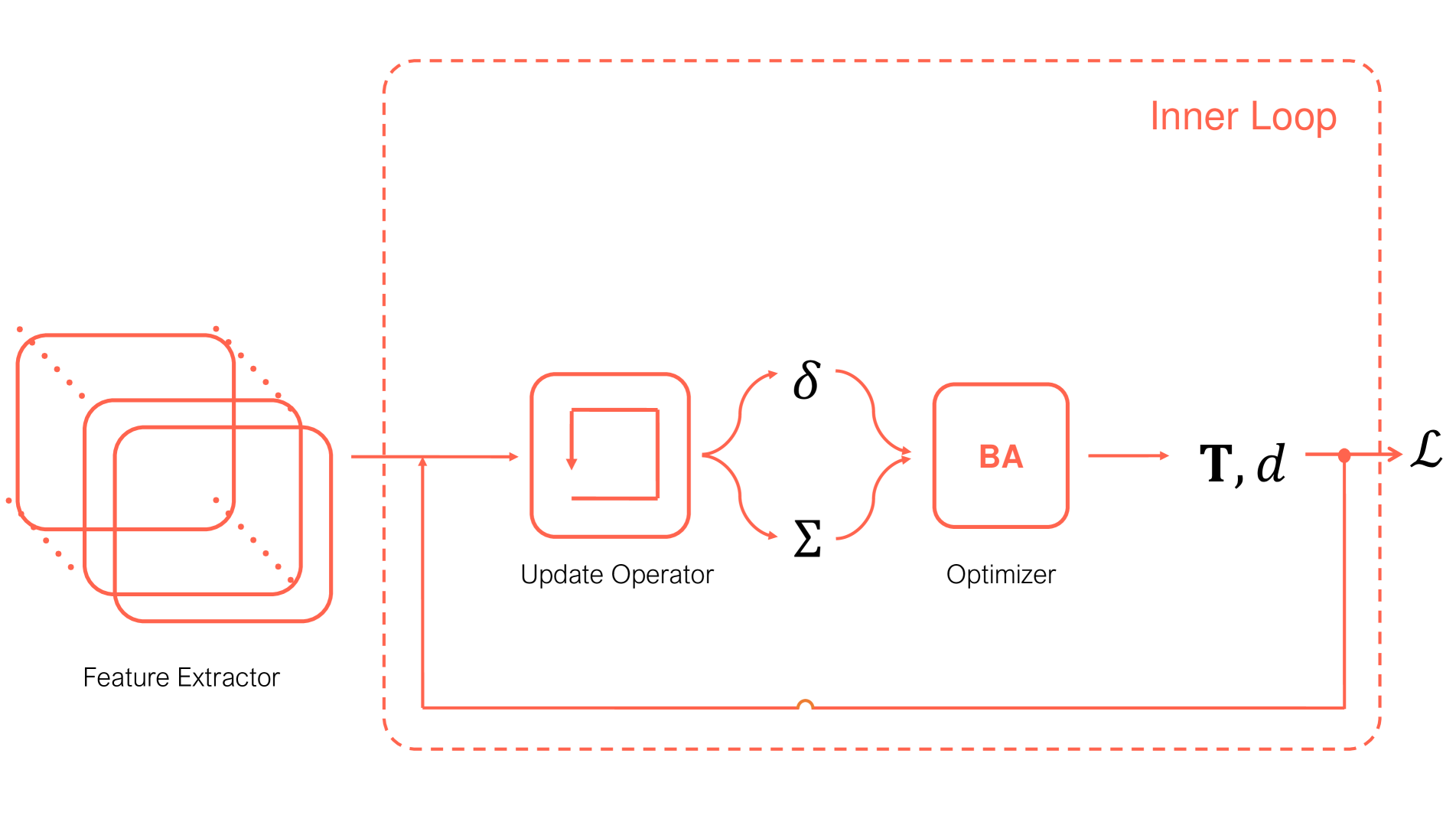
The researchers in this paper have developed a new approach called "Differentiable Bundle Adjustment Layers" that helps to reduce the gradient variance. The key idea is to "unbundle" the bundle adjustment process, breaking it down into smaller, more manageable components. This allows the model to better understand the individual factors contributing to the gradient variance, and apply targeted techniques to mitigate them.
