The Critique of Critique

0

Sign in to get full access
Overview
- This paper presents a critique of the practice of critique in the field of AI research and development.
- It explores the potential limitations and biases inherent in the current critique process, and proposes strategies for improving the quality and objectivity of critique.
- The paper covers topics such as reference generation, AIU extraction, and meta-evaluation as part of the metacritique framework.
Plain English Explanation
The paper argues that the current process of critique in AI research and development may be flawed. Critique is an essential part of the scientific process, as it helps to identify weaknesses, biases, and areas for improvement in research. However, the authors suggest that the way critique is currently conducted may be biased or overly subjective.
For example, the authors discuss the issue of reference generation, where researchers may select comparison points or baselines that unfairly advantage their own work. They also explore the challenge of AIU extraction, where the identification of key issues in a paper may be influenced by the biases and perspectives of the reviewer.
To address these concerns, the authors propose a framework they call "metacritique," which aims to make the critique process more rigorous, objective, and transparent. This includes strategies for meta-evaluation of critiques, as well as ways to qualitatively evaluate the impact of critiques on model improvement.
Overall, the paper encourages the AI research community to think critically about the critique process itself, and to develop more robust and reliable methods for evaluating and improving the quality of research.
Technical Explanation
The paper begins by highlighting the importance of critique in the scientific process, particularly in the field of AI research and development. The authors argue that critique plays a crucial role in identifying weaknesses, biases, and areas for improvement in research, and that the quality of critique can have a significant impact on the overall progress of the field.
However, the authors also suggest that the current critique process may be flawed, with potential biases and limitations that can undermine its effectiveness. They explore three key aspects of the critique process: reference generation, AIU extraction, and meta-evaluation.
In the reference generation stage, the authors discuss the challenge of selecting appropriate comparison points or baselines, which can significantly influence the perceived quality of a research paper. They suggest that researchers may sometimes choose references that unfairly advantage their own work, a practice they call "reference gaming."
The AIU extraction stage involves the identification of key issues or "actionable improvement units" (AIUs) in a research paper. The authors argue that this process can be heavily influenced by the biases and perspectives of the reviewer, leading to inconsistencies and potential missed opportunities for improvement.
To address these concerns, the authors propose a framework they call "metacritique," which aims to make the critique process more rigorous, objective, and transparent. This includes strategies for meta-evaluation of critiques, as well as ways to qualitatively evaluate the impact of critiques on model improvement.
The paper also discusses the potential for causal evaluation of language models, which could provide deeper insights into the factors that drive model performance and the effectiveness of critique.
Critical Analysis
The paper raises valid concerns about the potential biases and limitations inherent in the current critique process within the AI research community. The authors' exploration of reference generation, AIU extraction, and meta-evaluation highlight important areas where subjectivity and bias can creep in, potentially undermining the objectivity and effectiveness of critique.
The proposed metacritique framework is an interesting and potentially valuable approach to addressing these issues. By focusing on improving the rigor, transparency, and objectivity of the critique process, the authors aim to make it a more reliable and impactful part of the research cycle.
However, it's important to note that the implementation of such a framework may face practical challenges. Developing robust and widely accepted methods for meta-evaluation and qualitative evaluation of critiques may require significant time and effort, and could face resistance from researchers who are accustomed to the current, more subjective, critique process.
Additionally, the paper does not delve deeply into the potential societal and ethical implications of improving the critique process. While the authors mention the importance of objectivity and transparency, there may be broader considerations around the role of critique in shaping the direction and priorities of AI research, and the potential impacts on different stakeholders.
Overall, the paper raises important and thought-provoking questions about the critique process in AI research, and provides a compelling framework for addressing its limitations. Further research and discussion within the community will be necessary to fully explore the practical and ethical implications of the authors' proposals.
Conclusion
This paper presents a critical examination of the critique process in AI research and development, highlighting the potential biases and limitations inherent in the current approach. The authors propose a metacritique framework as a means of improving the rigor, objectivity, and transparency of critique, with the goal of driving more effective and impactful research.
The ideas presented in this paper have the potential to significantly shape the future of critique in the AI field, encouraging researchers to think more deeply about the role of critique and how it can be leveraged to advance the state of the art more effectively. By addressing issues like reference generation, AIU extraction, and meta-evaluation, the authors aim to make the critique process a more reliable and valuable component of the research cycle.
