Co(ve)rtex: ML Models as storage channels and their (mis-)applications

0
🚀
Sign in to get full access
Overview
- Machine learning (ML) models are often overparameterized to support generality and avoid overfitting.
- The state of these excess parameters is essentially irrelevant to the primary model, as long as it doesn't interfere with the model's performance.
- However, these "don't-care" states can introduce vulnerabilities in both hardware and software systems.
- This paper proposes a new information-theoretic perspective, treating the ML model as a storage channel that can be exploited by attackers.
Plain English Explanation
Machine learning models are designed to be very flexible, with far more parameters (internal settings) than are strictly necessary to solve the primary task they're trained for. This extra flexibility helps the models generalize well and avoid overfitting to the training data. However, these excess parameters essentially represent "don't-care" states, where their exact values don't matter for the model's performance.
Unfortunately, this property has been shown to introduce potential vulnerabilities in both hardware and software systems. The authors of this paper propose a new way of thinking about the problem, treating the ML model as a communication channel that can be used to secretly store and transmit information.
Specifically, the paper explores how an attacker could embed arbitrary data into the model during the training process, which could then be extracted by someone with access to the deployed model. The key insight is that the excess parameters in the model can be used to encode this hidden information, without significantly impacting the model's primary function.
The paper also considers a more constrained version of the problem, where the attacker needs to hide the fact that they're storing information in the model. This introduces additional challenges, as the data augmentation used to embed the hidden information must be carefully designed to minimize the distribution shift from the original training data. The authors propose novel techniques, like an ML-specific error correction protocol, to improve the capacity of this "covert" storage channel.
Technical Explanation
The core idea of the paper is to view the ML model as a storage channel that can be exploited by attackers. The authors derive an upper bound on the capacity of this channel based on the number of available unused parameters in the model.
They then explore two main primitives that attackers can use to interact with this channel:
- Write: The attacker can store data in the model by carefully augmenting the training data in an optimized way.
- Read: The attacker can extract the stored data by querying the deployed model in a black-box fashion.
The authors also consider a more advanced version of the problem, where the attacker needs to store the information covertly, without significantly impacting the model's primary function. To achieve this, they introduce a constraint that the data augmentation used for the write primitive must minimize the distribution shift from the original training data.
This covertness constraint introduces additional challenges, as it limits the effective capacity of the storage channel. To address this, the authors develop optimizations like a novel ML-specific error correction protocol to improve the capacity of the covert storage channel.
Critical Analysis
The paper presents a novel and thought-provoking perspective on potential vulnerabilities in overparameterized ML models. By framing the problem in information-theoretic terms, the authors open up new avenues for understanding and mitigating these issues.
However, the paper does acknowledge some limitations. For example, the proposed techniques may not be practical for extremely large models, as the computational overhead could become prohibitive. Additionally, the covert storage channel approach relies on specific assumptions about the attacker's knowledge and capabilities, which may not always hold in real-world scenarios.
It's also worth considering the broader implications of this research. While the focus is on potential vulnerabilities, the techniques could potentially be adapted for [beneficial applications, such as restricted Bayesian neural networks or other forms of model steganography](https://aimodels.fyi/papers/arxiv/physics-language-models-part-33-knowledge-capacity). The paper opens up an interesting area for further exploration and discussion within the ML community.
Conclusion
This paper presents a novel information-theoretic perspective on the potential vulnerabilities of overparameterized machine learning models. By treating the model as a storage channel, the authors develop techniques that allow attackers to embed and extract arbitrary data within the model, even in a covert manner.
