Critique-out-Loud Reward Models

0

Sign in to get full access
Overview
- This paper introduces a new approach called "Critique-out-Loud Reward Models" (COLRM) for training reward models.
- The key idea is to have the model provide critiques of candidate reward functions, which are then used to iteratively refine the reward model.
- The authors demonstrate COLRM on a range of tasks and show it can outperform existing reward modeling techniques.
Plain English Explanation
In machine learning, reward models are used to define the objectives that an agent should try to maximize. Improving Reward Models with Synthetic Critiques is a paper that introduces a new approach called "Critique-out-Loud Reward Models" (COLRM) to train these reward models.
The core insight behind COLRM is that instead of just training the reward model to predict human preferences, you can also have the model provide critiques of candidate reward functions. These critiques are then used to iteratively refine the reward model, making it more accurate and robust.
For example, imagine you're training a reward model for an AI system that needs to do chores around the house. The model might initially learn a reward function that says "clean the house as quickly as possible." But through the critique process, it might identify flaws in that reward function, such as the fact that it doesn't account for how the house looks after cleaning, or that it might incentivize the AI to take shortcuts.
The authors show that this COLRM approach can outperform existing reward modeling techniques on a variety of tasks. By having the model provide critiques, it forces the reward model to become more nuanced and thoughtful, better capturing the true intents and preferences of the humans it is trying to model.
Technical Explanation
The key elements of the COLRM approach are:
-
Reward Model Architecture: The reward model is trained to not only predict human preferences, but also to output critiques of candidate reward functions. This is achieved by having the model output both a reward score and a critique vector.
-
Iterative Refinement: The reward model is trained in an iterative loop. First, candidate reward functions are sampled. The model then provides critiques of these candidates, which are used to refine the reward model. This process continues for multiple iterations.
-
Critique Generation: The critiques produced by the model are designed to be informative and actionable. They capture things like whether the candidate reward function is too simplistic, whether it fails to capture important aspects of the task, or whether it could lead to unintended behaviors.
-
Evaluation Tasks: The authors evaluate COLRM on a range of tasks, including reward modeling for language models, multi-objective reward modeling, and reward model interpretation. They show that COLRM outperforms existing approaches in terms of reward model accuracy and robustness.
Critical Analysis
The COLRM approach represents an interesting and promising direction for improving reward modeling in AI systems. By having the model provide critiques, it encourages the reward model to become more sophisticated and nuanced, rather than simply learning a superficial mapping of human preferences.
However, the paper does not delve deeply into the potential limitations or drawbacks of this approach. For example, it's not clear how scalable the iterative refinement process is, or how well it would work in domains with highly complex or ambiguous reward structures.
Additionally, the paper does not explore the potential risks or unintended consequences of empowering AI models to critique and refine their own reward functions. This could be a double-edged sword, as it could lead to more robust and reliable reward models, but it could also potentially enable the model to "game the system" and optimize for unintended objectives.
Overall, the COLRM approach is a valuable contribution to the field of reward modeling, but further research is needed to fully understand its limitations and potential pitfalls.
Conclusion
The "Critique-out-Loud Reward Models" (COLRM) approach introduced in this paper represents an innovative way to train more accurate and robust reward models for AI systems. By having the model provide critiques of candidate reward functions, the reward model is forced to become more sophisticated and nuanced, better capturing the true intents and preferences of the humans it is trying to model.
While the paper demonstrates the effectiveness of COLRM on a range of tasks, further research is needed to explore the potential limitations and unintended consequences of this approach. Nonetheless, the COLRM framework is a promising step forward in the ongoing quest to develop AI systems that reliably pursue objectives aligned with human values and preferences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Critique-out-Loud Reward Models
Zachary Ankner, Mansheej Paul, Brandon Cui, Jonathan D. Chang, Prithviraj Ammanabrolu
Traditionally, reward models used for reinforcement learning from human feedback (RLHF) are trained to directly predict preference scores without leveraging the generation capabilities of the underlying large language model (LLM). This limits the capabilities of reward models as they must reason implicitly about the quality of a response, i.e., preference modeling must be performed in a single forward pass through the model. To enable reward models to reason explicitly about the quality of a response, we introduce Critique-out-Loud (CLoud) reward models. CLoud reward models operate by first generating a natural language critique of the assistant's response that is then used to predict a scalar reward for the quality of the response. We demonstrate the success of CLoud reward models for both Llama-3-8B and 70B base models: compared to classic reward models CLoud reward models improve pairwise preference classification accuracy on RewardBench by 4.65 and 5.84 percentage points for the 8B and 70B base models respectively. Furthermore, CLoud reward models lead to a Pareto improvement for win rate on ArenaHard when used as the scoring model for Best-of-N. Finally, we explore how to exploit the dynamic inference compute capabilities of CLoud reward models by performing self-consistency decoding for reward prediction.
