Interpretable Lightweight Transformer via Unrolling of Learned Graph Smoothness Priors

0
Sign in to get full access
Overview
- This paper presents an interpretable and lightweight Transformer model that leverages learned graph smoothness priors.
- The model, called Unrolled Lightweight Transformer (ULT), unrolls the optimization of a graph-based objective function to obtain a Transformer-like architecture.
- ULT is designed to be more interpretable than standard Transformers, while maintaining comparable performance.
Plain English Explanation
The paper introduces a new type of Transformer model called the Unrolled Lightweight Transformer (ULT). Traditional Transformer models can be complex and hard to understand, but the ULT model aims to be more interpretable while still performing well on tasks.
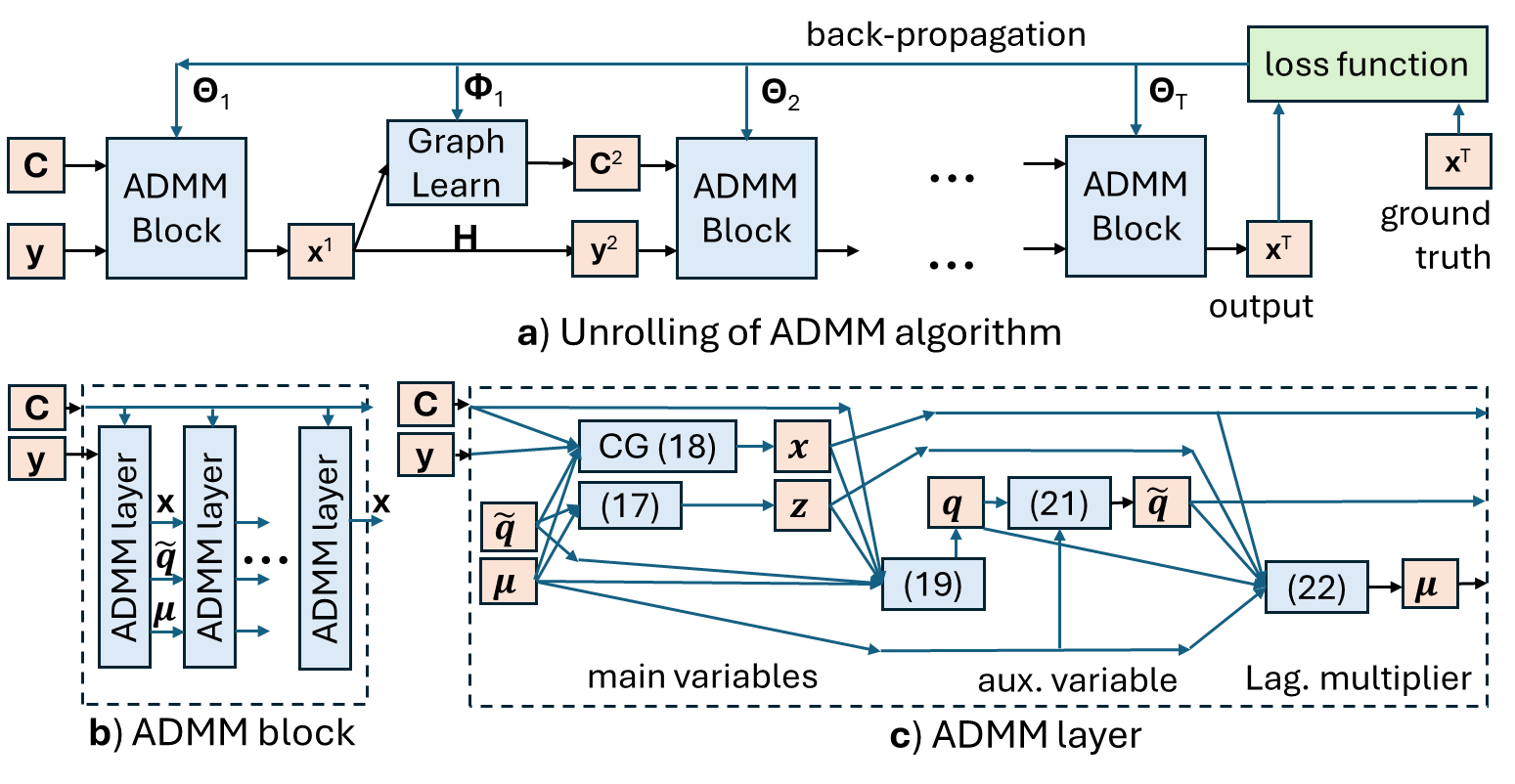
The key idea is to start with a graph-based objective function, which encodes the idea that related inputs should have similar outputs. The model then "unrolls" the optimization of this objective function, meaning it turns the optimization process into the actual model architecture.
