Physics of Language Models: Part 3.3, Knowledge Capacity Scaling Laws
2404.05405
4
0
💬
Abstract
Scaling laws describe the relationship between the size of language models and their capabilities. Unlike prior studies that evaluate a model's capability via loss or benchmarks, we estimate the number of knowledge bits a model stores. We focus on factual knowledge represented as tuples, such as (USA, capital, Washington D.C.) from a Wikipedia page. Through multiple controlled datasets, we establish that language models can and only can store 2 bits of knowledge per parameter, even when quantized to int8, and such knowledge can be flexibly extracted for downstream applications. Consequently, a 7B model can store 14B bits of knowledge, surpassing the English Wikipedia and textbooks combined based on our estimation. More broadly, we present 12 results on how (1) training duration, (2) model architecture, (3) quantization, (4) sparsity constraints such as MoE, and (5) data signal-to-noise ratio affect a model's knowledge storage capacity. Notable insights include:
- The GPT-2 architecture, with rotary embedding, matches or even surpasses LLaMA/Mistral architectures in knowledge storage, particularly over shorter training durations. This arises because LLaMA/Mistral uses GatedMLP, which is less stable and harder to train.
- Prepending training data with domain names (e.g., wikipedia.org) significantly increases a model's knowledge capacity. Language models can autonomously identify and prioritize domains rich in knowledge, optimizing their storage capacity.
Create account to get full access
Overview
- This paper explores the relationship between the size of language models and their knowledge capacity, rather than just their performance on benchmarks.
- The researchers focus on measuring the amount of factual knowledge stored in language models, represented as tuples (e.g., "USA, capital, Washington D.C.").
- Through controlled experiments, they find that language models can store roughly 2 bits of knowledge per parameter, even when quantized to 8-bit precision.
- The study also investigates how factors like training duration, model architecture, quantization, sparsity, and data quality affect a model's knowledge storage capacity.
Plain English Explanation
The paper looks at how the size of large language models, like GPT-3, relates to the amount of factual knowledge they can store. Unlike previous studies that focus on a model's performance on benchmarks or its overall "loss," the researchers here are specifically interested in measuring the number of individual facts or "knowledge bits" a model can retain.
To do this, they use datasets that contain information in the form of simple statements or "tuples," like "the capital of the USA is Washington D.C." Through a series of experiments, they find that language models can generally store about 2 bits of knowledge per parameter in their underlying neural networks. This means a 7 billion parameter model could potentially hold around 14 billion individual facts - more than the entire English Wikipedia and standard textbooks combined.
The researchers also look at how different factors, like the model's architecture, the way it's trained, and the quality of the data it's exposed to, can impact its knowledge storage capacity. For example, they find that the GPT-2 architecture, with its "rotary embedding" technique, actually outperforms newer models like LLaMA/Mistral in terms of knowledge storage, particularly when training time is limited.
Overall, this work provides a novel way to understand and quantify the capabilities of large language models, moving beyond just looking at their performance on benchmark tasks. By focusing on the concrete "knowledge bits" they can store, the researchers hope to shed light on the nature of machine learning and how it aligns with human-like intelligence.
Technical Explanation
The paper presents a series of experiments designed to measure the factual knowledge capacity of large language models, rather than just evaluating their performance on standardized benchmarks. The researchers focus on the number of unique knowledge "bits" or facts that a model can store, represented as tuples (e.g., "USA, capital, Washington D.C.") extracted from Wikipedia.
Through carefully controlled datasets and experiments, the authors establish that language models have a consistent knowledge storage capacity of approximately 2 bits per parameter, even when the models are quantized to 8-bit precision. This means a 7 billion parameter model could potentially store around 14 billion individual facts - more than the combined knowledge contained in the English Wikipedia and standard textbooks.
The paper also explores how various factors impact a model's knowledge storage capacity:
-
Training Duration: The authors find that the GPT-2 architecture, with its "rotary embedding" technique, matches or even surpasses newer models like LLaMA/Mistral in knowledge storage, particularly over shorter training durations. This is because the LLaMA/Mistral models use a "GatedMLP" component that is less stable and harder to train effectively.
-
Model Architecture: The study compares the knowledge storage capacity of different model architectures, such as GPT-2 and LLaMA/Mistral, highlighting the trade-offs between stability, trainability, and knowledge retention.