For example, the paper discusses how the choice of initialization and the use of variance reduction techniques can both play a significant role in reducing gradient variance. By applying these strategies within the differentiable bundle adjustment layers, the researchers were able to achieve more stable and effective training of their models.
Technical Explanation
The core of the paper's contribution is the introduction of "Differentiable Bundle Adjustment Layers", which are designed to improve the training of machine learning models that rely on bundle adjustment techniques. Bundle adjustment is a common approach in computer vision for tasks like 3D reconstruction and multi-view disparity estimation, but it can suffer from high gradient variance during training.
The key innovation in this paper is the idea of "unbundling" the bundle adjustment process, breaking it down into smaller, more manageable components. This allows the model to better understand the individual factors contributing to the gradient variance, and apply targeted techniques to mitigate them. For example, the paper discusses the importance of initialization and the use of variance reduction techniques within the differentiable bundle adjustment layers.
Through extensive experimentation, the researchers demonstrate that their approach can lead to significant improvements in the stability and effectiveness of training for a variety of computer vision models that rely on bundle adjustment.
Critical Analysis
The researchers in this paper have made a valuable contribution to the field of computer vision by addressing a key challenge in the training of bundle adjustment-based models. By introducing the concept of differentiable bundle adjustment layers and providing strategies for mitigating gradient variance, they have laid the groundwork for more robust and reliable computer vision systems.
That said, the paper does acknowledge some limitations of their approach. For example, the researchers note that the effectiveness of their techniques may depend on the specific architecture and problem domain of the model being trained. Additionally, they suggest that further research is needed to fully understand the complex interplay between different factors that contribute to gradient variance in bundle adjustment layers.
It would also be interesting to see how the differentiable bundle adjustment layers proposed in this paper could be integrated with other gradient-based optimization techniques or used in conjunction with other variance reduction strategies. This could potentially lead to even more robust and efficient training of computer vision models.
Overall, this paper represents a significant step forward in addressing a critical challenge in the field of machine learning for computer vision. The insights and techniques presented here have the potential to improve the performance and reliability of a wide range of practical applications, from 3D reconstruction to autonomous navigation.
Conclusion
This paper introduces a novel approach called "Differentiable Bundle Adjustment Layers" that can help to improve the training of machine learning models in computer vision tasks. By "unbundling" the bundle adjustment process and applying targeted techniques to mitigate gradient variance, the researchers have developed a more stable and effective way to train these types of models.
The key contributions of this work include:
- A deeper understanding of the factors that contribute to gradient variance in bundle adjustment layers
- Strategies for reducing gradient variance, such as careful initialization and the use of variance reduction techniques
- Experimental results demonstrating the effectiveness of the differentiable bundle adjustment layers in improving the performance of computer vision models
While the paper acknowledges some limitations and areas for further research, the insights and techniques presented here have the potential to significantly advance the state of the art in machine learning for computer vision. By addressing a critical challenge in the training of these models, the researchers have paved the way for more reliable and robust computer vision systems that can be applied to a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
From Variance to Veracity: Unbundling and Mitigating Gradient Variance in Differentiable Bundle Adjustment Layers
Swaminathan Gurumurthy, Karnik Ram, Bingqing Chen, Zachary Manchester, Zico Kolter
Various pose estimation and tracking problems in robotics can be decomposed into a correspondence estimation problem (often computed using a deep network) followed by a weighted least squares optimization problem to solve for the poses. Recent work has shown that coupling the two problems by iteratively refining one conditioned on the other's output yields SOTA results across domains. However, training these models has proved challenging, requiring a litany of tricks to stabilize and speed up training. In this work, we take the visual odometry problem as an example and identify three plausible causes: (1) flow loss interference, (2) linearization errors in the bundle adjustment (BA) layer, and (3) dependence of weight gradients on the BA residual. We show how these issues result in noisy and higher variance gradients, potentially leading to a slow down in training and instabilities. We then propose a simple, yet effective solution to reduce the gradient variance by using the weights predicted by the network in the inner optimization loop to weight the correspondence objective in the training problem. This helps the training objective `focus' on the more important points, thereby reducing the variance and mitigating the influence of outliers. We show that the resulting method leads to faster training and can be more flexibly trained in varying training setups without sacrificing performance. In particular we show $2$--$2.5times$ training speedups over a baseline visual odometry model we modify.
