Cross-Silo Federated Learning for Multi-Tier Networks with Vertical and Horizontal Data Partitioning
2108.08930
0
0
📊
Abstract
We consider federated learning in tiered communication networks. Our network model consists of a set of silos, each holding a vertical partition of the data. Each silo contains a hub and a set of clients, with the silo's vertical data shard partitioned horizontally across its clients. We propose Tiered Decentralized Coordinate Descent (TDCD), a communication-efficient decentralized training algorithm for such two-tiered networks. The clients in each silo perform multiple local gradient steps before sharing updates with their hub to reduce communication overhead. Each hub adjusts its coordinates by averaging its workers' updates, and then hubs exchange intermediate updates with one another. We present a theoretical analysis of our algorithm and show the dependence of the convergence rate on the number of vertical partitions and the number of local updates. We further validate our approach empirically via simulation-based experiments using a variety of datasets and objectives.
Create account to get full access
Overview
- Federated learning in tiered communication networks
- Two-tiered network model with silos, hubs, and clients
- Propose Tiered Decentralized Coordinate Descent (TDCD) algorithm for efficient decentralized training
- Clients perform local updates, hubs average updates and exchange with other hubs
- Theoretical analysis and empirical validation through simulations
Plain English Explanation
The paper explores a type of federated learning in communication networks with a hierarchical structure. The network is divided into "silos", each containing a central "hub" and a set of "clients" that hold partitions of the overall data. The clients perform multiple local update steps before sharing their updates with the hub. The hubs then average these updates and exchange them with other hubs, allowing the model to be trained in a decentralized manner.
This "tiered" approach aims to reduce the overall communication required, as the clients only need to share updates with their local hub, rather than directly with a central server. The researchers, Tiered Decentralized Coordinate Descent (TDCD), and analyze how the convergence rate is affected by factors like the number of silos and the number of local updates performed by clients.
Technical Explanation
The proposed network model consists of a set of "silos", each holding a vertical partition of the data. Each silo contains a "hub" and a set of "clients", with the silo's data shard partitioned horizontally across its clients. The researchers introduce the Tiered Decentralized Coordinate Descent (TDCD) algorithm, which allows for efficient decentralized training in this two-tiered network structure.
In TDCD, the clients in each silo perform multiple local gradient steps before sharing updates with their hub. Each hub then adjusts its coordinates by averaging its workers' updates, and the hubs exchange these intermediate updates with one another. The researchers present a theoretical analysis of their algorithm, showing how the convergence rate depends on the number of vertical partitions and the number of local updates performed.
The authors validate their approach through simulation-based experiments using a variety of datasets and objectives, demonstrating the effectiveness of their communication-efficient hybrid federated learning approach.
Critical Analysis
The paper provides a detailed theoretical analysis of the TDCD algorithm and its performance characteristics, which is a strength of the work. However, the simulations are limited to relatively small-scale experiments, and the authors acknowledge that further research is needed to understand the performance of their approach in real-world, large-scale federated learning settings.
Additionally, the paper does not explore the impact of factors like client heterogeneity, data distribution, or the presence of malicious or unreliable clients, which are common challenges in federated learning scenarios. Investigating the robustness of TDCD to these issues would be an important area for future research.
Conclusion
The paper presents a novel approach, Tiered Decentralized Coordinate Descent (TDCD), for efficient decentralized training in tiered communication networks. The key innovation is the hierarchical structure, which allows clients to perform local updates before communicating with their hubs, reducing the overall communication overhead. The theoretical analysis and simulation results demonstrate the potential of this approach, but further research is needed to understand its performance in more realistic and challenging federated learning scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
Cross-Silo Federated Learning Across Divergent Domains with Iterative Parameter Alignment
Matt Gorbett, Hossein Shirazi, Indrakshi Ray
0
0
Learning from the collective knowledge of data dispersed across private sources can provide neural networks with enhanced generalization capabilities. Federated learning, a method for collaboratively training a machine learning model across remote clients, achieves this by combining client models via the orchestration of a central server. However, current approaches face two critical limitations: i) they struggle to converge when client domains are sufficiently different, and ii) current aggregation techniques produce an identical global model for each client. In this work, we address these issues by reformulating the typical federated learning setup: rather than learning a single global model, we learn N models each optimized for a common objective. To achieve this, we apply a weighted distance minimization to model parameters shared in a peer-to-peer topology. The resulting framework, Iterative Parameter Alignment, applies naturally to the cross-silo setting, and has the following properties: (i) a unique solution for each participant, with the option to globally converge each model in the federation, and (ii) an optional early-stopping mechanism to elicit fairness among peers in collaborative learning settings. These characteristics jointly provide a flexible new framework for iteratively learning from peer models trained on disparate datasets. We find that the technique achieves competitive results on a variety of data partitions compared to state-of-the-art approaches. Further, we show that the method is robust to divergent domains (i.e. disjoint classes across peers) where existing approaches struggle.