As the field of AI continues to evolve, the insights and recommendations provided in this paper will likely become increasingly relevant, guiding the community towards more robust and rigorous methods of evaluating and improving upon existing research. The broader implications of this work, in terms of its impact on research priorities, ethical considerations, and societal outcomes, will be an important area of ongoing exploration and discussion.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
The Critique of Critique
Shichao Sun, Junlong Li, Weizhe Yuan, Ruifeng Yuan, Wenjie Li, Pengfei Liu
Critique, as a natural language description for assessing the quality of model-generated content, has played a vital role in the training, evaluation, and refinement of LLMs. However, a systematic method to evaluate the quality of critique is lacking. In this paper, we pioneer the critique of critique, termed MetaCritique, which builds specific quantification criteria. To achieve a reliable evaluation outcome, we propose Atomic Information Units (AIUs), which describe the critique in a more fine-grained manner. MetaCritique aggregates each AIU's judgment for the overall score. Moreover, MetaCritique delivers a natural language rationale for the intricate reasoning within each judgment. Lastly, we construct a meta-evaluation dataset covering 4 tasks across 16 public datasets involving human-written and LLM-generated critiques. Experiments demonstrate that MetaCritique can achieve near-human performance. Our study can facilitate future research in LLM critiques based on our following observations and released resources: (1) superior critiques judged by MetaCritique can lead to better refinements, indicating that it can potentially enhance the alignment of existing LLMs; (2) the leaderboard of critique models reveals that open-source critique models commonly suffer from factuality issues; (3) relevant code and data are publicly available at https://github.com/GAIR-NLP/MetaCritique to support deeper exploration; (4) an API at PyPI with the usage documentation in Appendix C allows users to assess the critique conveniently.
Read more6/4/2024
0
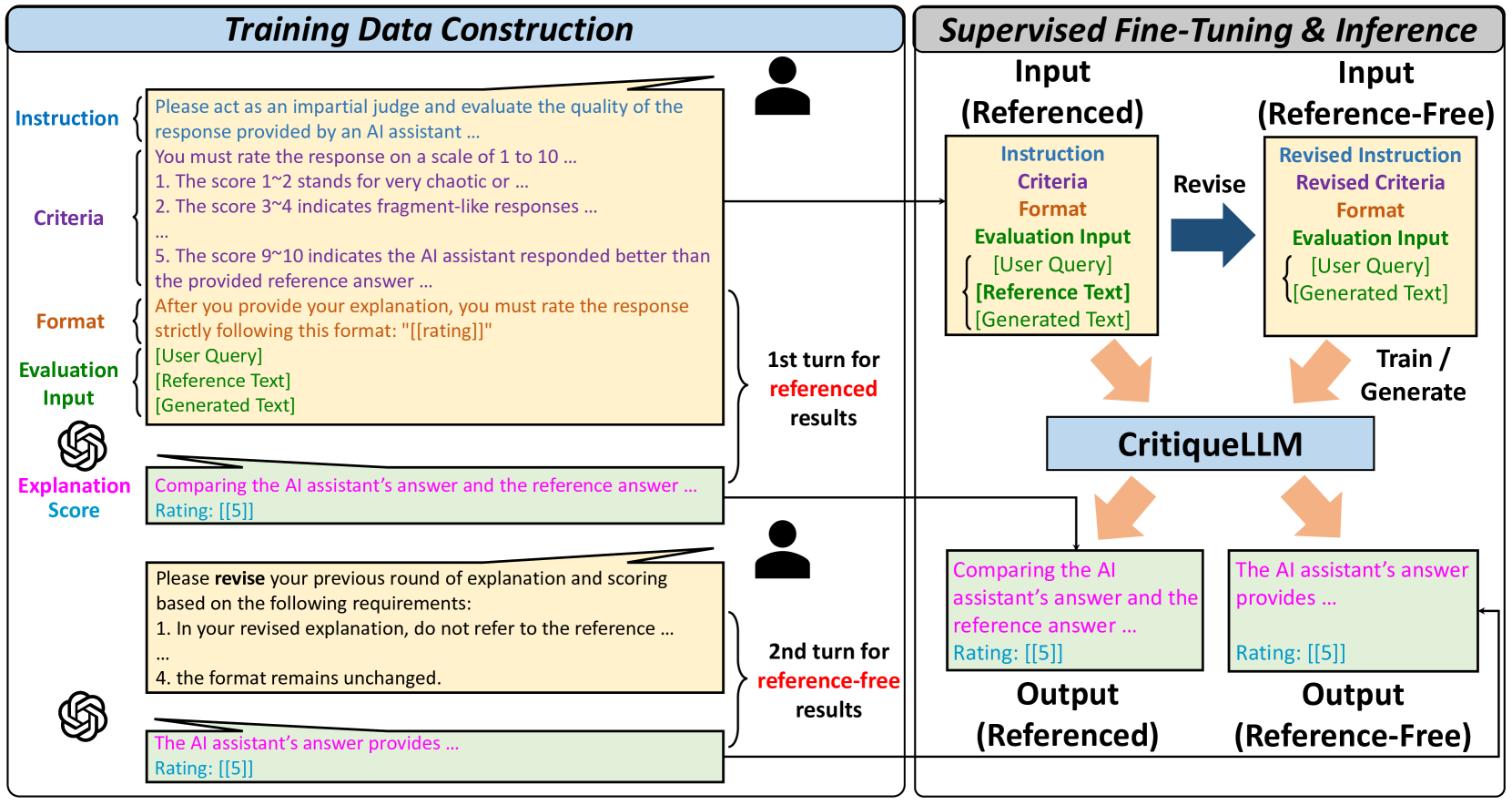
CritiqueLLM: Towards an Informative Critique Generation Model for Evaluation of Large Language Model Generation
