Improving Reward Models with Synthetic Critiques

0
Sign in to get full access
Overview
- This paper explores a method for improving reward models in reinforcement learning (RL) systems by incorporating synthetic critiques.
- The authors propose generating synthetic critiques, or feedback, to augment the training data for the reward model, which aims to better align the agent's behavior with human preferences.
- The approach is evaluated on several benchmark tasks, demonstrating improved performance compared to baseline RL methods.
Plain English Explanation
The paper focuses on a common challenge in reinforcement learning (RL) - how to design reward functions that accurately capture human preferences. In RL, an agent learns to perform tasks by receiving rewards or punishments based on the actions it takes. However, defining a perfect reward function that aligns with human values is difficult, as humans often have complex and nuanced preferences.
To address this, the authors introduce a method that generates synthetic critiques, or feedback, to supplement the training data for the reward model. The idea is that by providing the RL agent with more diverse feedback, the reward model can better learn to capture the subtleties of human preferences. This synthetic feedback is generated using language models and other techniques, rather than relying solely on human-provided rewards.
The researchers evaluate their approach on several benchmark tasks, such as text generation and object manipulation, and find that it outperforms traditional RL methods that use only human-provided rewards. This suggests that incorporating synthetic critiques can be a valuable technique for improving the alignment between RL agents and human values.
Technical Explanation
The paper proposes a method for improving reward models in reinforcement learning by incorporating synthetic critiques. The core idea is to augment the training data for the reward model with generated feedback, which can help the model better capture the nuances of human preferences.
The authors first train a reward model using human-provided rewards and critiques on a set of training tasks. They then use this reward model to generate synthetic critiques for a larger set of unlabeled data. These synthetic critiques are then added to the training data, and the reward model is fine-tuned on the augmented dataset.
The synthetic critiques are generated using a combination of techniques, including [leveraging-human-revisions-improving-text-to-layout] and [rafe-ranking-feedback-improves-query-rewriting-rag]. The authors experiment with different approaches for generating the critiques, such as using language models to produce text feedback and reinforcement learning to generate structured critiques.
The authors evaluate their approach on several benchmark tasks, including [rethinking-role-proxy-rewards-language-model-alignment] and [towards-understanding-influence-reward-margin-preference-model]. They find that the RL agents trained with the augmented reward models outperform baseline RL methods that use only human-provided rewards.
Critical Analysis
The paper presents a promising approach for improving reward models in reinforcement learning, but it also has some potential limitations and areas for further research.
One key limitation is the reliance on the initial reward model trained on human-provided data. The quality and robustness of this initial model may significantly impact the effectiveness of the synthetic critique generation and the overall performance of the system. The authors acknowledge this and suggest exploring ways to make the initial reward model more reliable.
Additionally, the paper does not fully address the potential biases or errors that may be introduced by the synthetic critique generation process. While the authors experiment with different techniques, it's unclear how the quality and diversity of the generated critiques compares to human-provided feedback. Further research is needed to understand the limitations and potential pitfalls of this approach.
Another area for further exploration is the scalability of the method. The paper focuses on relatively simple benchmark tasks, and it's unclear how well the approach would scale to more complex, real-world problems. Incorporating synthetic critiques may become computationally expensive or challenging to implement as the task complexity increases.
Overall, the paper presents an interesting and potentially valuable approach for improving reward model alignment in reinforcement learning. However, the limitations and areas for further research highlighted above suggest that more work is needed to fully understand the capabilities and potential pitfalls of this technique.
Conclusion
This paper introduces a method for improving reward models in reinforcement learning by incorporating synthetic critiques. The core idea is to augment the training data for the reward model with generated feedback, which can help the model better capture the nuances of human preferences.
The authors evaluate their approach on several benchmark tasks and find that RL agents trained with the augmented reward models outperform baseline RL methods that use only human-provided rewards. This suggests that incorporating synthetic critiques can be a valuable technique for improving the alignment between RL agents and human values.
