Argument Mining in Data Scarce Settings: Cross-lingual Transfer and Few-shot Techniques

0
Sign in to get full access
Overview
- Explores techniques for argument mining in data-scarce settings, including cross-lingual transfer and few-shot learning.
- Investigates how to leverage limited data and language resources to build effective argument mining models.
- Proposes novel approaches to address the challenges of argument mining in low-resource scenarios.
Plain English Explanation
Argument mining is the process of automatically identifying and extracting arguments from text. This is a valuable task for understanding debates, analyzing opinions, and summarizing complex discussions. However, building effective argument mining models often requires large datasets, which can be challenging to obtain, especially for less-resourced languages or specialized domains.
This research paper explores ways to overcome these challenges by investigating cross-lingual transfer and few-shot learning techniques for argument mining. The key idea is to leverage limited data and language resources to build models that can still perform well, even in data-scarce settings.
The researchers propose novel approaches that combine cross-lingual transfer, where models trained on one language are used to analyze text in another language, with few-shot learning, where models can be quickly adapted to new tasks or domains using only a small amount of training data. By combining these techniques, the researchers aim to enable effective argument mining in a wide range of scenarios, from low-resource languages to specialized domains with limited data.
Technical Explanation
The paper begins by reviewing the relevant literature on argument mining, cross-lingual transfer, and few-shot learning. The researchers then present their proposed approaches, which involve:
-
Cross-lingual Transfer: The researchers explore different ways to leverage models trained on high-resource languages, such as English, to perform argument mining on low-resource languages. This includes techniques like multilingual model fine-tuning and cross-lingual parameter initialization.
-
Few-shot Learning: To address data scarcity, the researchers investigate few-shot learning techniques that can effectively train argument mining models using only a small amount of labeled data. This includes meta-learning approaches and data augmentation strategies.
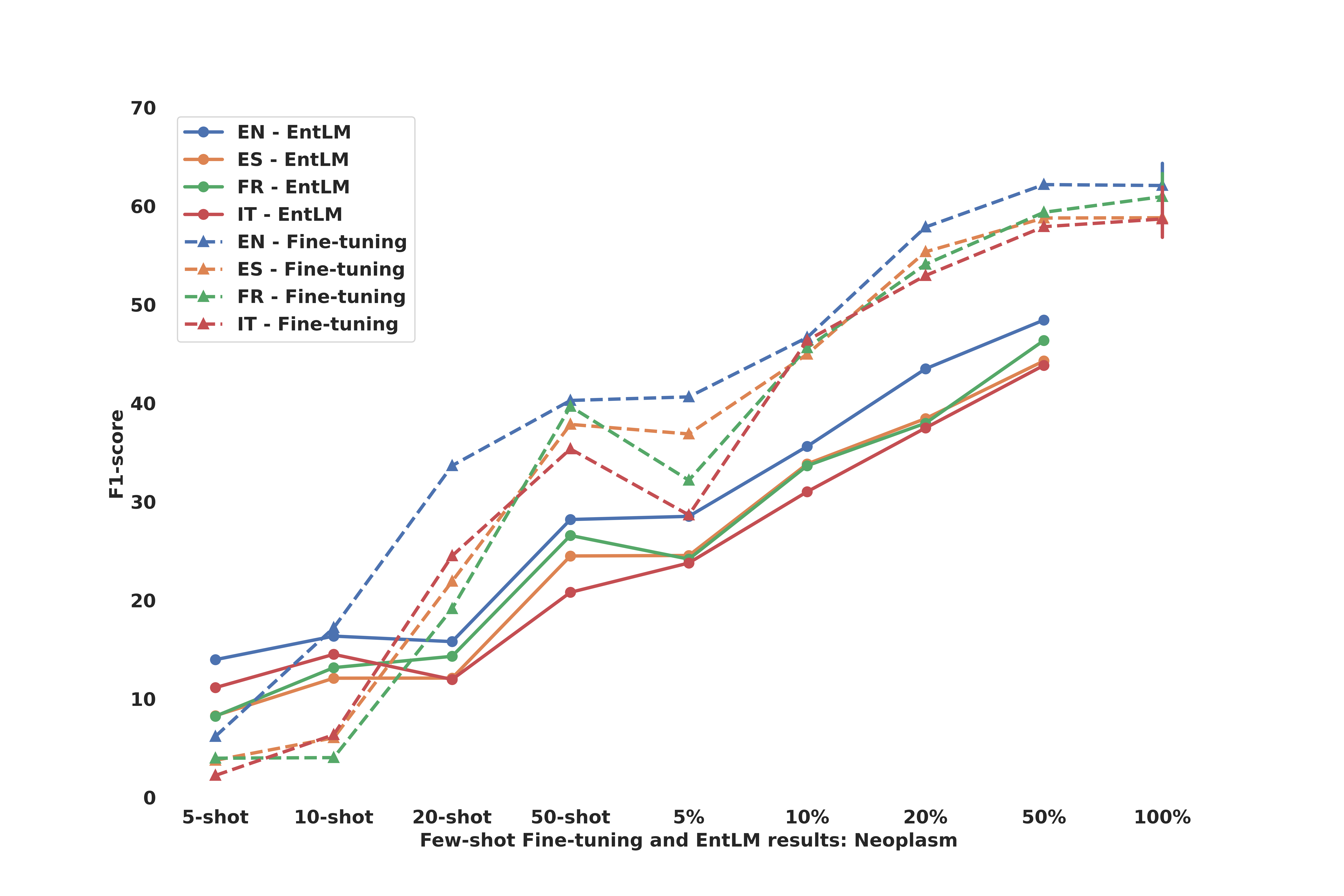
The researchers evaluate their proposed methods on several benchmark datasets, including argument mining tasks in English, German, and Turkish. The results demonstrate the effectiveness of their cross-lingual and few-shot techniques, which outperform traditional approaches in data-scarce settings.
Critical Analysis
The researchers provide a thorough analysis of the limitations and potential issues with their approaches. For example, they acknowledge that the performance of cross-lingual transfer can be sensitive to the linguistic and cultural differences between the source and target languages, and that the effectiveness of few-shot learning may depend on the specific characteristics of the task and dataset.
