RewardBench: Evaluating Reward Models for Language Modeling

0

Sign in to get full access
Overview
- This paper introduces RewardBench, a framework for evaluating reward models used in language modeling tasks.
- Reward models play a critical role in reinforcement learning from human feedback, an approach where AI systems learn from evaluative feedback provided by humans.
- RewardBench tests the performance of reward models on a diverse set of tasks, allowing researchers to better understand the strengths and limitations of different reward modeling approaches.
Plain English Explanation
When training AI systems to perform language tasks, one key challenge is figuring out how to reward the system for doing a good job. Reinforcement learning from human feedback is an approach where the AI learns by receiving evaluative feedback from humans, but designing effective reward models for this can be difficult.
The researchers created RewardBench to help evaluate different reward modeling techniques. RewardBench tests reward models on a variety of language tasks, measuring how well the models can capture human preferences and guide the AI system to generate high-quality text. This allows researchers to see the strengths and weaknesses of different reward modeling approaches and figure out how to improve them.
Improving reward models with synthetic critiques and leveraging domain knowledge for efficient reward modeling are examples of recent techniques that RewardBench could be used to evaluate. Overall, RewardBench provides a valuable tool for the AI research community to advance the state-of-the-art in reinforcement learning from human feedback.
Technical Explanation
The paper introduces RewardBench, a framework for evaluating reward models used in language modeling tasks. Reward models play a crucial role in reinforcement learning from human feedback (RLHF), an approach where AI systems learn by receiving evaluative feedback from humans.
RewardBench consists of a diverse set of language tasks, including text generation, text summarization, and question answering. The framework tests reward models on these tasks, measuring how well the models can capture human preferences and guide the AI system to generate high-quality text. This allows researchers to understand the strengths and limitations of different reward modeling techniques.
The paper presents several benchmark tasks within RewardBench and demonstrates how the framework can be used to evaluate reward models. The authors show that existing reward modeling approaches have varying performance across the different tasks, highlighting the need for more robust and generalizable reward models.
Critical Analysis
The RewardBench framework is a valuable contribution to the field of reinforcement learning from human feedback. By providing a standardized set of tasks and evaluation metrics, the framework can help researchers better understand the tradeoffs and limitations of different reward modeling approaches.
However, the paper does not address some potential limitations of the RewardBench framework. For example, the tasks included may not be representative of all real-world language modeling challenges, and the framework may not capture the nuances of human preferences in complex, open-ended scenarios. Towards understanding the influence of the reward margin on preference model performance highlights the importance of considering these contextual factors when designing reward models.
Additionally, the paper does not delve into the potential biases or ethical considerations that may arise from reward modeling techniques. As AI systems become more capable of engaging with humans, it is crucial to consider how the reward models used to train these systems may reflect or amplify societal biases. Further research is needed to address these important issues.
Conclusion
The RewardBench framework introduced in this paper represents an important step forward in the evaluation of reward models for language modeling tasks. By providing a standardized benchmark, the framework can help researchers identify the strengths and limitations of different reward modeling approaches, ultimately leading to the development of more robust and generalizable reward models.
