Crafting Large Language Models for Enhanced Interpretability

0

Sign in to get full access
Overview
- This paper discusses crafting large language models for enhanced interpretability.
- The key ideas are leveraging concept bottleneck models and iterative text generation to improve the transparency and explainability of language models.
- The proposed approach aims to make large language models more interpretable while maintaining their performance.
Plain English Explanation
The paper focuses on making large language models, which are powerful AI systems that can understand and generate human-like text, more interpretable and transparent. Large language models can often perform impressive feats, but it can be difficult to understand how they arrive at their outputs.
The researchers propose using concept bottleneck models and iterative text generation to enhance the interpretability of these models. Concept bottleneck models work by having the model first identify high-level concepts, and then use those concepts to generate the final output. This makes it easier to understand the reasoning behind the model's decisions.
The iterative text generation approach involves having the model generate text in a step-by-step fashion, rather than all at once. This allows the user to see the intermediate steps and understand how the model is constructing the output. By combining these techniques, the researchers aim to create large language models that are both powerful and transparent, allowing users to better understand how the models work.
Technical Explanation
The paper proposes a framework for crafting large language models with enhanced interpretability. The key components of this framework are:
-
Concept Bottleneck Models: These models first identify high-level concepts, and then use those concepts to generate the final output. This provides a more interpretable intermediate representation that can be inspected and understood.
-
Iterative Text Generation: The language model generates text in a step-by-step fashion, rather than all at once. This allows the user to observe the model's reasoning process and understand how it constructs the output.
By combining these two techniques, the researchers aim to create large language models that are both powerful and transparent. The concept bottleneck approach provides a way to understand the model's decision-making, while the iterative generation allows the user to see the intermediate steps.
The paper also discusses [other approaches](../../../papers/arxiv/incremental-residual-concept-bottleneck-models, ../../../papers/arxiv/concept-bottleneck-models-without-predefined-concepts, ../../../papers/arxiv/anycbms-how-to-turn-any-black-box) for enhancing the interpretability of language models, such as using dynamically generated concepts and converting any black-box model into a concept bottleneck model.
Critical Analysis
The paper presents a promising approach for making large language models more interpretable, which is an important goal as these models become more widely used. The combination of concept bottleneck models and iterative text generation seems well-designed to provide users with a better understanding of how the models work.
However, the paper does not address potential limitations or challenges of this approach. For example, it's unclear how the model's performance might be affected by the additional constraints and overhead of the interpretability mechanisms. There may also be practical challenges in implementing these techniques at scale.
Additionally, the paper does not discuss the potential broader implications or societal impacts of more interpretable language models. While enhanced transparency is generally positive, it's important to consider how these models might be used and the potential risks or unintended consequences.
Overall, the paper provides a valuable contribution to the field of interpretable AI, but further research and practical implementation will be needed to fully assess the feasibility and impact of this approach.
Conclusion
This paper presents a framework for crafting large language models with enhanced interpretability, leveraging concept bottleneck models and iterative text generation. By making the decision-making process more transparent, the proposed approach aims to create powerful language models that are also easy for users to understand and trust.
The combination of these techniques represents an important step towards developing AI systems that are not only effective, but also accountable and explainable. As language models become increasingly ubiquitous, this research highlights the importance of pursuing interpretability alongside raw performance.
While further work is needed to address potential limitations and real-world implementation challenges, this paper demonstrates a promising path forward for the field of interpretable AI and the responsible development of large-scale language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Crafting Large Language Models for Enhanced Interpretability
Chung-En Sun, Tuomas Oikarinen, Tsui-Wei Weng
We introduce the Concept Bottleneck Large Language Model (CB-LLM), a pioneering approach to creating inherently interpretable Large Language Models (LLMs). Unlike traditional black-box LLMs that rely on post-hoc interpretation methods with limited neuron function insights, CB-LLM sets a new standard with its built-in interpretability, scalability, and ability to provide clear, accurate explanations. This innovation not only advances transparency in language models but also enhances their effectiveness. Our unique Automatic Concept Correction (ACC) strategy successfully narrows the performance gap with conventional black-box LLMs, positioning CB-LLM as a model that combines the high accuracy of traditional LLMs with the added benefit of clear interpretability -- a feature markedly absent in existing LLMs.
Read more7/8/2024
🌿
0
Coarse-to-Fine Concept Bottleneck Models
Konstantinos P. Panousis, Dino Ienco, Diego Marcos
Deep learning algorithms have recently gained significant attention due to their impressive performance. However, their high complexity and un-interpretable mode of operation hinders their confident deployment in real-world safety-critical tasks. This work targets ante hoc interpretability, and specifically Concept Bottleneck Models (CBMs). Our goal is to design a framework that admits a highly interpretable decision making process with respect to human understandable concepts, on two levels of granularity. To this end, we propose a novel two-level concept discovery formulation leveraging: (i) recent advances in vision-language models, and (ii) an innovative formulation for coarse-to-fine concept selection via data-driven and sparsity-inducing Bayesian arguments. Within this framework, concept information does not solely rely on the similarity between the whole image and general unstructured concepts; instead, we introduce the notion of concept hierarchy to uncover and exploit more granular concept information residing in patch-specific regions of the image scene. As we experimentally show, the proposed construction not only outperforms recent CBM approaches, but also yields a principled framework towards interpetability.
