MathBench: Evaluating the Theory and Application Proficiency of LLMs with a Hierarchical Mathematics Benchmark
2405.12209
0
0

Abstract
Recent advancements in large language models (LLMs) have showcased significant improvements in mathematics. However, traditional math benchmarks like GSM8k offer a unidimensional perspective, falling short in providing a holistic assessment of the LLMs' math capabilities. To address this gap, we introduce MathBench, a new benchmark that rigorously assesses the mathematical capabilities of large language models. MathBench spans a wide range of mathematical disciplines, offering a detailed evaluation of both theoretical understanding and practical problem-solving skills. The benchmark progresses through five distinct stages, from basic arithmetic to college mathematics, and is structured to evaluate models at various depths of knowledge. Each stage includes theoretical questions and application problems, allowing us to measure a model's mathematical proficiency and its ability to apply concepts in practical scenarios. MathBench aims to enhance the evaluation of LLMs' mathematical abilities, providing a nuanced view of their knowledge understanding levels and problem solving skills in a bilingual context. The project is released at https://github.com/open-compass/MathBench .
Create account to get full access
Overview
• This paper introduces MathBench, a hierarchical mathematics benchmark designed to evaluate the theory and application proficiency of large language models (LLMs).
• MathBench covers a range of mathematical concepts and tasks, from basic arithmetic to advanced problem-solving, with the goal of providing a comprehensive assessment of an LLM's mathematical capabilities.
• The benchmark includes both theoretical and applied components, allowing for a more holistic evaluation of an LLM's understanding and problem-solving abilities in the domain of mathematics.
Plain English Explanation
The paper describes a new tool called MathBench that is designed to test how well large language models (LLMs) understand and apply mathematical concepts. LLMs are AI systems that can process and generate human-like text, and they have become increasingly capable at a wide range of tasks.
However, the authors of this paper recognized that it can be challenging to assess an LLM's true mathematical proficiency. MathBench aims to provide a more thorough and structured way to evaluate an LLM's skills in both theory and application of mathematics.
The benchmark covers a hierarchy of mathematical topics, from basic arithmetic to more advanced problem-solving. This allows for a comprehensive assessment of an LLM's mathematical capabilities, including its understanding of fundamental concepts as well as its ability to apply that knowledge to solve complex problems.
By including both theoretical and applied components, MathBench provides a more well-rounded picture of an LLM's mathematical proficiency. This could be useful for researchers and developers who want to better understand the mathematical capabilities of their LLMs, or for those looking to compare the performance of different LLMs in this domain.
Technical Explanation
The paper introduces MathBench, a hierarchical mathematics benchmark designed to evaluate the theory and application proficiency of large language models (LLMs). The benchmark covers a range of mathematical concepts and tasks, from basic arithmetic to advanced problem-solving, organized into a hierarchical structure.
The key elements of MathBench include:
-
Hierarchical Structure: The benchmark is organized into a hierarchy of mathematical topics, allowing for a more granular assessment of an LLM's capabilities across different levels of complexity.
-
Theoretical and Applied Components: MathBench includes both theoretical and applied components, testing an LLM's understanding of mathematical concepts as well as its ability to apply that knowledge to solve problems.
-
Comprehensive Coverage: The benchmark covers a wide range of mathematical topics, from elementary arithmetic to more advanced areas like calculus, linear algebra, and combinatorics.
The authors demonstrate the use of MathBench by evaluating the performance of several state-of-the-art LLMs on the benchmark, providing insights into their mathematical proficiency and highlighting areas for potential improvement.
The findings from this research could inform the development of more mathematically capable LLMs, as well as the design of better benchmarks and evaluation tools for assessing the mathematical abilities of these models.
Critical Analysis
The authors acknowledge several limitations and areas for further research in their paper. For example, they note that MathBench currently focuses on textual representations of mathematical concepts and problems, and may not fully capture the capabilities of multimodal LLMs that can leverage visual or interactive elements.
Additionally, the authors suggest that future work could explore the use of psychometric techniques to further refine the benchmark and make it more robust for evaluating the mathematical proficiency of LLMs.
One potential concern that could be raised is the representativeness of the mathematical tasks and concepts included in MathBench. While the authors strive for comprehensive coverage, there may be gaps or biases in the selection of topics that could limit the generalizability of the benchmark's findings.
Furthermore, the paper does not provide a detailed analysis of the computational and resource requirements for running the MathBench evaluation, which could be an important consideration for researchers and developers with limited computational resources.
Conclusion
The MathBench benchmark introduced in this paper represents a significant step forward in the evaluation of large language models' mathematical capabilities. By providing a hierarchical, theory-and-application-focused assessment, the authors aim to offer a more comprehensive and nuanced understanding of an LLM's mathematical proficiency.