While the paper presents a promising approach, it also highlights some potential limitations and areas for further research, such as the reliance on the initial reward model, the potential biases in the synthetic critique generation, and the scalability of the method to more complex tasks. Nonetheless, this work represents an important step forward in the ongoing effort to develop RL systems that reliably align with human preferences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Improving Reward Models with Synthetic Critiques
Zihuiwen Ye, Fraser Greenlee-Scott, Max Bartolo, Phil Blunsom, Jon Ander Campos, Matthias Gall'e
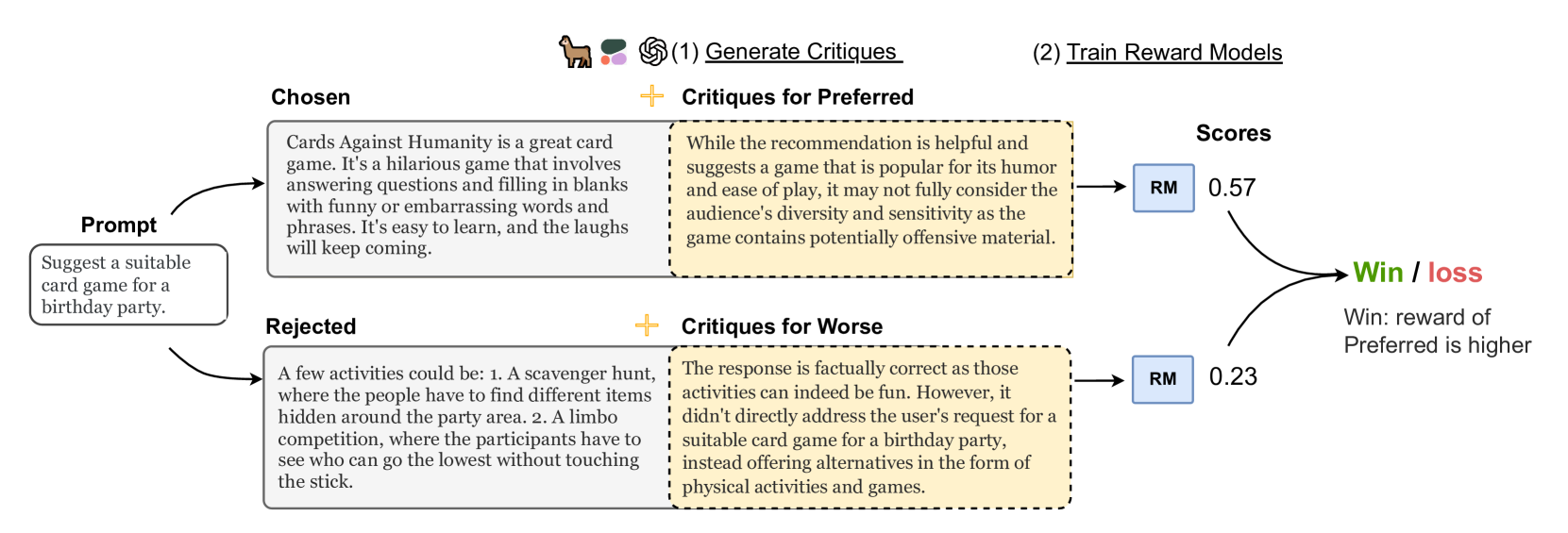
Reward models (RM) play a critical role in aligning language models through the process of reinforcement learning from human feedback. RMs are trained to predict a score reflecting human preference, which requires significant time and cost for human annotation. Additionally, RMs tend to quickly overfit on superficial features in the training set, hindering their generalization performance on unseen distributions. We propose a novel approach using synthetic natural language critiques generated by large language models to provide additional feedback, evaluating aspects such as instruction following, correctness, and style. This offers richer signals and more robust features for RMs to assess and score on. We demonstrate that high-quality critiques improve the performance and data efficiency of RMs initialized from different pretrained models. Conversely, we also show that low-quality critiques negatively impact performance. Furthermore, incorporating critiques enhances the interpretability and robustness of RM training.
