CritiqueLLM: Towards an Informative Critique Generation Model for Evaluation of Large Language Model Generation

0
Sign in to get full access
Overview
- This paper introduces CritiqueLLM, a system that uses large language models (LLMs) to provide effective and explainable evaluation of other LLM-generated content.
- CritiqueLLM aims to scale the "LLM-as-critic" approach for evaluating LLM outputs, addressing limitations of existing methods.
- The paper presents the CritiqueLLM architecture and demonstrates its effectiveness through experiments on diverse LLM generation tasks.
Plain English Explanation
Large language models (LLMs) like GPT-3 have become powerful tools for generating human-like text. However, evaluating the quality and coherence of these LLM-generated outputs is a significant challenge. Systematic Evaluation of Large Language Models for Natural Language and Pre-Peer Review, Large Language Model-Based Evaluation have explored using LLMs themselves as "critics" to evaluate other LLM-generated content.
The authors of this paper introduce CritiqueLLM, a system that builds on this "LLM-as-critic" approach to provide more effective and explainable evaluation of LLM outputs. CritiqueLLM aims to address limitations of existing methods, such as the difficulty of scaling LLM-based evaluation to diverse generation tasks.
The paper describes the CritiqueLLM architecture and demonstrates its effectiveness through experiments on a range of LLM generation tasks, including Critique of Critique, Leveraging Large Language Models for NLG Evaluation Advances, and Open-Source Language Models Can Provide Feedback. The results show that CritiqueLLM can provide reliable and interpretable evaluation of LLM-generated content, paving the way for more effective development and deployment of these powerful language models.
Technical Explanation
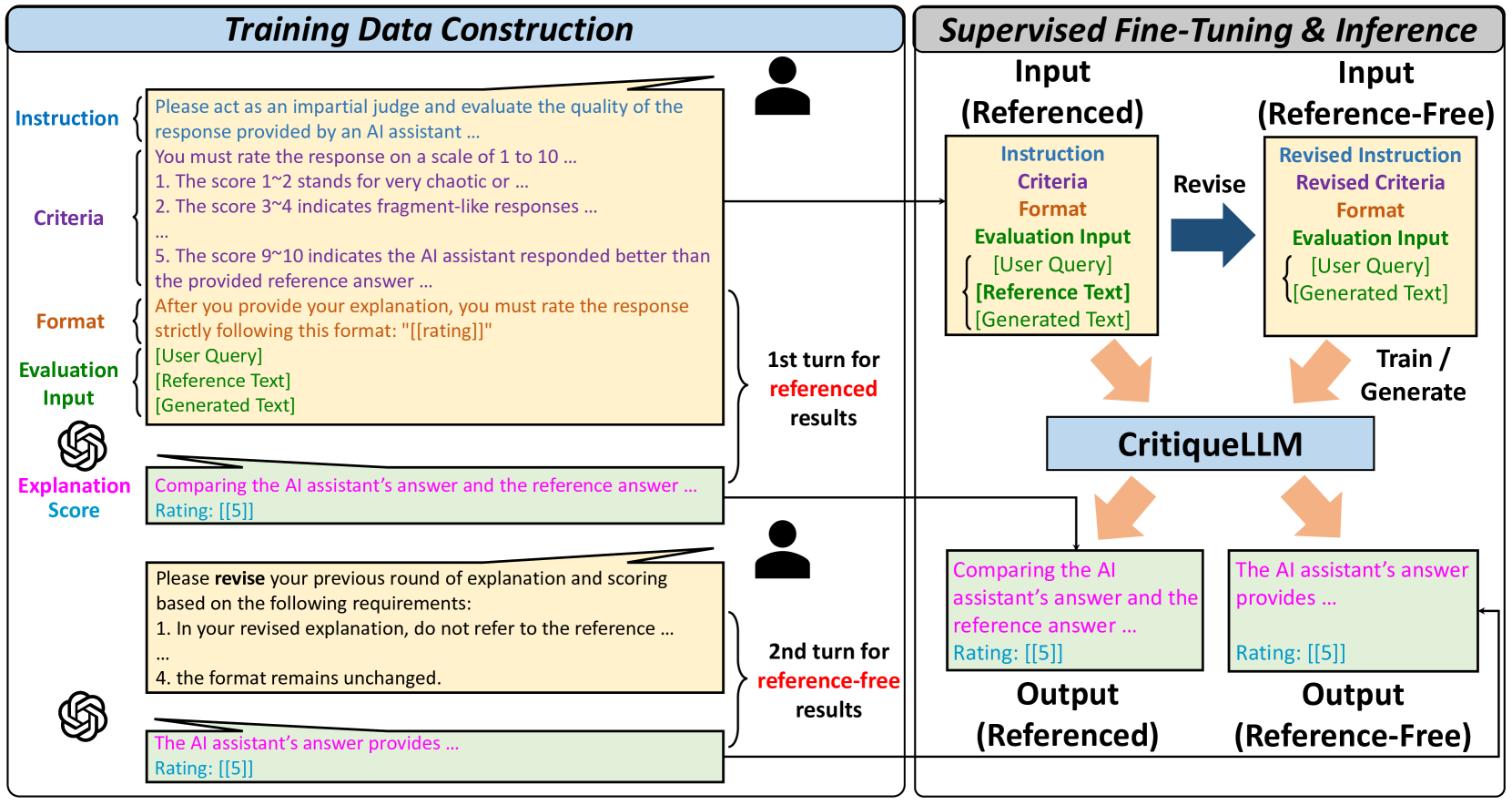
The CritiqueLLM system uses a large language model as the "critic" to evaluate the quality and coherence of LLM-generated outputs. The key components of the CritiqueLLM architecture include:
-
Input Preparation: CritiqueLLM takes the LLM-generated output and the original prompt as input, and processes them to create a structured representation suitable for the evaluation model.
-