As the field of reinforcement learning from human feedback continues to evolve, tools like RewardBench will be crucial for driving progress and ensuring that AI systems are trained in a way that aligns with human values and preferences. The insights gained from using RewardBench can inform the design of more efficient and ethical reward modeling techniques, with potentially far-reaching implications for the development of advanced AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
RewardBench: Evaluating Reward Models for Language Modeling
Nathan Lambert, Valentina Pyatkin, Jacob Morrison, LJ Miranda, Bill Yuchen Lin, Khyathi Chandu, Nouha Dziri, Sachin Kumar, Tom Zick, Yejin Choi, Noah A. Smith, Hannaneh Hajishirzi
Reward models (RMs) are at the crux of successfully using RLHF to align pretrained models to human preferences, yet there has been relatively little study that focuses on evaluation of those models. Evaluating reward models presents an opportunity to understand the opaque technologies used for alignment of language models and which values are embedded in them. Resources for reward model training and understanding are sparse in the nascent open-source community around them. To enhance scientific understanding of reward models, we present RewardBench, a benchmark dataset and code-base for evaluation. The RewardBench dataset is a collection of prompt-chosen-rejected trios spanning chat, reasoning, and safety, to benchmark how reward models perform on challenging, structured and out-of-distribution queries. We create specific comparison datasets for RMs that have subtle, but verifiable reasons (e.g. bugs, incorrect facts) why one answer should be preferred to another. On the RewardBench leaderboard, we evaluate reward models trained with a variety of methods, such as the direct MLE training of classifiers and the implicit reward modeling of Direct Preference Optimization (DPO). We present many findings on propensity for refusals, reasoning limitations, and instruction following shortcomings of various reward models towards a better understanding of the RLHF process.
Read more6/11/2024
0
Interpretable Preferences via Multi-Objective Reward Modeling and Mixture-of-Experts
Haoxiang Wang, Wei Xiong, Tengyang Xie, Han Zhao, Tong Zhang