Pei Ke, Bosi Wen, Zhuoer Feng, Xiao Liu, Xuanyu Lei, Jiale Cheng, Shengyuan Wang, Aohan Zeng, Yuxiao Dong, Hongning Wang, Jie Tang, Minlie Huang
Since the natural language processing (NLP) community started to make large language models (LLMs) act as a critic to evaluate the quality of generated texts, most of the existing works train a critique generation model on the evaluation data labeled by GPT-4's direct prompting. We observe that these models lack the ability to generate informative critiques in both pointwise grading and pairwise comparison especially without references. As a result, their generated critiques cannot provide fine-grained distinguishability on generated texts, causing unsatisfactory evaluation performance. In this paper, we propose a simple yet effective method called Eval-Instruct, which can first acquire pointwise grading critiques with pseudo references and then revise these critiques via multi-path prompting to obtain informative evaluation data in different tasks and settings, including pointwise grading and pairwise comparison with / without references. After fine-tuning on these data, the resulting model CritiqueLLM is empirically shown to outperform ChatGPT and all the open-source baselines and even achieve comparable evaluation performance to GPT-4 in system-level correlations of pointwise grading. We also demonstrate that our generated critiques can act as scalable feedback to further improve the generation quality of strong LLMs like ChatGPT.
Read more6/27/2024
0
CriticEval: Evaluating Large Language Model as Critic
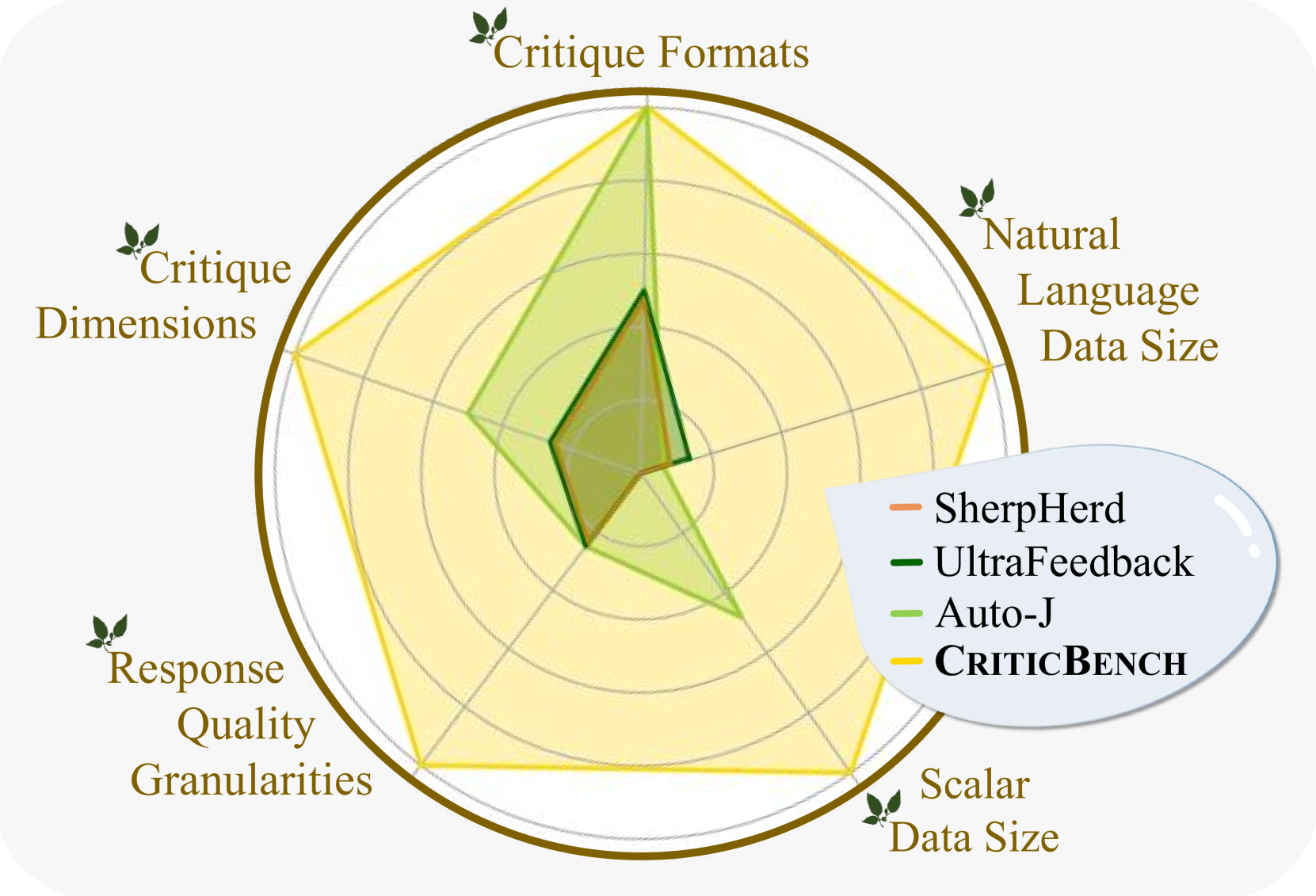
Tian Lan, Wenwei Zhang, Chen Xu, Heyan Huang, Dahua Lin, Kai Chen, Xian-ling Mao
Critique ability, i.e., the capability of Large Language Models (LLMs) to identify and rectify flaws in responses, is crucial for their applications in self-improvement and scalable oversight. While numerous studies have been proposed to evaluate critique ability of LLMs, their comprehensiveness and reliability are still limited. To overcome this problem, we introduce CriticEval, a novel benchmark designed to comprehensively and reliably evaluate critique ability of LLMs. Specifically, to ensure the comprehensiveness, CriticEval evaluates critique