Additionally, the researchers note that their experiments were conducted on relatively small-scale datasets, and further validation on larger, more diverse corpora would be valuable to fully assess the generalizability of their techniques.
Overall, the paper presents a well-designed and thoughtful investigation of important challenges in argument mining, with promising results that could have significant implications for the development of argument mining systems in low-resource settings.
Conclusion
This research paper makes important contributions to the field of argument mining by exploring effective techniques for addressing the challenges of data scarcity. The proposed approaches leveraging cross-lingual transfer and few-shot learning demonstrate the potential to enable robust argument mining models even when limited data and language resources are available.
The insights and methods presented in this work could have far-reaching impacts, allowing for the development of argument mining systems that can be deployed in a wide range of real-world scenarios, from low-resource languages to specialized domains. This could greatly enhance our ability to understand and analyze complex debates, opinions, and discussions, with applications in areas such as policy-making, education, and social discourse analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Argument Mining in Data Scarce Settings: Cross-lingual Transfer and Few-shot Techniques
Anar Yeginbergen, Maite Oronoz, Rodrigo Agerri
Recent research on sequence labelling has been exploring different strategies to mitigate the lack of manually annotated data for the large majority of the world languages. Among others, the most successful approaches have been based on (i) the cross-lingual transfer capabilities of multilingual pre-trained language models (model-transfer), (ii) data translation and label projection (data-transfer) and (iii), prompt-based learning by reusing the mask objective to exploit the few-shot capabilities of pre-trained language models (few-shot). Previous work seems to conclude that model-transfer outperforms data-transfer methods and that few-shot techniques based on prompting are superior to updating the model's weights via fine-tuning. In this paper, we empirically demonstrate that, for Argument Mining, a sequence labelling task which requires the detection of long and complex discourse structures, previous insights on cross-lingual transfer or few-shot learning do not apply. Contrary to previous work, we show that for Argument Mining data transfer obtains better results than model-transfer and that fine-tuning outperforms few-shot methods. Regarding the former, the domain of the dataset used for data-transfer seems to be a deciding factor, while, for few-shot, the type of task (length and complexity of the sequence spans) and sampling method prove to be crucial.
