CoVR: Learning Composed Video Retrieval from Web Video Captions

0
💬
Sign in to get full access
Overview
- This paper introduces a new task called Composed Image Retrieval (CoIR) and a related task called Composed Video Retrieval (CoVR).
- Most existing CoIR approaches require manually annotated datasets, which are expensive to create and limit scalability.
- The authors propose a scalable automatic dataset creation methodology to generate CoIR and CoVR triplets (query image/video, modification text, target image/video) using video-caption pairs.
- The authors create a new large-scale dataset called WebVid-CoVR using this methodology and introduce a new benchmark for the CoVR task.
- The authors demonstrate that a model trained on the WebVid-CoVR dataset can effectively transfer to and improve state-of-the-art performance on the CoIR task in a zero-shot setup.
Plain English Explanation
The paper focuses on a task called Composed Image Retrieval (CoIR), where the goal is to find an image in a database that is relevant to both a text query and an image query. For example, if the text query is "a person with a hat" and the image query is a person without a hat, the target image should be the same person wearing a hat.
Most existing approaches to CoIR require manually curated datasets, where each example consists of an image, a text description of how to modify the image, and the resulting target image. However, manually creating these datasets is time-consuming and expensive, which limits their scalability.
To address this, the authors propose a method to automatically generate these datasets using video-caption pairs. They find pairs of videos with similar captions, and then use a large language model to generate the text describing how to modify one video to get the other. This allows them to create a large dataset of CoIR triplets (query image, modification text, target image) called WebVid-CoVR.
The authors also introduce a new benchmark for a related task called Composed Video Retrieval (CoVR), where the goal is to find a video in a database that is relevant to both a text query and a video query. They manually annotate a CoVR evaluation set and provide baseline results.
Finally, the authors show that a model trained on the WebVid-CoVR dataset can effectively transfer to the CoIR task, leading to improved state-of-the-art performance on existing CoIR benchmarks like CIRR and FashionIQ in a zero-shot setup.
Technical Explanation
The key contributions of this paper are:
-
Automatic Dataset Creation: The authors propose a scalable methodology to automatically generate CoIR and CoVR triplets using video-caption pairs from the WebVid2M dataset. They mine paired videos with similar captions, and use a large language model to generate the corresponding modification text.
-
WebVid-CoVR Dataset: Applying this methodology to WebVid2M, the authors create a new large-scale dataset called WebVid-CoVR, containing 1.6 million CoVR triplets.
-
CoVR Benchmark: The authors introduce a new benchmark for the CoVR task, including a manually annotated evaluation set and baseline results.
-
Zero-Shot CoIR Transfer: The authors demonstrate that a model trained on the WebVid-CoVR dataset can effectively transfer to the CoIR task, leading to improved state-of-the-art performance on the CIRR and FashionIQ benchmarks in a zero-shot setup.
The automatic dataset creation methodology leverages video-caption pairs to generate CoIR and CoVR triplets. First, they mine pairs of videos with similar captions from the WebVid2M dataset. Then, they use a large language model to generate the text describing how to modify one video to get the other, creating the modification text component of the triplet.
For the CoVR benchmark, the authors manually annotate a evaluation set to measure the performance of models on this task. They provide baseline results using a multimodal retrieval model trained on the WebVid-CoVR dataset.
The authors further demonstrate that the knowledge gained from training on the WebVid-CoVR dataset can be effectively transferred to the CoIR task, leading to state-of-the-art performance on the CIRR and FashionIQ benchmarks in a zero-shot setup.
Critical Analysis
The authors present a novel approach to generating large-scale datasets for the Composed Image Retrieval (CoIR) and Composed Video Retrieval (CoVR) tasks, which is a significant contribution to the field. The automatic dataset creation methodology is scalable and allows for the generation of a much larger dataset (WebVid-CoVR) compared to previous manually curated datasets.
However, the authors acknowledge some potential limitations of their approach. For example, the modification texts generated by the language model may not always accurately describe the differences between the paired videos, which could introduce noise into the dataset. Additionally, the WebVid2M dataset used as the source for the video-caption pairs may not be representative of all types of composed image or video retrieval tasks.
The authors also do not provide a detailed analysis of the types of modifications or the diversity of the generated triplets in the WebVid-CoVR dataset. It would be valuable to understand the characteristics of the dataset and how it compares to manually curated datasets in terms of the complexity and variety of the modifications.
Furthermore, while the authors demonstrate impressive zero-shot transfer performance to the CoIR task, it would be interesting to see how the WebVid-CoVR dataset and trained models perform on a broader range of composed retrieval tasks and benchmarks. Expanding the evaluation to include more diverse datasets and scenarios could provide a more comprehensive understanding of the strengths and limitations of the proposed approach.
Overall, the paper presents an innovative solution to the challenge of dataset creation for composed retrieval tasks, and the authors' work is a valuable contribution to the field. However, further investigation into the quality and characteristics of the generated dataset, as well as more extensive evaluation, could strengthen the impact of the research.