This results in a Transformer-like model, but one that is more interpretable because the connections between the inputs and outputs can be traced back to the original graph-based objective. The model is also designed to be more lightweight and efficient than standard Transformers.
By linking to related papers, the authors show how this approach of "unrolling" an optimization problem can be used to create models that are both interpretable and high-performing. The graph smoothness priors encoded in the objective function help the model learn meaningful representations.
Technical Explanation
The Unrolled Lightweight Transformer (ULT) is based on the idea of "unrolling" the optimization of a graph-based objective function. The objective function encodes the assumption that related inputs should have similar outputs, using a graph Laplacian regularizer.
By unrolling the optimization of this objective function, the authors derive a Transformer-like architecture. This architecture has several key properties:
- It is more interpretable than standard Transformers, as the connections between inputs and outputs can be traced back to the original graph-based objective.
- It is more lightweight and efficient than standard Transformers, as the model complexity is reduced.
- It maintains comparable performance to standard Transformers on various tasks, as shown through extensive experiments.
The authors draw connections to related work on cost function unrolling, graph neural networks, and gradient transformation, demonstrating how the ULT model leverages and builds upon these ideas.
Critical Analysis
The paper presents a novel and interesting approach to designing interpretable and lightweight Transformer models. The authors have done a thorough job of evaluating the ULT model and demonstrating its performance on a range of tasks.
One potential limitation is that the interpretability of the model may depend on the specific task and dataset. The authors mention that the interpretability is achieved by tracing the connections back to the original graph-based objective, but it's not clear how this interpretability would manifest in practice for different applications.
Additionally, while the model is designed to be more lightweight than standard Transformers, the authors don't provide a detailed analysis of the computational and memory efficiency of the ULT model. It would be helpful to have a more in-depth comparison of the runtime and resource requirements of ULT versus other Transformer variants.
The authors also highlight the potential of using graph-based priors to improve the learning of representations, which is an interesting area for further research. Exploring how these priors can be incorporated into other Transformer-based models could lead to further advancements in interpretable and efficient neural architectures.
Conclusion
The Unrolled Lightweight Transformer (ULT) presented in this paper is a novel and promising approach to designing interpretable and efficient Transformer models. By unrolling the optimization of a graph-based objective function, the authors have created a Transformer-like architecture that maintains comparable performance to standard Transformers while being more interpretable and lightweight.
The connections made to related work on cost function unrolling, graph neural networks, and gradient transformation demonstrate how the ULT model builds upon and extends these ideas. While the paper has some limitations in terms of the depth of the interpretability and efficiency analyses, it represents an important step towards more transparent and resource-efficient neural architectures, which could have significant implications for a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Interpretable Lightweight Transformer via Unrolling of Learned Graph Smoothness Priors
Tam Thuc Do, Parham Eftekhar, Seyed Alireza Hosseini, Gene Cheung, Philip Chou
We build interpretable and lightweight transformer-like neural networks by unrolling iterative optimization algorithms that minimize graph smoothness priors -- the quadratic graph Laplacian regularizer (GLR) and the $ell_1$-norm graph total variation (GTV) -- subject to an interpolation constraint. The crucial insight is that a normalized signal-dependent graph learning module amounts to a variant of the basic self-attention mechanism in conventional transformers. Unlike black-box transformers that require learning of large key, query and value matrices to compute scaled dot products as affinities and subsequent output embeddings, resulting in huge parameter sets, our unrolled networks employ shallow CNNs to learn low-dimensional features per node to establish pairwise Mahalanobis distances and construct sparse similarity graphs. At each layer, given a learned graph, the target interpolated signal is simply a low-pass filtered output derived from the minimization of an assumed graph smoothness prior, leading to a dramatic reduction in parameter count. Experiments for two image interpolation applications verify the restoration performance, parameter efficiency and robustness to covariate shift of our graph-based unrolled networks compared to conventional transformers.