Read more8/22/2024

0
RewardBench: Evaluating Reward Models for Language Modeling
Nathan Lambert, Valentina Pyatkin, Jacob Morrison, LJ Miranda, Bill Yuchen Lin, Khyathi Chandu, Nouha Dziri, Sachin Kumar, Tom Zick, Yejin Choi, Noah A. Smith, Hannaneh Hajishirzi
Reward models (RMs) are at the crux of successfully using RLHF to align pretrained models to human preferences, yet there has been relatively little study that focuses on evaluation of those models. Evaluating reward models presents an opportunity to understand the opaque technologies used for alignment of language models and which values are embedded in them. Resources for reward model training and understanding are sparse in the nascent open-source community around them. To enhance scientific understanding of reward models, we present RewardBench, a benchmark dataset and code-base for evaluation. The RewardBench dataset is a collection of prompt-chosen-rejected trios spanning chat, reasoning, and safety, to benchmark how reward models perform on challenging, structured and out-of-distribution queries. We create specific comparison datasets for RMs that have subtle, but verifiable reasons (e.g. bugs, incorrect facts) why one answer should be preferred to another. On the RewardBench leaderboard, we evaluate reward models trained with a variety of methods, such as the direct MLE training of classifiers and the implicit reward modeling of Direct Preference Optimization (DPO). We present many findings on propensity for refusals, reasoning limitations, and instruction following shortcomings of various reward models towards a better understanding of the RLHF process.
Read more6/11/2024
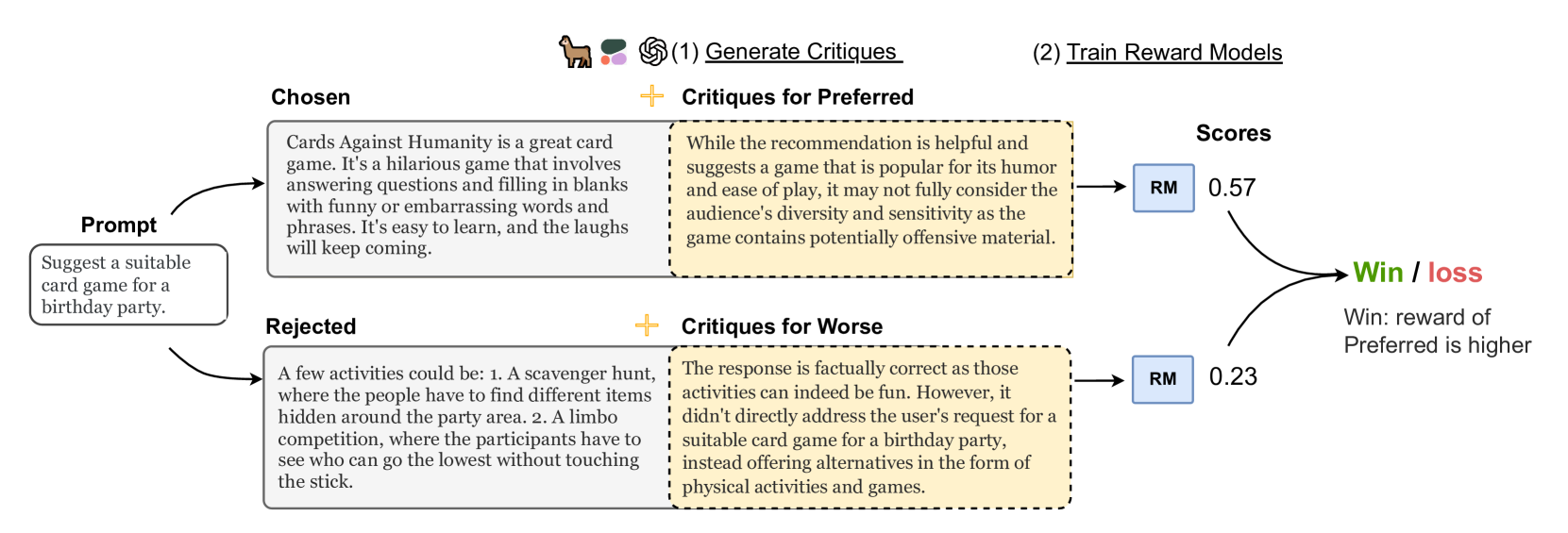
0
Improving Reward Models with Synthetic Critiques
Zihuiwen Ye, Fraser Greenlee-Scott, Max Bartolo, Phil Blunsom, Jon Ander Campos, Matthias Gall'e
Reward models (RM) play a critical role in aligning language models through the process of reinforcement learning from human feedback. RMs are trained to predict a score reflecting human preference, which requires significant time and cost for human annotation. Additionally, RMs tend to quickly overfit on superficial features in the training set, hindering their generalization performance on unseen distributions. We propose a novel approach using synthetic natural language critiques generated by large language models to provide additional feedback, evaluating aspects such as instruction following, correctness, and style. This offers richer signals and more robust features for RMs to assess and score on. We demonstrate that high-quality critiques improve the performance and data efficiency of RMs initialized from different pretrained models. Conversely, we also show that low-quality critiques negatively impact performance. Furthermore, incorporating critiques enhances the interpretability and robustness of RM training.