-
Quantization: Even when the models are quantized to 8-bit precision (reducing their memory footprint), the researchers find that the knowledge storage capacity remains consistent at around 2 bits per parameter.
-
Sparsity Constraints: The paper examines the impact of techniques like Mixture-of-Experts (MoE), which introduce sparsity constraints, on a model's knowledge capacity.
-
Data Quality: The researchers demonstrate that prepending training data with domain names (e.g., "wikipedia.org") significantly increases a model's knowledge storage capacity, as the model can autonomously identify and prioritize knowledge-rich domains.
Overall, this work provides a novel and insightful perspective on the capabilities of large language models, moving beyond traditional benchmarks to directly quantify the factual knowledge they can retain.
Critical Analysis
The researchers present a thoughtful and well-designed study that offers a unique approach to understanding the inner workings of large language models. By focusing on the specific knowledge bits that these models can store, rather than just their performance on standardized tasks, the paper provides a valuable complement to existing research in this field.
One potential limitation of the study is the reliance on knowledge representation in the form of simple tuples, which may not fully capture the nuanced and contextual nature of human knowledge. Additionally, the researchers acknowledge that their estimation of the total knowledge capacity of language models, like surpassing the combined knowledge of Wikipedia and textbooks, is likely an upper bound and may not reflect the models' true understanding of the information.
Furthermore, the paper's findings on the superiority of the GPT-2 architecture over newer models like LLaMA/Mistral in terms of knowledge storage capacity could be influenced by the specific experimental setup and may not generalize to all use cases. It would be interesting to see further research exploring the trade-offs between different architectural choices and their impact on knowledge representation and retrieval.
Overall, this paper represents an important contribution to the ongoing efforts to unravel the mysteries of large language models and their relationship to human-like intelligence. By challenging the field to think beyond just performance metrics, the researchers encourage readers to consider the deeper implications of these models' capabilities and limitations.
Conclusion
This paper presents a novel approach to understanding the knowledge capacity of large language models, going beyond traditional performance-based evaluations. The researchers demonstrate that language models can consistently store approximately 2 bits of factual knowledge per parameter, even when quantized to 8-bit precision.
The study also provides valuable insights into how various factors, such as model architecture, training duration, and data quality, can impact a model's knowledge storage capacity. These findings have important implications for the development and deployment of large language models, as they suggest that the models' capabilities may extend far beyond their surface-level performance on benchmark tasks.
By shifting the focus towards the direct measurement of knowledge storage, this work contributes to a deeper understanding of the nature of machine learning and its relationship to human-like intelligence. As the field of natural language processing continues to evolve, research like this will be crucial in guiding the development of ever-more capable and reliable language models that can truly serve the needs of society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
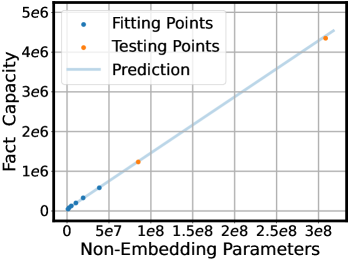
Scaling Laws for Fact Memorization of Large Language Models
Xingyu Lu, Xiaonan Li, Qinyuan Cheng, Kai Ding, Xuanjing Huang, Xipeng Qiu
0
0
Fact knowledge memorization is crucial for Large Language Models (LLM) to generate factual and reliable responses. However, the behaviors of LLM fact memorization remain under-explored. In this paper, we analyze the scaling laws for LLM's fact knowledge and LLMs' behaviors of memorizing different types of facts. We find that LLMs' fact knowledge capacity has a linear and negative exponential law relationship with model size and training epochs, respectively. Estimated by the built scaling law, memorizing the whole Wikidata's facts requires training an LLM with 1000B non-embed parameters for 100 epochs, suggesting that using LLMs to memorize all public facts is almost implausible for a general pre-training setting. Meanwhile, we find that LLMs can generalize on unseen fact knowledge and its scaling law is similar to general pre-training. Additionally, we analyze the compatibility and preference of LLMs' fact memorization. For compatibility, we find LLMs struggle with memorizing redundant facts in a unified way. Only when correlated facts have the same direction and structure, the LLM can compatibly memorize them. This shows the inefficiency of LLM memorization for redundant facts. For preference, the LLM pays more attention to memorizing more frequent and difficult facts, and the subsequent facts can overwrite prior facts' memorization, which significantly hinders low-frequency facts memorization. Our findings reveal the capacity and characteristics of LLMs' fact knowledge learning, which provide directions for LLMs' fact knowledge augmentation.