While the paper highlights significant security concerns, it also opens up new avenues for research and potential beneficial applications of these techniques. By better understanding the storage capacity and information-theoretic properties of ML models, the community can work towards developing more robust and secure systems that harness the power of these powerful and flexible models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🚀
0
Co(ve)rtex: ML Models as storage channels and their (mis-)applications
Md Abdullah Al Mamun, Quazi Mishkatul Alam, Erfan Shayegani, Pedram Zaree, Ihsen Alouani, Nael Abu-Ghazaleh
Machine learning (ML) models are overparameterized to support generality and avoid overfitting. The state of these parameters is essentially a don't-care with respect to the primary model provided that this state does not interfere with the primary model. In both hardware and software systems, don't-care states and undefined behavior have been shown to be sources of significant vulnerabilities. In this paper, we propose a new information theoretic perspective of the problem; we consider the ML model as a storage channel with a capacity that increases with overparameterization. Specifically, we consider a sender that embeds arbitrary information in the model at training time, which can be extracted by a receiver with a black-box access to the deployed model. We derive an upper bound on the capacity of the channel based on the number of available unused parameters. We then explore black-box write and read primitives that allow the attacker to:(i) store data in an optimized way within the model by augmenting the training data at the transmitter side, and (ii) to read it by querying the model after it is deployed. We also consider a new version of the problem which takes information storage covertness into account. Specifically, to obtain storage covertness, we introduce a new constraint such that the data augmentation used for the write primitives minimizes the distribution shift with the initial (baseline task) distribution. This constraint introduces a level of interference with the initial task, thereby limiting the channel's effective capacity. Therefore, we develop optimizations to improve the capacity in this case, including a novel ML-specific substitution based error correction protocol. We believe that the proposed modeling of the problem offers new tools to better understand and mitigate potential vulnerabilities of ML, especially in the context of increasingly large models.
Read more5/14/2024
🤔
0
Privacy Side Channels in Machine Learning Systems
Edoardo Debenedetti, Giorgio Severi, Nicholas Carlini, Christopher A. Choquette-Choo, Matthew Jagielski, Milad Nasr, Eric Wallace, Florian Tram`er
Most current approaches for protecting privacy in machine learning (ML) assume that models exist in a vacuum. Yet, in reality, these models are part of larger systems that include components for training data filtering, output monitoring, and more. In this work, we introduce privacy side channels: attacks that exploit these system-level components to extract private information at far higher rates than is otherwise possible for standalone models. We propose four categories of side channels that span the entire ML lifecycle (training data filtering, input preprocessing, output post-processing, and query filtering) and allow for enhanced membership inference, data extraction, and even novel threats such as extraction of users' test queries. For example, we show that deduplicating training data before applying differentially-private training creates a side-channel that completely invalidates any provable privacy guarantees. We further show that systems which block language models from regenerating training data can be exploited to exfiltrate private keys contained in the training set--even if the model did not memorize these keys. Taken together, our results demonstrate the need for a holistic, end-to-end privacy analysis of machine learning systems.
Read more7/19/2024

0
Theoretical Insights into Overparameterized Models in Multi-Task and Replay-Based Continual Learning
Mohammadamin Banayeeanzade, Mahdi Soltanolkotabi, Mohammad Rostami
Multi-task learning (MTL) is a machine learning paradigm that aims to improve the generalization performance of a model on multiple related tasks by training it simultaneously on those tasks. Unlike MTL, where the model has instant access to the training data of all tasks, continual learning (CL) involves adapting to new sequentially arriving tasks over time without forgetting the previously acquired knowledge. Despite the wide practical adoption of CL and MTL and extensive literature on both areas, there remains a gap in the theoretical understanding of these methods when used with overparameterized models such as deep neural networks. This paper studies the overparameterized linear models as a proxy for more complex models. We develop theoretical results describing the effect of various system parameters on the model's performance in an MTL setup. Specifically, we study the impact of model size, dataset size, and task similarity on the generalization error and knowledge transfer. Additionally, we present theoretical results to characterize the performance of replay-based CL models. Our results reveal the impact of buffer size and model capacity on the forgetting rate in a CL setup and help shed light on some of the state-of-the-art CL methods. Finally, through extensive empirical evaluations, we demonstrate that our theoretical findings are also applicable to deep neural networks, offering valuable guidance for designing MTL and CL models in practice.
