Theoretical Insights into Overparameterized Models in Multi-Task and Replay-Based Continual Learning

0

Sign in to get full access
Overview
- This paper provides theoretical insights into overparameterized models in multi-task and replay-based continual learning.
- It examines the behavior of overparameterized models and how they can be leveraged in these learning settings.
- The paper offers mathematical analysis and empirical results to support the key findings.
Plain English Explanation
The paper explores how highly complex, or "overparameterized," machine learning models can be used effectively in multi-task learning and continual learning scenarios.
In <a href="https://aimodels.fyi/papers/arxiv/unleashing-power-multi-task-learning-comprehensive-survey">multi-task learning</a>, a single model is trained to perform multiple different tasks simultaneously. And in <a href="https://aimodels.fyi/papers/arxiv/continual-learning-pre-trained-models-survey">continual learning</a>, a model learns new tasks sequentially without forgetting previous ones.
The researchers found that overparameterized models, which have many more parameters than needed to solve the tasks, can excel in these settings. The excess capacity allows the model to capture distinct features for each task without interfering with each other.
Additionally, the paper shows how <a href="https://aimodels.fyi/papers/arxiv/adaptive-memory-replay-continual-learning">replay-based continual learning</a> techniques, which store and reuse previous examples, can further boost the performance of overparameterized models. The models are able to effectively consolidate and leverage the stored knowledge.
Overall, the findings suggest that highly complex models can be powerful tools for tackling the challenges of multi-task and continual learning, when leveraged properly.
Technical Explanation
The paper presents a theoretical and empirical analysis of overparameterized models in multi-task and replay-based continual learning.
For multi-task learning, the researchers show that overparameterized models can learn distinct task-specific features without interference. The excess capacity allows the model to isolate the different task representations, improving overall performance.
In the continual learning setting, the paper demonstrates how <a href="https://aimodels.fyi/papers/arxiv/adaptive-memory-replay-continual-learning">replay-based methods</a>, which store and replay previous examples, can further enhance the capabilities of overparameterized models. The stored knowledge can be effectively consolidated and transferred to new tasks.
The theoretical analysis provides mathematical insights into the dynamics of overparameterized models in these learning scenarios. The empirical results on benchmark datasets validate the theoretical findings, showing significant performance gains compared to more constrained models.
Critical Analysis
The paper provides valuable theoretical and empirical contributions to the understanding of overparameterized models in multi-task and continual learning. However, some potential caveats and limitations are worth noting:
- The analysis is focused on linear and shallow neural network models, and it's unclear how the insights would translate to modern deep learning architectures.
- The theoretical proofs rely on several simplifying assumptions, such as Gaussian distributions and perfect task separability, which may not hold in more realistic settings.
- The empirical evaluations are conducted on relatively simple benchmark tasks, and the performance on more complex, real-world problems remains to be explored.
Further research is needed to investigate the applicability of these findings to a broader range of model types and problem domains. Exploring the interplay between model capacity, task complexity, and continual learning strategies would also be a fruitful area for future work.
Conclusion
This paper offers important theoretical insights into the benefits of using overparameterized models in multi-task and continual learning. The researchers demonstrate how the excess capacity of such models can be leveraged to capture distinct task-specific features and effectively consolidate knowledge through replay-based techniques.
The findings suggest that complex, highly expressive models can be powerful tools for tackling the challenges of learning in dynamic, multi-faceted environments. As machine learning continues to be applied to increasingly complex real-world problems, these insights could inform the development of more robust and adaptable learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Theoretical Insights into Overparameterized Models in Multi-Task and Replay-Based Continual Learning
Mohammadamin Banayeeanzade, Mahdi Soltanolkotabi, Mohammad Rostami
Multi-task learning (MTL) is a machine learning paradigm that aims to improve the generalization performance of a model on multiple related tasks by training it simultaneously on those tasks. Unlike MTL, where the model has instant access to the training data of all tasks, continual learning (CL) involves adapting to new sequentially arriving tasks over time without forgetting the previously acquired knowledge. Despite the wide practical adoption of CL and MTL and extensive literature on both areas, there remains a gap in the theoretical understanding of these methods when used with overparameterized models such as deep neural networks. This paper studies the overparameterized linear models as a proxy for more complex models. We develop theoretical results describing the effect of various system parameters on the model's performance in an MTL setup. Specifically, we study the impact of model size, dataset size, and task similarity on the generalization error and knowledge transfer. Additionally, we present theoretical results to characterize the performance of replay-based CL models. Our results reveal the impact of buffer size and model capacity on the forgetting rate in a CL setup and help shed light on some of the state-of-the-art CL methods. Finally, through extensive empirical evaluations, we demonstrate that our theoretical findings are also applicable to deep neural networks, offering valuable guidance for designing MTL and CL models in practice.