Read more6/28/2024
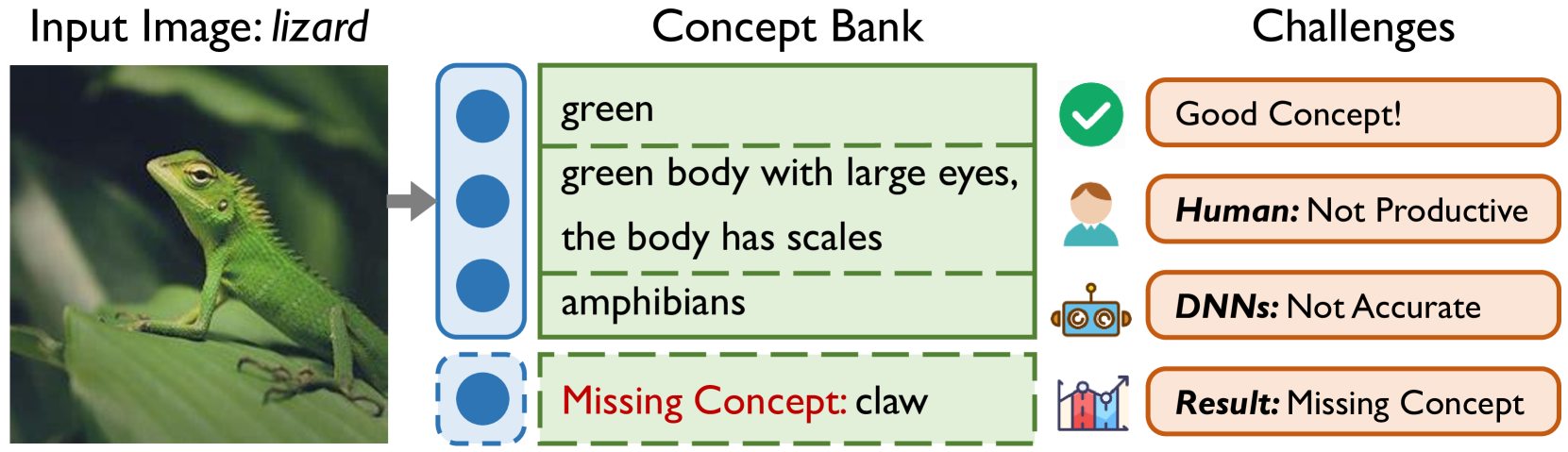
0
Incremental Residual Concept Bottleneck Models
Chenming Shang, Shiji Zhou, Yujiu Yang, Hengyuan Zhang, Xinzhe Ni, Yuwang Wang
Concept Bottleneck Models (CBMs) map the black-box visual representations extracted by deep neural networks onto a set of interpretable concepts and use the concepts to make predictions, enhancing the transparency of the decision-making process. Multimodal pre-trained models can match visual representations with textual concept embeddings, allowing for obtaining the interpretable concept bottleneck without the expertise concept annotations. Recent research has focused on the concept bank establishment and the high-quality concept selection. However, it is challenging to construct a comprehensive concept bank through humans or large language models, which severely limits the performance of CBMs. In this work, we propose the Incremental Residual Concept Bottleneck Model (Res-CBM) to address the challenge of concept completeness. Specifically, the residual concept bottleneck model employs a set of optimizable vectors to complete missing concepts, then the incremental concept discovery module converts the complemented vectors with unclear meanings into potential concepts in the candidate concept bank. Our approach can be applied to any user-defined concept bank, as a post-hoc processing method to enhance the performance of any CBMs. Furthermore, to measure the descriptive efficiency of CBMs, the Concept Utilization Efficiency (CUE) metric is proposed. Experiments show that the Res-CBM outperforms the current state-of-the-art methods in terms of both accuracy and efficiency and achieves comparable performance to black-box models across multiple datasets.
Read more4/16/2024
🤔
0
Interpretable-by-Design Text Understanding with Iteratively Generated Concept Bottleneck
Josh Magnus Ludan, Qing Lyu, Yue Yang, Liam Dugan, Mark Yatskar, Chris Callison-Burch
Black-box deep neural networks excel in text classification, yet their application in high-stakes domains is hindered by their lack of interpretability. To address this, we propose Text Bottleneck Models (TBM), an intrinsically interpretable text classification framework that offers both global and local explanations. Rather than directly predicting the output label, TBM predicts categorical values for a sparse set of salient concepts and uses a linear layer over those concept values to produce the final prediction. These concepts can be automatically discovered and measured by a Large Language Model (LLM) without the need for human curation. Experiments on 12 diverse text understanding datasets demonstrate that TBM can rival the performance of black-box baselines such as few-shot GPT-4 and finetuned DeBERTa while falling short against finetuned GPT-3.5. Comprehensive human evaluation validates that TBM can generate high-quality concepts relevant to the task, and the concept measurement aligns well with human judgments, suggesting that the predictions made by TBMs are interpretable. Overall, our findings suggest that TBM is a promising new framework that enhances interpretability with minimal performance tradeoffs.
Read more4/4/2024