Evaluation Model: The core of CritiqueLLM is a large language model that has been fine-tuned to perform the task of evaluating the quality and coherence of the input text. This evaluation model is trained on a diverse dataset of high-quality and low-quality LLM-generated content.
-
Explanation Generation: In addition to providing an overall quality score, CritiqueLLM also generates natural language explanations for its evaluations. This allows users to understand the reasoning behind the model's assessment.
The paper presents experiments on a range of LLM generation tasks, including open-ended text generation, summarization, and dialogue. The results demonstrate that CritiqueLLM can effectively evaluate the quality of LLM-generated outputs, outperforming baseline methods. Furthermore, the natural language explanations provided by CritiqueLLM offer valuable insights into the model's decision-making process.
Critical Analysis
The CritiqueLLM approach represents a significant advancement in the evaluation of LLM-generated content, but it also has some limitations and areas for further research:
- The effectiveness of CritiqueLLM is highly dependent on the quality and diversity of the training data used to fine-tune the evaluation model. Ensuring the dataset covers a wide range of generation tasks and quality levels is crucial for generalization.
- The natural language explanations provided by CritiqueLLM, while valuable, may not always be fully interpretable or aligned with human intuitions about text quality. Exploring ways to improve the transparency and interpretability of these explanations is an important area for future work.
- The scalability of CritiqueLLM to extremely large-scale LLM generation tasks, such as those involving millions of tokens, may be limited by the computational resources required. Investigating more efficient evaluation approaches could further enhance the system's practical applicability.
Overall, the CritiqueLLM system represents a significant step forward in the development of effective and explainable LLM evaluation methods, and the insights and techniques presented in this paper could have wide-ranging implications for the field of natural language generation.
Conclusion
This paper introduces CritiqueLLM, a novel system that leverages large language models to provide effective and explainable evaluation of LLM-generated content. By addressing limitations of existing methods, CritiqueLLM offers a more scalable and interpretable approach to assessing the quality and coherence of LLM outputs.