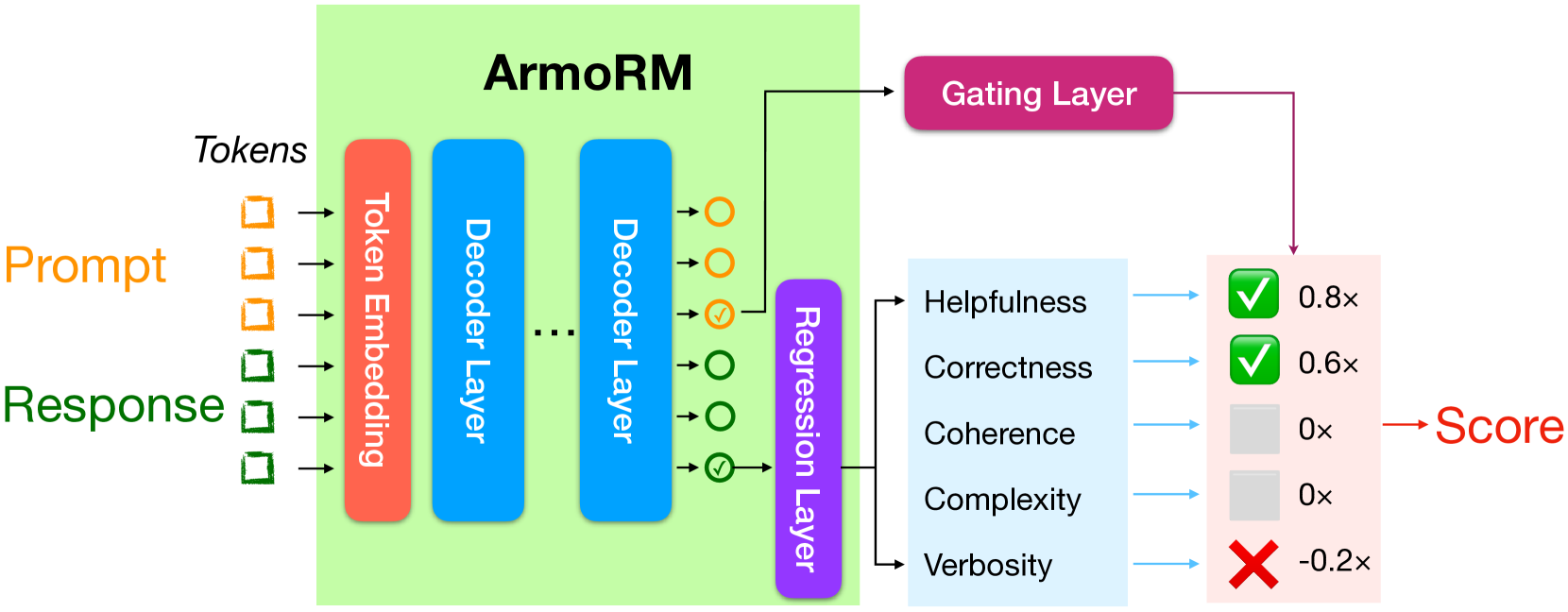
Reinforcement learning from human feedback (RLHF) has emerged as the primary method for aligning large language models (LLMs) with human preferences. The RLHF process typically starts by training a reward model (RM) using human preference data. Conventional RMs are trained on pairwise responses to the same user request, with relative ratings indicating which response humans prefer. The trained RM serves as a proxy for human preferences. However, due to the black-box nature of RMs, their outputs lack interpretability, as humans cannot intuitively understand why an RM thinks a response is good or not. As RMs act as human preference proxies, we believe they should be human-interpretable to ensure that their internal decision processes are consistent with human preferences and to prevent reward hacking in LLM alignment. To build RMs with interpretable preferences, we propose a two-stage approach: i) train an Absolute-Rating Multi-Objective Reward Model (ArmoRM) with multi-dimensional absolute-rating data, each dimension corresponding to a human-interpretable objective (e.g., honesty, verbosity, safety); ii) employ a Mixture-of-Experts (MoE) strategy with a gating network that automatically selects the most suitable reward objectives based on the context. We efficiently trained an ArmoRM with Llama-3 8B and a gating network consisting of a shallow MLP on top of the ArmoRM. Our trained model, ArmoRM-Llama3-8B, obtains state-of-the-art performance on RewardBench, a benchmark evaluating RMs for language modeling. Notably, the performance of our model surpasses the LLM-as-a-judge method with GPT-4 judges by a margin, and approaches the performance of the much larger Nemotron-4 340B reward model.
Read more6/19/2024
0
Towards Understanding the Influence of Reward Margin on Preference Model Performance
Bowen Qin, Duanyu Feng, Xi Yang
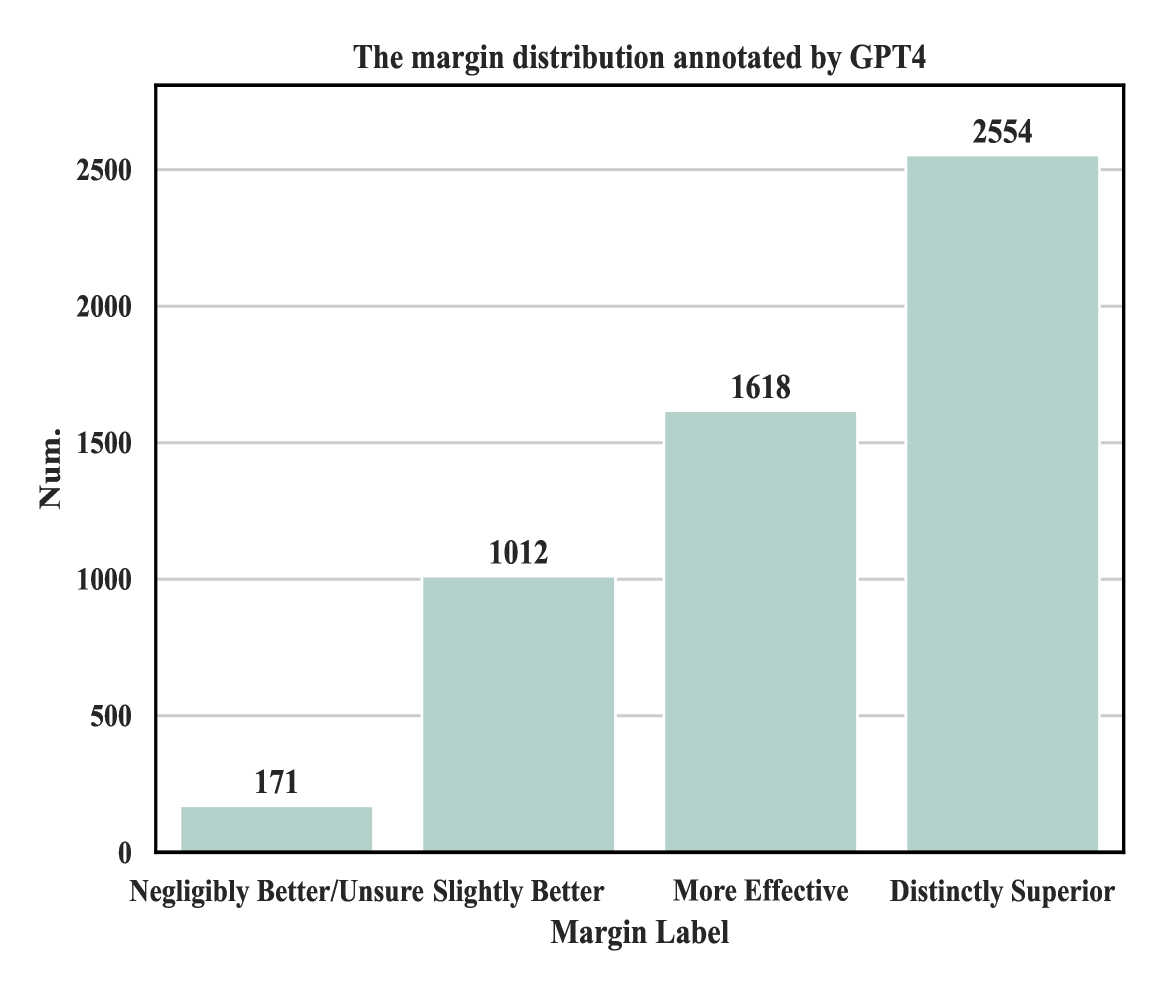