Conclusion
This paper introduces a novel approach to automatically generating large-scale datasets for Composed Image Retrieval (CoIR) and Composed Video Retrieval (CoVR) tasks. The authors' scalable methodology leverages video-caption pairs to create a new dataset called WebVid-CoVR, containing 1.6 million triplets.
The authors also introduce a new benchmark for the CoVR task and demonstrate that a model trained on the WebVid-CoVR dataset can effectively transfer to the CoIR task, leading to improved state-of-the-art performance on existing benchmarks in a zero-shot setup.
This research represents a significant advancement in the field of composed retrieval, as it addresses the key challenge of dataset creation and paves the way for more scalable and diverse applications of these techniques. The authors' work has the potential to catalyze further progress in this area and inspire new directions for research in multimodal learning and retrieval.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
CoVR: Learning Composed Video Retrieval from Web Video Captions
Lucas Ventura, Antoine Yang, Cordelia Schmid, Gul Varol
Composed Image Retrieval (CoIR) has recently gained popularity as a task that considers both text and image queries together, to search for relevant images in a database. Most CoIR approaches require manually annotated datasets, comprising image-text-image triplets, where the text describes a modification from the query image to the target image. However, manual curation of CoIR triplets is expensive and prevents scalability. In this work, we instead propose a scalable automatic dataset creation methodology that generates triplets given video-caption pairs, while also expanding the scope of the task to include composed video retrieval (CoVR). To this end, we mine paired videos with a similar caption from a large database, and leverage a large language model to generate the corresponding modification text. Applying this methodology to the extensive WebVid2M collection, we automatically construct our WebVid-CoVR dataset, resulting in 1.6 million triplets. Moreover, we introduce a new benchmark for CoVR with a manually annotated evaluation set, along with baseline results. Our experiments further demonstrate that training a CoVR model on our dataset effectively transfers to CoIR, leading to improved state-of-the-art performance in the zero-shot setup on both the CIRR and FashionIQ benchmarks. Our code, datasets, and models are publicly available at https://imagine.enpc.fr/~ventural/covr.
Read more5/31/2024

0
Pseudo-triplet Guided Few-shot Composed Image Retrieval
Bohan Hou, Haoqiang Lin, Haokun Wen, Meng Liu, Xuemeng Song
Composed Image Retrieval (CIR) is a challenging task that aims to retrieve the target image based on a multimodal query, i.e., a reference image and its corresponding modification text. While previous supervised or zero-shot learning paradigms all fail to strike a good trade-off between time-consuming annotation cost and retrieval performance, recent researchers introduced the task of few-shot CIR (FS-CIR) and proposed a textual inversion-based network based on pretrained CLIP model to realize it. Despite its promising performance, the approach suffers from two key limitations: insufficient multimodal query composition training and indiscriminative training triplet selection. To address these two limitations, in this work, we propose a novel two-stage pseudo triplet guided few-shot CIR scheme, dubbed PTG-FSCIR. In the first stage, we employ a masked training strategy and advanced image caption generator to construct pseudo triplets from pure image data to enable the model to acquire primary knowledge related to multimodal query composition. In the second stage, based on active learning, we design a pseudo modification text-based query-target distance metric to evaluate the challenging score for each unlabeled sample. Meanwhile, we propose a robust top range-based random sampling strategy according to the 3-$sigma$ rule in statistics, to sample the challenging samples for fine-tuning the pretrained model. Notably, our scheme is plug-and-play and compatible with any existing supervised CIR models. We tested our scheme across three backbones on three public datasets (i.e., FashionIQ, CIRR, and Birds-to-Words), achieving maximum improvements of 26.4%, 25.5% and 21.6% respectively, demonstrating our scheme's effectiveness.
Read more7/9/2024

0
VCR: Visual Caption Restoration
Tianyu Zhang, Suyuchen Wang, Lu Li, Ge Zhang, Perouz Taslakian, Sai Rajeswar, Jie Fu, Bang Liu, Yoshua Bengio
We introduce Visual Caption Restoration (VCR), a novel vision-language task that challenges models to accurately restore partially obscured texts using pixel-level hints within images. This task stems from the observation that text embedded in images is intrinsically different from common visual elements and natural language due to the need to align the modalities of vision, text, and text embedded in images. While numerous works have integrated text embedded in images into visual question-answering tasks, approaches to these tasks generally rely on optical character recognition or masked language modeling, thus reducing the task to mainly text-based processing. However, text-based processing becomes ineffective in VCR as accurate text restoration depends on the combined information from provided images, context, and subtle cues from the tiny exposed areas of masked texts. We develop a pipeline to generate synthetic images for the VCR task using image-caption pairs, with adjustable caption visibility to control the task difficulty. With this pipeline, we construct a dataset for VCR called VCR-Wiki using images with captions from Wikipedia, comprising 2.11M English and 346K Chinese entities in both easy and hard split variants. Our results reveal that current vision language models significantly lag behind human performance in the VCR task, and merely fine-tuning the models on our dataset does not lead to notable improvements. We release VCR-Wiki and the data construction code to facilitate future research.