Read more9/2/2024
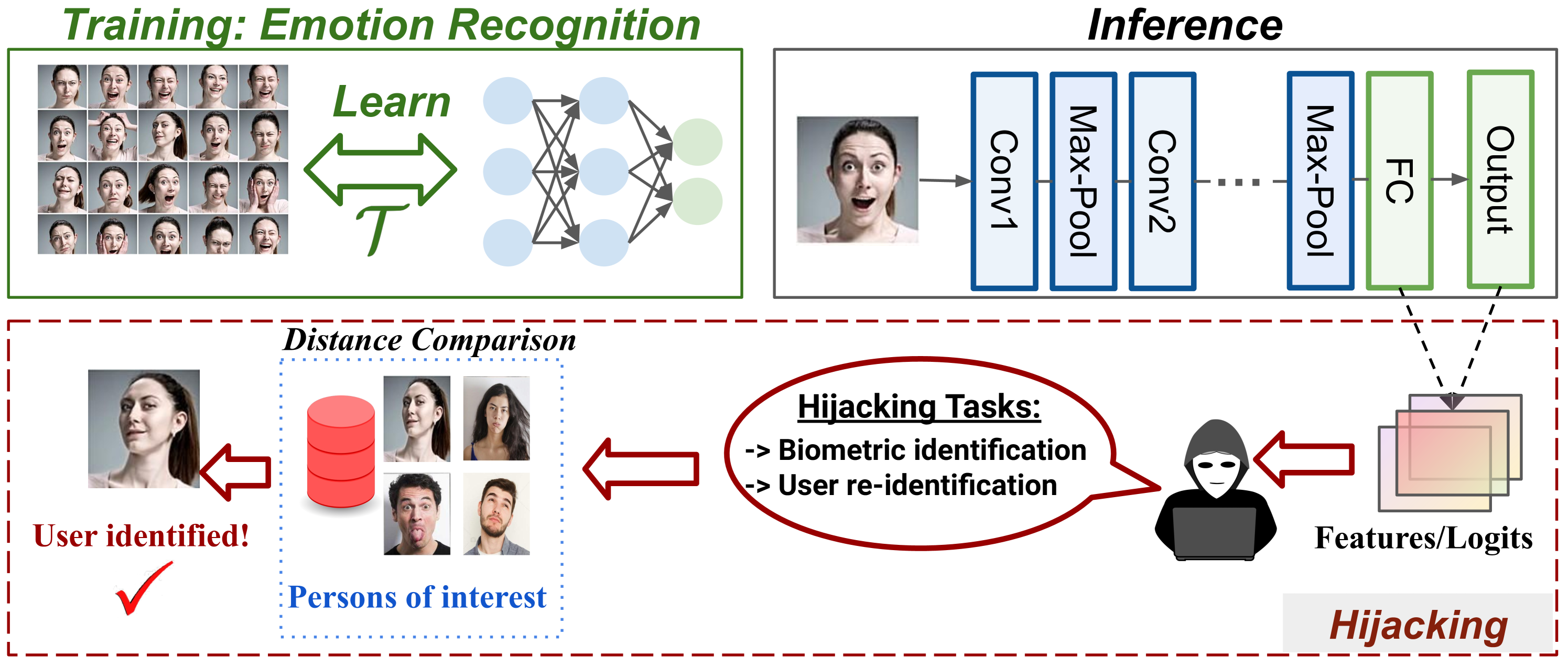
0
Model for Peanuts: Hijacking ML Models without Training Access is Possible
Mahmoud Ghorbel, Halima Bouzidi, Ioan Marius Bilasco, Ihsen Alouani
The massive deployment of Machine Learning (ML) models has been accompanied by the emergence of several attacks that threaten their trustworthiness and raise ethical and societal concerns such as invasion of privacy, discrimination risks, and lack of accountability. Model hijacking is one of these attacks, where the adversary aims to hijack a victim model to execute a different task than its original one. Model hijacking can cause accountability and security risks since a hijacked model owner can be framed for having their model offering illegal or unethical services. Prior state-of-the-art works consider model hijacking as a training time attack, whereby an adversary requires access to the ML model training to execute their attack. In this paper, we consider a stronger threat model where the attacker has no access to the training phase of the victim model. Our intuition is that ML models, typically over-parameterized, might (unintentionally) learn more than the intended task for they are trained. We propose a simple approach for model hijacking at inference time named SnatchML to classify unknown input samples using distance measures in the latent space of the victim model to previously known samples associated with the hijacking task classes. SnatchML empirically shows that benign pre-trained models can execute tasks that are semantically related to the initial task. Surprisingly, this can be true even for hijacking tasks unrelated to the original task. We also explore different methods to mitigate this risk. We first propose a novel approach we call meta-unlearning, designed to help the model unlearn a potentially malicious task while training on the original task dataset. We also provide insights on over-parameterization as one possible inherent factor that makes model hijacking easier, and we accordingly propose a compression-based countermeasure against this attack.
Read more6/5/2024