The experimental results demonstrate the effectiveness of CritiqueLLM across a range of LLM generation tasks, and the natural language explanations generated by the system offer valuable insights into the decision-making process. While the approach has some limitations, the techniques and insights presented in this paper represent an important contribution to the field of natural language generation and could pave the way for more robust and transparent LLM evaluation methods in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CritiqueLLM: Towards an Informative Critique Generation Model for Evaluation of Large Language Model Generation
Pei Ke, Bosi Wen, Zhuoer Feng, Xiao Liu, Xuanyu Lei, Jiale Cheng, Shengyuan Wang, Aohan Zeng, Yuxiao Dong, Hongning Wang, Jie Tang, Minlie Huang
Since the natural language processing (NLP) community started to make large language models (LLMs) act as a critic to evaluate the quality of generated texts, most of the existing works train a critique generation model on the evaluation data labeled by GPT-4's direct prompting. We observe that these models lack the ability to generate informative critiques in both pointwise grading and pairwise comparison especially without references. As a result, their generated critiques cannot provide fine-grained distinguishability on generated texts, causing unsatisfactory evaluation performance. In this paper, we propose a simple yet effective method called Eval-Instruct, which can first acquire pointwise grading critiques with pseudo references and then revise these critiques via multi-path prompting to obtain informative evaluation data in different tasks and settings, including pointwise grading and pairwise comparison with / without references. After fine-tuning on these data, the resulting model CritiqueLLM is empirically shown to outperform ChatGPT and all the open-source baselines and even achieve comparable evaluation performance to GPT-4 in system-level correlations of pointwise grading. We also demonstrate that our generated critiques can act as scalable feedback to further improve the generation quality of strong LLMs like ChatGPT.
Read more6/27/2024
0
CriticEval: Evaluating Large Language Model as Critic
Tian Lan, Wenwei Zhang, Chen Xu, Heyan Huang, Dahua Lin, Kai Chen, Xian-ling Mao
Critique ability, i.e., the capability of Large Language Models (LLMs) to identify and rectify flaws in responses, is crucial for their applications in self-improvement and scalable oversight. While numerous studies have been proposed to evaluate critique ability of LLMs, their comprehensiveness and reliability are still limited. To overcome this problem, we introduce CriticEval, a novel benchmark designed to comprehensively and reliably evaluate critique ability of LLMs. Specifically, to ensure the comprehensiveness, CriticEval evaluates critique ability from four dimensions across nine diverse task scenarios. It evaluates both scalar-valued and textual critiques, targeting responses of varying quality. To ensure the reliability, a large number of critiques are annotated to serve as references, enabling GPT-4 to evaluate textual critiques reliably. Extensive evaluations of open-source and closed-source LLMs first validate the reliability of evaluation in CriticEval. Then, experimental results demonstrate the promising potential of open-source LLMs, the effectiveness of critique datasets and several intriguing relationships between the critique ability and some critical factors, including task types, response qualities and critique dimensions. Datasets and evaluation toolkit for CriticEval will be publicly released.
Read more9/12/2024

0
A Systematic Evaluation of Large Language Models for Natural Language Generation Tasks
Xuanfan Ni, Piji Li
Recent efforts have evaluated large language models (LLMs) in areas such as commonsense reasoning, mathematical reasoning, and code generation. However, to the best of our knowledge, no work has specifically investigated the performance of LLMs in natural language generation (NLG) tasks, a pivotal criterion for determining model excellence. Thus, this paper conducts a comprehensive evaluation of well-known and high-performing LLMs, namely ChatGPT, ChatGLM, T5-based models, LLaMA-based models, and Pythia-based models, in the context of NLG tasks. We select English and Chinese datasets encompassing Dialogue Generation and Text Summarization. Moreover, we propose a common evaluation setting that incorporates input templates and post-processing strategies. Our study reports both automatic results, accompanied by a detailed analysis.
Read more5/17/2024
💬
0
From Text to Insight: Leveraging Large Language Models for Performance Evaluation in Management
Ning Li, Huaikang Zhou, Mingze Xu
This study explores the potential of Large Language Models (LLMs), specifically GPT-4, to enhance objectivity in organizational task performance evaluations. Through comparative analyses across two studies, including various task performance outputs, we demonstrate that LLMs can serve as a reliable and even superior alternative to human raters in evaluating knowledge-based performance outputs, which are a key contribution of knowledge workers. Our results suggest that GPT ratings are comparable to human ratings but exhibit higher consistency and reliability. Additionally, combined multiple GPT ratings on the same performance output show strong correlations with aggregated human performance ratings, akin to the consensus principle observed in performance evaluation literature. However, we also find that LLMs are prone to contextual biases, such as the halo effect, mirroring human evaluative biases. Our research suggests that while LLMs are capable of extracting meaningful constructs from text-based data, their scope is currently limited to specific forms of performance evaluation. By highlighting both the potential and limitations of LLMs, our study contributes to the discourse on AI role in management studies and sets a foundation for future research to refine AI theoretical and practical applications in management.
Read more8/13/2024