Read more6/7/2024

0
Unrolling Plug-and-Play Gradient Graph Laplacian Regularizer for Image Restoration
Jianghe Cai, Gene Cheung, Fei Chen
Generic deep learning (DL) networks for image restoration like denoising and interpolation lack mathematical interpretability, require voluminous training data to tune a large parameter set, and are fragile in the face of covariate shift. To address these shortcomings, we build interpretable networks by unrolling variants of a graph-based optimization algorithm of different complexities. Specifically, for a general linear image formation model, we first formulate a convex quadratic programming (QP) problem with a new $ell_2$-norm graph smoothness prior called gradient graph Laplacian regularizer (GGLR) that promotes piecewise planar (PWP) signal reconstruction. To solve the posed unconstrained QP problem, instead of computing a linear system solution straightforwardly, we introduce a variable number of auxiliary variables and correspondingly design a family of ADMM algorithms. We then unroll them into variable-complexity feed-forward networks, amenable to parameter tuning via back-propagation. More complex unrolled networks require more labeled data to train more parameters, but have better overall performance. The unrolled networks contain periodic insertions of a graph learning module, akin to a self-attention mechanism in a transformer architecture, to learn pairwise similarity structure inherent in data. Experimental results show that our unrolled networks perform competitively to generic DL networks in image restoration quality while using only a tiny fraction of parameters, and demonstrate improved robustness to covariate shift.
Read more7/26/2024

0
Constructing an Interpretable Deep Denoiser by Unrolling Graph Laplacian Regularizer
Seyed Alireza Hosseini, Tam Thuc Do, Gene Cheung, Yuichi Tanaka
An image denoiser can be used for a wide range of restoration problems via the Plug-and-Play (PnP) architecture. In this paper, we propose a general framework to build an interpretable graph-based deep denoiser (GDD) by unrolling a solution to a maximum a posteriori (MAP) problem equipped with a graph Laplacian regularizer (GLR) as signal prior. Leveraging a recent theorem showing that any (pseudo-)linear denoiser $boldsymbol Psi$, under mild conditions, can be mapped to a solution of a MAP denoising problem regularized using GLR, we first initialize a graph Laplacian matrix $mathbf L$ via truncated Taylor Series Expansion (TSE) of $boldsymbol Psi^{-1}$. Then, we compute the MAP linear system solution by unrolling iterations of the conjugate gradient (CG) algorithm into a sequence of neural layers as a feed-forward network -- one that is amenable to parameter tuning. The resulting GDD network is graph-interpretable, low in parameter count, and easy to initialize thanks to $mathbf L$ derived from a known well-performing denoiser $boldsymbol Psi$. Experimental results show that GDD achieves competitive image denoising performance compared to competitors, but employing far fewer parameters, and is more robust to covariate shift.
Read more9/11/2024

0
Joint Data Inpainting and Graph Learning via Unrolled Neural Networks
Subbareddy Batreddy, Pushkal Mishra, Yaswanth Kakarla, Aditya Siripuram
Given partial measurements of a time-varying graph signal, we propose an algorithm to simultaneously estimate both the underlying graph topology and the missing measurements. The proposed algorithm operates by training an interpretable neural network, designed from the unrolling framework. The proposed technique can be used both as a graph learning and a graph signal reconstruction algorithm. This work enhances prior work in graph signal reconstruction by allowing the underlying graph to be unknown; and also builds on prior work in graph learning by tailoring the learned graph to the signal reconstruction task.
Read more7/17/2024