Read more9/2/2024

0
Theory on Mixture-of-Experts in Continual Learning
Hongbo Li, Sen Lin, Lingjie Duan, Yingbin Liang, Ness B. Shroff
Continual learning (CL) has garnered significant attention because of its ability to adapt to new tasks that arrive over time. Catastrophic forgetting (of old tasks) has been identified as a major issue in CL, as the model adapts to new tasks. The Mixture-of-Experts (MoE) model has recently been shown to effectively mitigate catastrophic forgetting in CL, by employing a gating network to sparsify and distribute diverse tasks among multiple experts. However, there is a lack of theoretical analysis of MoE and its impact on the learning performance in CL. This paper provides the first theoretical results to characterize the impact of MoE in CL via the lens of overparameterized linear regression tasks. We establish the benefit of MoE over a single expert by proving that the MoE model can diversify its experts to specialize in different tasks, while its router learns to select the right expert for each task and balance the loads across all experts. Our study further suggests an intriguing fact that the MoE in CL needs to terminate the update of the gating network after sufficient training rounds to attain system convergence, which is not needed in the existing MoE studies that do not consider the continual task arrival. Furthermore, we provide explicit expressions for the expected forgetting and overall generalization error to characterize the benefit of MoE in the learning performance in CL. Interestingly, adding more experts requires additional rounds before convergence, which may not enhance the learning performance. Finally, we conduct experiments on both synthetic and real datasets to extend these insights from linear models to deep neural networks (DNNs), which also shed light on the practical algorithm design for MoE in CL.
Read more6/26/2024
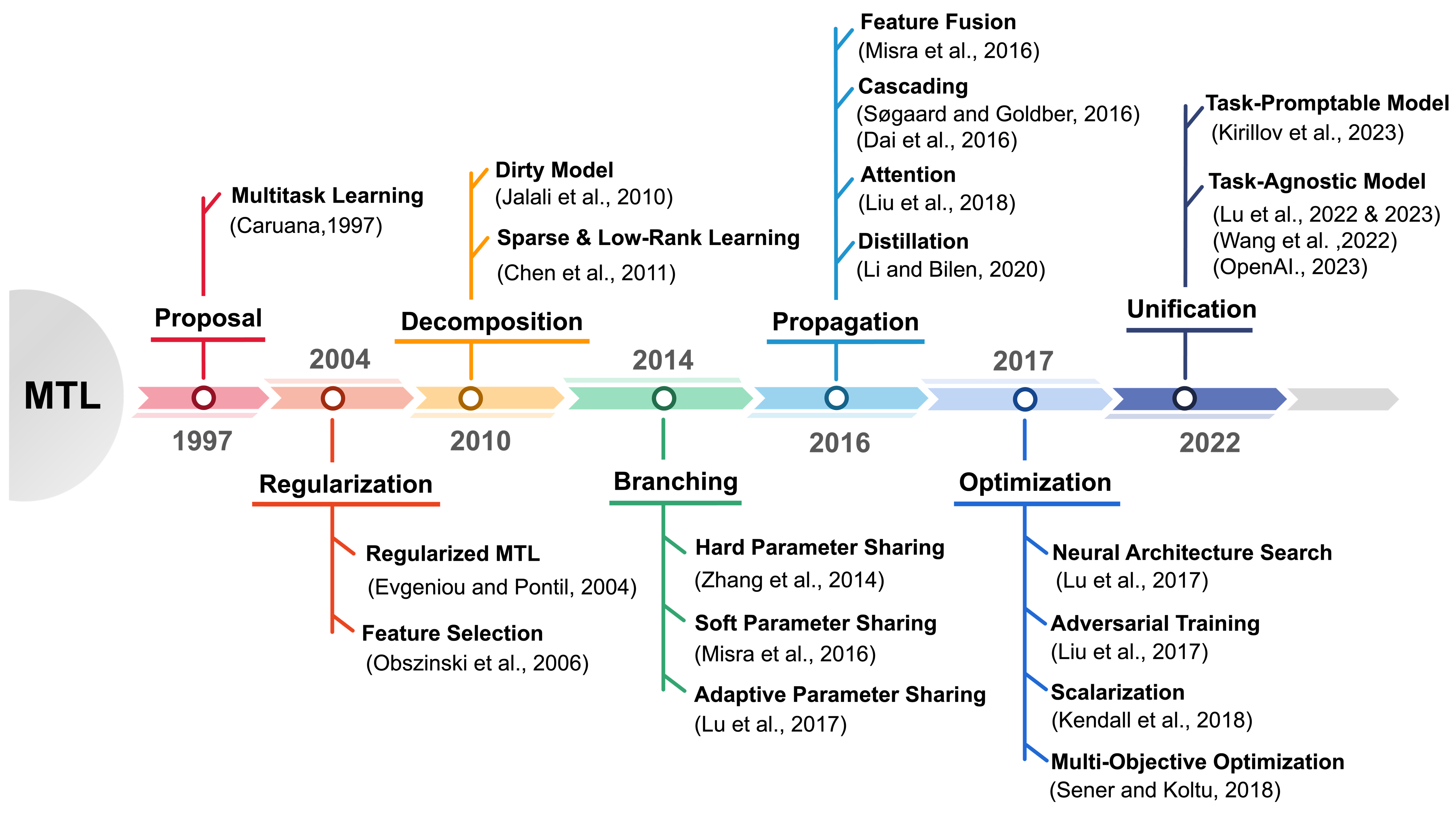
0
Unleashing the Power of Multi-Task Learning: A Comprehensive Survey Spanning Traditional, Deep, and Pretrained Foundation Model Eras
Jun Yu, Yutong Dai, Xiaokang Liu, Jin Huang, Yishan Shen, Ke Zhang, Rong Zhou, Eashan Adhikarla, Wenxuan Ye, Yixin Liu, Zhaoming Kong, Kai Zhang, Yilong Yin, Vinod Namboodiri, Brian D. Davison, Jason H. Moore, Yong Chen