Read more6/26/2024
0
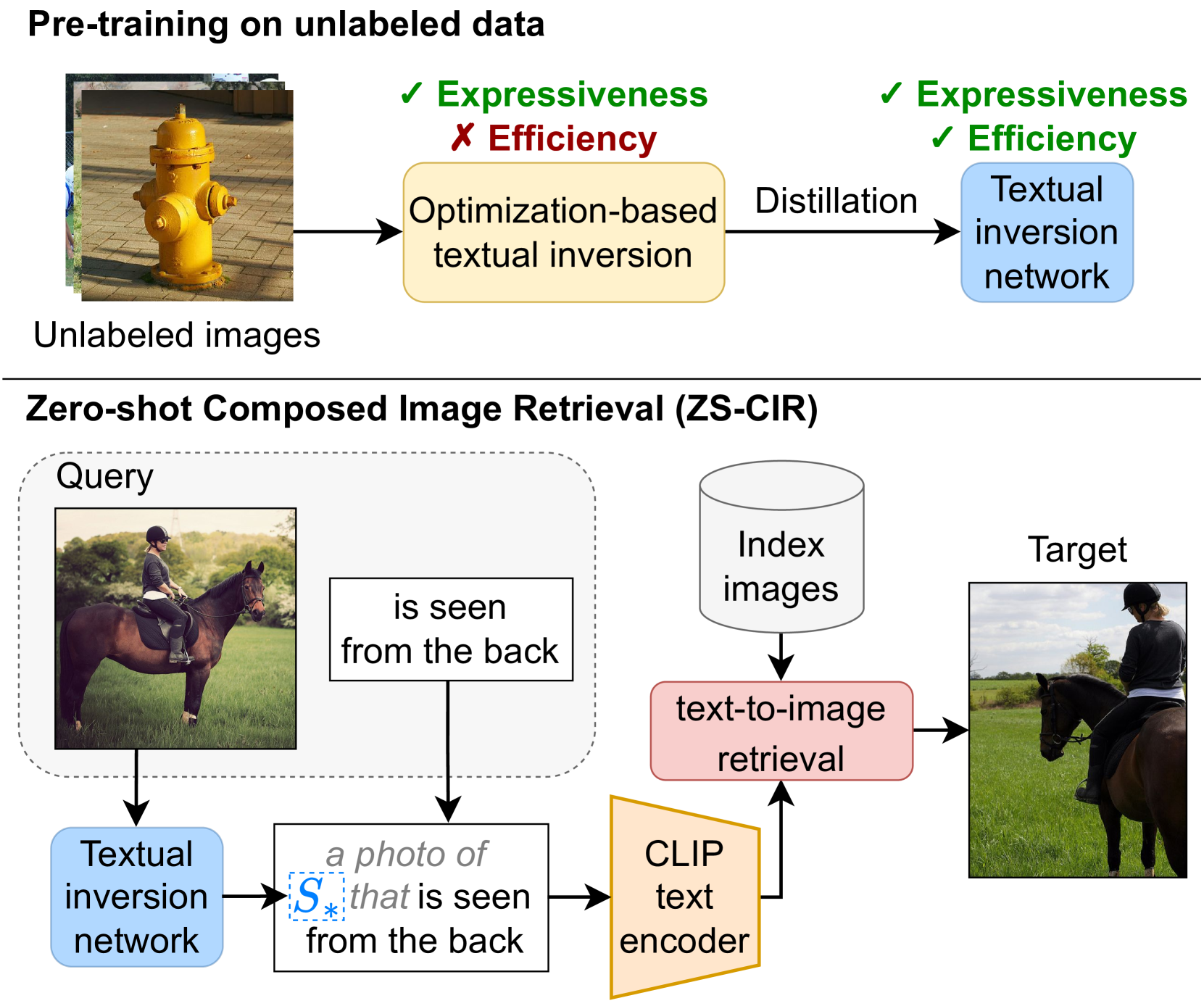
iSEARLE: Improving Textual Inversion for Zero-Shot Composed Image Retrieval
Lorenzo Agnolucci, Alberto Baldrati, Marco Bertini, Alberto Del Bimbo
Given a query consisting of a reference image and a relative caption, Composed Image Retrieval (CIR) aims to retrieve target images visually similar to the reference one while incorporating the changes specified in the relative caption. The reliance of supervised methods on labor-intensive manually labeled datasets hinders their broad applicability. In this work, we introduce a new task, Zero-Shot CIR (ZS-CIR), that addresses CIR without the need for a labeled training dataset. We propose an approach named iSEARLE (improved zero-Shot composEd imAge Retrieval with textuaL invErsion) that involves mapping the visual information of the reference image into a pseudo-word token in CLIP token embedding space and combining it with the relative caption. To foster research on ZS-CIR, we present an open-domain benchmarking dataset named CIRCO (Composed Image Retrieval on Common Objects in context), the first CIR dataset where each query is labeled with multiple ground truths and a semantic categorization. The experimental results illustrate that iSEARLE obtains state-of-the-art performance on three different CIR datasets -- FashionIQ, CIRR, and the proposed CIRCO -- and two additional evaluation settings, namely domain conversion and object composition. The dataset, the code, and the model are publicly available at https://github.com/miccunifi/SEARLE.
Read more5/7/2024