5/20/2024
📊
Communication-Efficient Hybrid Federated Learning for E-health with Horizontal and Vertical Data Partitioning
Chong Yu, Shuaiqi Shen, Shiqiang Wang, Kuan Zhang, Hai Zhao
0
0
E-health allows smart devices and medical institutions to collaboratively collect patients' data, which is trained by Artificial Intelligence (AI) technologies to help doctors make diagnosis. By allowing multiple devices to train models collaboratively, federated learning is a promising solution to address the communication and privacy issues in e-health. However, applying federated learning in e-health faces many challenges. First, medical data is both horizontally and vertically partitioned. Since single Horizontal Federated Learning (HFL) or Vertical Federated Learning (VFL) techniques cannot deal with both types of data partitioning, directly applying them may consume excessive communication cost due to transmitting a part of raw data when requiring high modeling accuracy. Second, a naive combination of HFL and VFL has limitations including low training efficiency, unsound convergence analysis, and lack of parameter tuning strategies. In this paper, we provide a thorough study on an effective integration of HFL and VFL, to achieve communication efficiency and overcome the above limitations when data is both horizontally and vertically partitioned. Specifically, we propose a hybrid federated learning framework with one intermediate result exchange and two aggregation phases. Based on this framework, we develop a Hybrid Stochastic Gradient Descent (HSGD) algorithm to train models. Then, we theoretically analyze the convergence upper bound of the proposed algorithm. Using the convergence results, we design adaptive strategies to adjust the training parameters and shrink the size of transmitted data. Experimental results validate that the proposed HSGD algorithm can achieve the desired accuracy while reducing communication cost, and they also verify the effectiveness of the adaptive strategies.
4/17/2024

Architectural Blueprint For Heterogeneity-Resilient Federated Learning
Satwat Bashir, Tasos Dagiuklas, Kasra Kassai, Muddesar Iqbal
0
0
This paper proposes a novel three tier architecture for federated learning to optimize edge computing environments. The proposed architecture addresses the challenges associated with client data heterogeneity and computational constraints. It introduces a scalable, privacy preserving framework that enhances the efficiency of distributed machine learning. Through experimentation, the paper demonstrates the architecture capability to manage non IID data sets more effectively than traditional federated learning models. Additionally, the paper highlights the potential of this innovative approach to significantly improve model accuracy, reduce communication overhead, and facilitate broader adoption of federated learning technologies.
6/17/2024
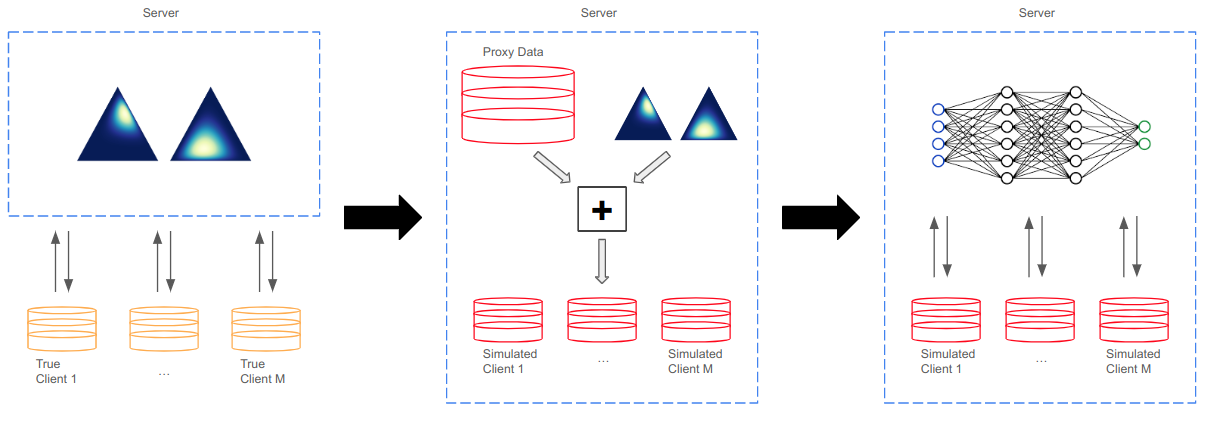
Improved Modelling of Federated Datasets using Mixtures-of-Dirichlet-Multinomials
Jonathan Scott, 'Aine Cahill
0
0
In practice, training using federated learning can be orders of magnitude slower than standard centralized training. This severely limits the amount of experimentation and tuning that can be done, making it challenging to obtain good performance on a given task. Server-side proxy data can be used to run training simulations, for instance for hyperparameter tuning. This can greatly speed up the training pipeline by reducing the number of tuning runs to be performed overall on the true clients. However, it is challenging to ensure that these simulations accurately reflect the dynamics of the real federated training. In particular, the proxy data used for simulations often comes as a single centralized dataset without a partition into distinct clients, and partitioning this data in a naive way can lead to simulations that poorly reflect real federated training. In this paper we address the challenge of how to partition centralized data in a way that reflects the statistical heterogeneity of the true federated clients. We propose a fully federated, theoretically justified, algorithm that efficiently learns the distribution of the true clients and observe improved server-side simulations when using the inferred distribution to create simulated clients from the centralized data.
6/5/2024