Reinforcement Learning from Human Feedback (RLHF) is a widely used framework for the training of language models. However, the process of using RLHF to develop a language model that is well-aligned presents challenges, especially when it comes to optimizing the reward model. Our research has found that existing reward models, when trained using the traditional ranking objective based on human preference data, often struggle to effectively distinguish between responses that are more or less favorable in real-world scenarios. To bridge this gap, our study introduces a novel method to estimate the preference differences without the need for detailed, exhaustive labels from human annotators. Our experimental results provide empirical evidence that incorporating margin values into the training process significantly improves the effectiveness of reward models. This comparative analysis not only demonstrates the superiority of our approach in terms of reward prediction accuracy but also highlights its effectiveness in practical applications.
Read more4/9/2024

0
Critique-out-Loud Reward Models
Zachary Ankner, Mansheej Paul, Brandon Cui, Jonathan D. Chang, Prithviraj Ammanabrolu
Traditionally, reward models used for reinforcement learning from human feedback (RLHF) are trained to directly predict preference scores without leveraging the generation capabilities of the underlying large language model (LLM). This limits the capabilities of reward models as they must reason implicitly about the quality of a response, i.e., preference modeling must be performed in a single forward pass through the model. To enable reward models to reason explicitly about the quality of a response, we introduce Critique-out-Loud (CLoud) reward models. CLoud reward models operate by first generating a natural language critique of the assistant's response that is then used to predict a scalar reward for the quality of the response. We demonstrate the success of CLoud reward models for both Llama-3-8B and 70B base models: compared to classic reward models CLoud reward models improve pairwise preference classification accuracy on RewardBench by 4.65 and 5.84 percentage points for the 8B and 70B base models respectively. Furthermore, CLoud reward models lead to a Pareto improvement for win rate on ArenaHard when used as the scoring model for Best-of-N. Finally, we explore how to exploit the dynamic inference compute capabilities of CLoud reward models by performing self-consistency decoding for reward prediction.
Read more8/22/2024