Read more6/13/2024
🤷
0
Cost Function Unrolling in Unsupervised Optical Flow
Gal Lifshitz, Dan Raviv
Steepest descent algorithms, which are commonly used in deep learning, use the gradient as the descent direction, either as-is or after a direction shift using preconditioning. In many scenarios calculating the gradient is numerically hard due to complex or non-differentiable cost functions, specifically next to singular points. In this work we focus on the derivation of the Total Variation semi-norm commonly used in unsupervised cost functions. Specifically, we derive a differentiable proxy to the hard L1 smoothness constraint in a novel iterative scheme which we refer to as Cost Unrolling. Producing more accurate gradients during training, our method enables finer predictions of a given DNN model through improved convergence, without modifying its architecture or increasing computational complexity. We demonstrate our method in the unsupervised optical flow task. Replacing the L1 smoothness constraint with our unrolled cost during the training of a well known baseline, we report improved results on both MPI Sintel and KITTI 2015 unsupervised optical flow benchmarks. Particularly, we report EPE reduced by up to 15.82% on occluded pixels, where the smoothness constraint is dominant, enabling the detection of much sharper motion edges.
Read more5/28/2024

0
Bundle Adjustment in the Eager Mode
Zitong Zhan, Huan Xu, Zihang Fang, Xinpeng Wei, Yaoyu Hu, Chen Wang
Bundle adjustment (BA) is a critical technique in various robotic applications, such as simultaneous localization and mapping (SLAM), augmented reality (AR), and photogrammetry. BA optimizes parameters such as camera poses and 3D landmarks to align them with observations. With the growing importance of deep learning in perception systems, there is an increasing need to integrate BA with deep learning frameworks for enhanced reliability and performance. However, widely-used C++-based BA frameworks, such as GTSAM, g$^2$o, and Ceres, lack native integration with modern deep learning libraries like PyTorch. This limitation affects their flexibility, adaptability, ease of debugging, and overall implementation efficiency. To address this gap, we introduce an eager-mode BA framework seamlessly integrated with PyPose, providing PyTorch-compatible interfaces with high efficiency. Our approach includes GPU-accelerated, differentiable, and sparse operations designed for 2nd-order optimization, Lie group and Lie algebra operations, and linear solvers. Our eager-mode BA on GPU demonstrates substantial runtime efficiency, achieving an average speedup of 18.5$times$, 22$times$, and 23$times$ compared to GTSAM, g$^2$o, and Ceres, respectively.
Read more9/19/2024
💬
0
Power Variable Projection for Initialization-Free Large-Scale Bundle Adjustment
Simon Weber, Je Hyeong Hong, Daniel Cremers
Most Bundle Adjustment (BA) solvers like the Levenberg-Marquardt algorithm require a good initialization. Instead, initialization-free BA remains a largely uncharted territory. The under-explored Variable Projection algorithm (VarPro) exhibits a wide convergence basin even without initialization. Coupled with object space error formulation, recent works have shown its ability to solve small-scale initialization-free bundle adjustment problem. To make such initialization-free BA approaches scalable, we introduce Power Variable Projection (PoVar), extending a recent inverse expansion method based on power series. Importantly, we link the power series expansion to Riemannian manifold optimization. This projective framework is crucial to solve large-scale bundle adjustment problems without initialization. Using the real-world BAL dataset, we experimentally demonstrate that our solver achieves state-of-the-art results in terms of speed and accuracy. To our knowledge, this work is the first to address the scalability of BA without initialization opening new venues for initialization-free structure-from-motion.
Read more8/14/2024