MTL is a learning paradigm that effectively leverages both task-specific and shared information to address multiple related tasks simultaneously. In contrast to STL, MTL offers a suite of benefits that enhance both the training process and the inference efficiency. MTL's key advantages encompass streamlined model architecture, performance enhancement, and cross-domain generalizability. Over the past twenty years, MTL has become widely recognized as a flexible and effective approach in various fields, including CV, NLP, recommendation systems, disease prognosis and diagnosis, and robotics. This survey provides a comprehensive overview of the evolution of MTL, encompassing the technical aspects of cutting-edge methods from traditional approaches to deep learning and the latest trend of pretrained foundation models. Our survey methodically categorizes MTL techniques into five key areas: regularization, relationship learning, feature propagation, optimization, and pre-training. This categorization not only chronologically outlines the development of MTL but also dives into various specialized strategies within each category. Furthermore, the survey reveals how the MTL evolves from handling a fixed set of tasks to embracing a more flexible approach free from task or modality constraints. It explores the concepts of task-promptable and -agnostic training, along with the capacity for ZSL, which unleashes the untapped potential of this historically coveted learning paradigm. Overall, we hope this survey provides the research community with a comprehensive overview of the advancements in MTL from its inception in 1997 to the present in 2023. We address present challenges and look ahead to future possibilities, shedding light on the opportunities and potential avenues for MTL research in a broad manner. This project is publicly available at https://github.com/junfish/Awesome-Multitask-Learning.
Read more5/1/2024
🧠
0
Continual Learning with Pre-Trained Models: A Survey
Da-Wei Zhou, Hai-Long Sun, Jingyi Ning, Han-Jia Ye, De-Chuan Zhan
Nowadays, real-world applications often face streaming data, which requires the learning system to absorb new knowledge as data evolves. Continual Learning (CL) aims to achieve this goal and meanwhile overcome the catastrophic forgetting of former knowledge when learning new ones. Typical CL methods build the model from scratch to grow with incoming data. However, the advent of the pre-trained model (PTM) era has sparked immense research interest, particularly in leveraging PTMs' robust representational capabilities. This paper presents a comprehensive survey of the latest advancements in PTM-based CL. We categorize existing methodologies into three distinct groups, providing a comparative analysis of their similarities, differences, and respective advantages and disadvantages. Additionally, we offer an empirical study contrasting various state-of-the-art methods to highlight concerns regarding fairness in comparisons. The source code to reproduce these evaluations is available at: https://github.com/sun-hailong/LAMDA-PILOT
Read more4/24/2024