ability from four dimensions across nine diverse task scenarios. It evaluates both scalar-valued and textual critiques, targeting responses of varying quality. To ensure the reliability, a large number of critiques are annotated to serve as references, enabling GPT-4 to evaluate textual critiques reliably. Extensive evaluations of open-source and closed-source LLMs first validate the reliability of evaluation in CriticEval. Then, experimental results demonstrate the promising potential of open-source LLMs, the effectiveness of critique datasets and several intriguing relationships between the critique ability and some critical factors, including task types, response qualities and critique dimensions. Datasets and evaluation toolkit for CriticEval will be publicly released.
Read more9/12/2024

0
CriticBench: Benchmarking LLMs for Critique-Correct Reasoning
Zicheng Lin, Zhibin Gou, Tian Liang, Ruilin Luo, Haowei Liu, Yujiu Yang
The ability of Large Language Models (LLMs) to critique and refine their reasoning is crucial for their application in evaluation, feedback provision, and self-improvement. This paper introduces CriticBench, a comprehensive benchmark designed to assess LLMs' abilities to critique and rectify their reasoning across a variety of tasks. CriticBench encompasses five reasoning domains: mathematical, commonsense, symbolic, coding, and algorithmic. It compiles 15 datasets and incorporates responses from three LLM families. Utilizing CriticBench, we evaluate and dissect the performance of 17 LLMs in generation, critique, and correction reasoning, i.e., GQC reasoning. Our findings reveal: (1) a linear relationship in GQC capabilities, with critique-focused training markedly enhancing performance; (2) a task-dependent variation in correction effectiveness, with logic-oriented tasks being more amenable to correction; (3) GQC knowledge inconsistencies that decrease as model size increases; and (4) an intriguing inter-model critiquing dynamic, where stronger models are better at critiquing weaker ones, while weaker models can surprisingly surpass stronger ones in their self-critique. We hope these insights into the nuanced critique-correct reasoning of LLMs will foster further research in LLM critique and self-improvement.
Read more6/4/2024