Read more6/3/2024
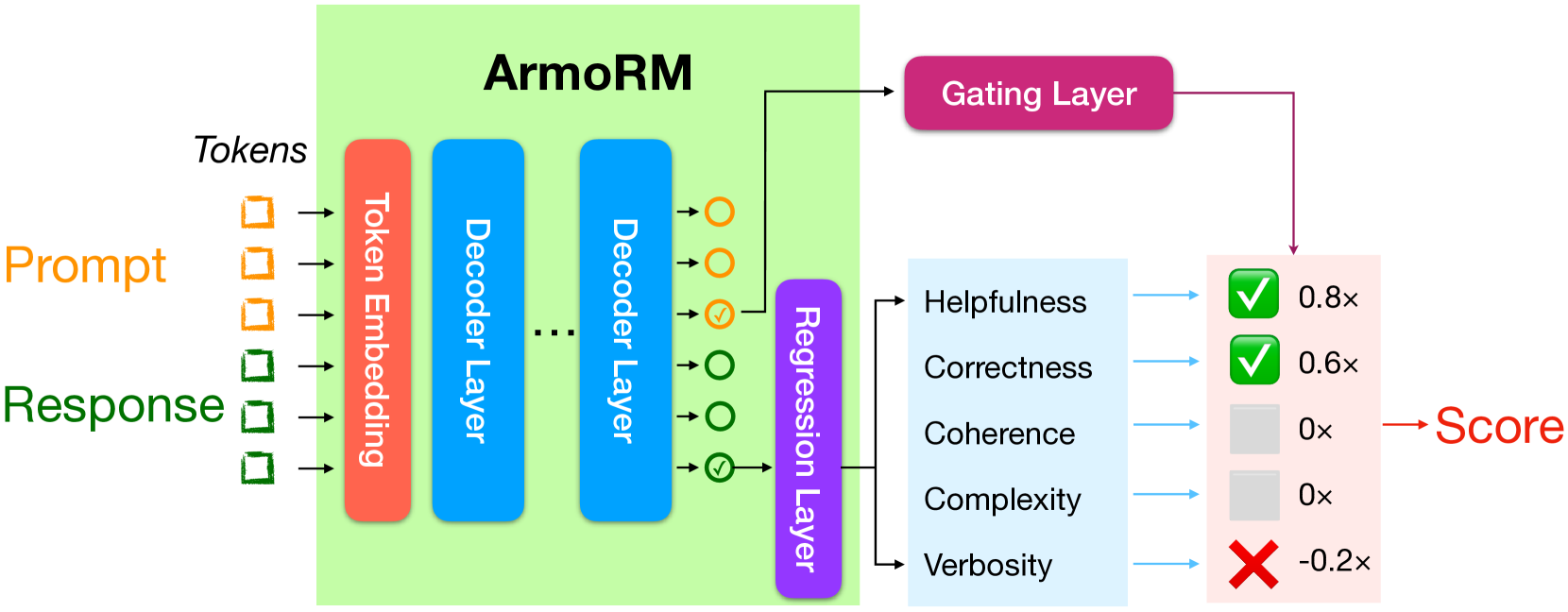
0
Interpretable Preferences via Multi-Objective Reward Modeling and Mixture-of-Experts
Haoxiang Wang, Wei Xiong, Tengyang Xie, Han Zhao, Tong Zhang
Reinforcement learning from human feedback (RLHF) has emerged as the primary method for aligning large language models (LLMs) with human preferences. The RLHF process typically starts by training a reward model (RM) using human preference data. Conventional RMs are trained on pairwise responses to the same user request, with relative ratings indicating which response humans prefer. The trained RM serves as a proxy for human preferences. However, due to the black-box nature of RMs, their outputs lack interpretability, as humans cannot intuitively understand why an RM thinks a response is good or not. As RMs act as human preference proxies, we believe they should be human-interpretable to ensure that their internal decision processes are consistent with human preferences and to prevent reward hacking in LLM alignment. To build RMs with interpretable preferences, we propose a two-stage approach: i) train an Absolute-Rating Multi-Objective Reward Model (ArmoRM) with multi-dimensional absolute-rating data, each dimension corresponding to a human-interpretable objective (e.g., honesty, verbosity, safety); ii) employ a Mixture-of-Experts (MoE) strategy with a gating network that automatically selects the most suitable reward objectives based on the context. We efficiently trained an ArmoRM with Llama-3 8B and a gating network consisting of a shallow MLP on top of the ArmoRM. Our trained model, ArmoRM-Llama3-8B, obtains state-of-the-art performance on RewardBench, a benchmark evaluating RMs for language modeling. Notably, the performance of our model surpasses the LLM-as-a-judge method with GPT-4 judges by a margin, and approaches the performance of the much larger Nemotron-4 340B reward model.
Read more6/19/2024