Read more7/8/2024
🌿
0
Cross-lingual Argument Mining in the Medical Domain
Anar Yeginbergen, Rodrigo Agerri
Nowadays the medical domain is receiving more and more attention in applications involving Artificial Intelligence as clinicians decision-making is increasingly dependent on dealing with enormous amounts of unstructured textual data. In this context, Argument Mining (AM) helps to meaningfully structure textual data by identifying the argumentative components in the text and classifying the relations between them. However, as it is the case for man tasks in Natural Language Processing in general and in medical text processing in particular, the large majority of the work on computational argumentation has been focusing only on the English language. In this paper, we investigate several strategies to perform AM in medical texts for a language such as Spanish, for which no annotated data is available. Our work shows that automatically translating and projecting annotations (data-transfer) from English to a given target language is an effective way to generate annotated data without costly manual intervention. Furthermore, and contrary to conclusions from previous work for other sequence labelling tasks, our experiments demonstrate that data-transfer outperforms methods based on the crosslingual transfer capabilities of multilingual pre-trained language models (model-transfer). Finally, we show how the automatically generated data in Spanish can also be used to improve results in the original English monolingual setting, providing thus a fully automatic data augmentation strategy.
Read more7/25/2024
💬
0
Low-Resource Cross-Lingual Summarization through Few-Shot Learning with Large Language Models
Gyutae Park, Seojin Hwang, Hwanhee Lee
Cross-lingual summarization (XLS) aims to generate a summary in a target language different from the source language document. While large language models (LLMs) have shown promising zero-shot XLS performance, their few-shot capabilities on this task remain unexplored, especially for low-resource languages with limited parallel data. In this paper, we investigate the few-shot XLS performance of various models, including Mistral-7B-Instruct-v0.2, GPT-3.5, and GPT-4. Our experiments demonstrate that few-shot learning significantly improves the XLS performance of LLMs, particularly GPT-3.5 and GPT-4, in low-resource settings. However, the open-source model Mistral-7B-Instruct-v0.2 struggles to adapt effectively to the XLS task with limited examples. Our findings highlight the potential of few-shot learning for improving XLS performance and the need for further research in designing LLM architectures and pre-training objectives tailored for this task. We provide a future work direction to explore more effective few-shot learning strategies and to investigate the transfer learning capabilities of LLMs for cross-lingual summarization.
Read more6/10/2024

0
Boosting Zero-Shot Crosslingual Performance using LLM-Based Augmentations with Effective Data Selection
Barah Fazili, Ashish Sunil Agrawal, Preethi Jyothi
Large language models (LLMs) are very proficient text generators. We leverage this capability of LLMs to generate task-specific data via zero-shot prompting and promote cross-lingual transfer for low-resource target languages. Given task-specific data in a source language and a teacher model trained on this data, we propose using this teacher to label LLM generations and employ a set of simple data selection strategies that use the teacher's label probabilities. Our data selection strategies help us identify a representative subset of diverse generations that help boost zero-shot accuracies while being efficient, in comparison to using all the LLM generations (without any subset selection). We also highlight other important design choices that affect cross-lingual performance such as the use of translations of source data and what labels are best to use for the LLM generations. We observe significant performance gains across sentiment analysis and natural language inference tasks (of up to a maximum of 7.13 absolute points and 1.5 absolute points on average) across a number of target languages (Hindi, Marathi, Urdu, Swahili) and domains.
Read more7/16/2024