Read more6/3/2024

0
Critique-out-Loud Reward Models
Zachary Ankner, Mansheej Paul, Brandon Cui, Jonathan D. Chang, Prithviraj Ammanabrolu
Traditionally, reward models used for reinforcement learning from human feedback (RLHF) are trained to directly predict preference scores without leveraging the generation capabilities of the underlying large language model (LLM). This limits the capabilities of reward models as they must reason implicitly about the quality of a response, i.e., preference modeling must be performed in a single forward pass through the model. To enable reward models to reason explicitly about the quality of a response, we introduce Critique-out-Loud (CLoud) reward models. CLoud reward models operate by first generating a natural language critique of the assistant's response that is then used to predict a scalar reward for the quality of the response. We demonstrate the success of CLoud reward models for both Llama-3-8B and 70B base models: compared to classic reward models CLoud reward models improve pairwise preference classification accuracy on RewardBench by 4.65 and 5.84 percentage points for the 8B and 70B base models respectively. Furthermore, CLoud reward models lead to a Pareto improvement for win rate on ArenaHard when used as the scoring model for Best-of-N. Finally, we explore how to exploit the dynamic inference compute capabilities of CLoud reward models by performing self-consistency decoding for reward prediction.
Read more8/22/2024

0
Boosting Reward Model with Preference-Conditional Multi-Aspect Synthetic Data Generation
Jiaming Shen, Ran Xu, Yennie Jun, Zhen Qin, Tianqi Liu, Carl Yang, Yi Liang, Simon Baumgartner, Michael Bendersky
Reward models (RMs) are crucial for aligning large language models (LLMs) with human preferences. They are trained using preference datasets where each example consists of one input prompt, two responses, and a preference label. As curating a high-quality human labeled preference dataset is both time-consuming and expensive, people often rely on existing powerful LLMs for preference label generation. This can potentially introduce noise and impede RM training. In this work, we present RMBoost, a novel synthetic preference data generation paradigm to boost reward model quality. Unlike traditional methods, which generate two responses before obtaining the preference label, RMBoost first generates one response and selects a preference label, followed by generating the second more (or less) preferred response conditioned on the pre-selected preference label and the first response. This approach offers two main advantages. First, RMBoost reduces labeling noise since preference pairs are constructed intentionally. Second, RMBoost facilitates the creation of more diverse responses by incorporating various quality aspects (e.g., helpfulness, relevance, completeness) into the prompts. We conduct extensive experiments across three diverse datasets and demonstrate that RMBoost outperforms other synthetic preference data generation techniques and significantly boosts the performance of four distinct reward models.
Read more7/24/2024

0
RewardBench: Evaluating Reward Models for Language Modeling
Nathan Lambert, Valentina Pyatkin, Jacob Morrison, LJ Miranda, Bill Yuchen Lin, Khyathi Chandu, Nouha Dziri, Sachin Kumar, Tom Zick, Yejin Choi, Noah A. Smith, Hannaneh Hajishirzi
Reward models (RMs) are at the crux of successfully using RLHF to align pretrained models to human preferences, yet there has been relatively little study that focuses on evaluation of those models. Evaluating reward models presents an opportunity to understand the opaque technologies used for alignment of language models and which values are embedded in them. Resources for reward model training and understanding are sparse in the nascent open-source community around them. To enhance scientific understanding of reward models, we present RewardBench, a benchmark dataset and code-base for evaluation. The RewardBench dataset is a collection of prompt-chosen-rejected trios spanning chat, reasoning, and safety, to benchmark how reward models perform on challenging, structured and out-of-distribution queries. We create specific comparison datasets for RMs that have subtle, but verifiable reasons (e.g. bugs, incorrect facts) why one answer should be preferred to another. On the RewardBench leaderboard, we evaluate reward models trained with a variety of methods, such as the direct MLE training of classifiers and the implicit reward modeling of Direct Preference Optimization (DPO). We present many findings on propensity for refusals, reasoning limitations, and instruction following shortcomings of various reward models towards a better understanding of the RLHF process.
Read more6/11/2024