6/26/2024

Large Knowledge Model: Perspectives and Challenges
Huajun Chen
0
0
Humankind's understanding of the world is fundamentally linked to our perception and cognition, with emph{human languages} serving as one of the major carriers of emph{world knowledge}. In this vein, emph{Large Language Models} (LLMs) like ChatGPT epitomize the pre-training of extensive, sequence-based world knowledge into neural networks, facilitating the processing and manipulation of this knowledge in a parametric space. This article explores large models through the lens of knowledge. We initially investigate the role of symbolic knowledge such as Knowledge Graphs (KGs) in enhancing LLMs, covering aspects like knowledge-augmented language model, structure-inducing pre-training, knowledgeable prompts, structured CoT, knowledge editing, semantic tools for LLM and knowledgeable AI agents. Subsequently, we examine how LLMs can boost traditional symbolic knowledge bases, encompassing aspects like using LLM as KG builder and controller, structured knowledge pretraining, and LLM-enhanced symbolic reasoning. Considering the intricate nature of human knowledge, we advocate for the creation of emph{Large Knowledge Models} (LKM), specifically engineered to manage diversified spectrum of knowledge structures. This promising undertaking would entail several key challenges, such as disentangling knowledge base from language models, cognitive alignment with human knowledge, integration of perception and cognition, and building large commonsense models for interacting with physical world, among others. We finally propose a five-A principle to distinguish the concept of LKM.
6/27/2024
🤔
Quantifying the Capabilities of LLMs across Scale and Precision
Sher Badshah, Hassan Sajjad
0
0
Scale is often attributed as one of the factors that cause an increase in the performance of LLMs, resulting in models with billion and trillion parameters. One of the limitations of such large models is the high computational requirements that limit their usage, deployment, and debugging in resource-constrained scenarios. Two commonly used alternatives to bypass these limitations are to use the smaller versions of LLMs (e.g. Llama 7B instead of Llama 70B) and lower the memory requirements by using quantization. While these approaches effectively address the limitation of resources, their impact on model performance needs thorough examination. In this study, we perform a comprehensive evaluation to investigate the effect of model scale and quantization on the performance. We experiment with two major families of open-source instruct models ranging from 7 billion to 70 billion parameters. Our extensive zero-shot experiments across various tasks including natural language understanding, reasoning, misinformation detection, and hallucination reveal that larger models generally outperform their smaller counterparts, suggesting that scale remains an important factor in enhancing performance. We found that larger models show exceptional resilience to precision reduction and can maintain high accuracy even at 4-bit quantization for numerous tasks and they serve as a better solution than using smaller models at high precision under similar memory requirements.
5/9/2024
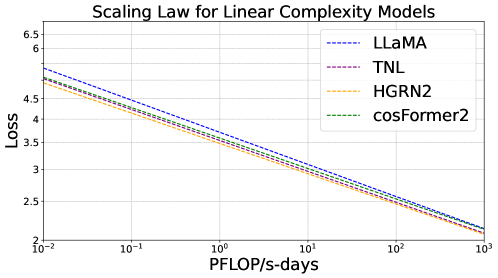
Scaling Laws for Linear Complexity Language Models
Xuyang Shen, Dong Li, Ruitao Leng, Zhen Qin, Weigao Sun, Yiran Zhong
0
0
The interest in linear complexity models for large language models is on the rise, although their scaling capacity remains uncertain. In this study, we present the scaling laws for linear complexity language models to establish a foundation for their scalability. Specifically, we examine the scaling behaviors of three efficient linear architectures. These include TNL, a linear attention model with data-independent decay; HGRN2, a linear RNN with data-dependent decay; and cosFormer2, a linear attention model without decay. We also include LLaMA as a baseline architecture for softmax attention for comparison. These models were trained with six variants, ranging from 70M to 7B parameters on a 300B-token corpus, and evaluated with a total of 1,376 intermediate checkpoints on various downstream tasks. These tasks include validation loss, commonsense reasoning, and information retrieval and generation. The study reveals that existing linear complexity language models exhibit similar scaling capabilities as conventional transformer-based models while also demonstrating superior linguistic proficiency and knowledge retention.
6/26/2024