The findings from this research could inform the development of more mathematically capable LLMs that can better support a wide range of applications, from scientific computing to educational tools. As the field of language models continues to advance, benchmarks like MathBench will play a crucial role in ensuring these powerful AI systems are able to effectively reason about and apply mathematical concepts.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

PATCH -- Psychometrics-AssisTed benCHmarking of Large Language Models: A Case Study of Mathematics Proficiency
Qixiang Fang, Daniel L. Oberski, Dong Nguyen
0
0
Many existing benchmarks of large (multimodal) language models (LLMs) focus on measuring LLMs' academic proficiency, often with also an interest in comparing model performance with human test takers. While these benchmarks have proven key to the development of LLMs, they suffer from several limitations, including questionable measurement quality (e.g., Do they measure what they are supposed to in a reliable way?), lack of quality assessment on the item level (e.g., Are some items more important or difficult than others?) and unclear human population reference (e.g., To whom can the model be compared?). In response to these challenges, we propose leveraging knowledge from psychometrics - a field dedicated to the measurement of latent variables like academic proficiency - into LLM benchmarking. We make three primary contributions. First, we introduce PATCH: a novel framework for Psychometrics-AssisTed benCHmarking of LLMs. PATCH addresses the aforementioned limitations, presenting a new direction for LLM benchmark research. Second, we implement PATCH by measuring GPT-4 and Gemini-Pro-Vision's proficiency in 8th grade mathematics against 56 human populations. We show that adopting a psychometrics-based approach yields evaluation outcomes that diverge from those based on existing benchmarking practices. Third, we release 4 datasets to support measuring and comparing LLM proficiency in grade school mathematics and science against human populations.
4/3/2024
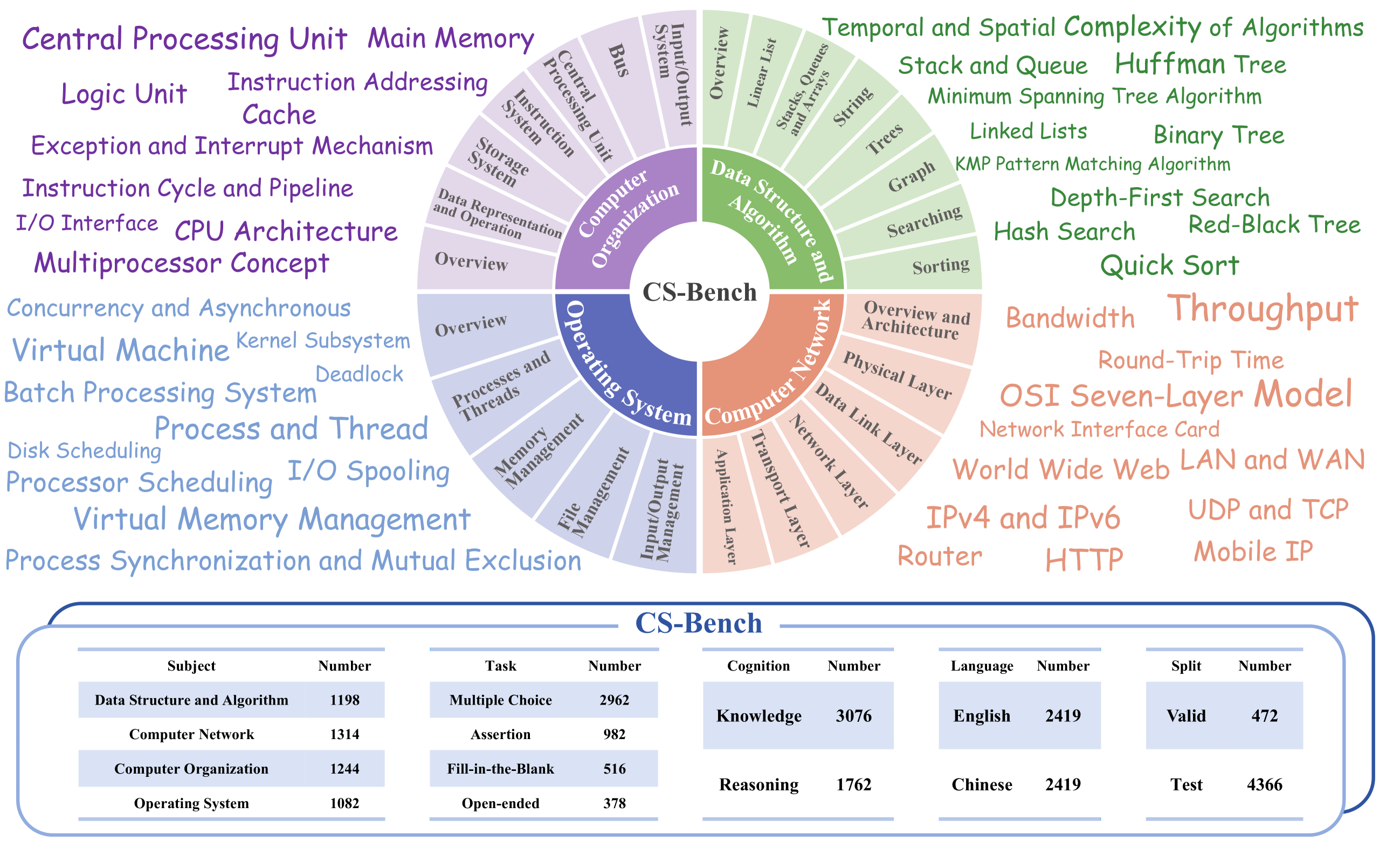
CS-Bench: A Comprehensive Benchmark for Large Language Models towards Computer Science Mastery
Xiaoshuai Song, Muxi Diao, Guanting Dong, Zhengyang Wang, Yujia Fu, Runqi Qiao, Zhexu Wang, Dayuan Fu, Huangxuan Wu, Bin Liang, Weihao Zeng, Yejie Wang, Zhuoma GongQue, Jianing Yu, Qiuna Tan, Weiran Xu
0
0
Computer Science (CS) stands as a testament to the intricacies of human intelligence, profoundly advancing the development of artificial intelligence and modern society. However, the current community of large language models (LLMs) overly focuses on benchmarks for analyzing specific foundational skills (e.g. mathematics and code generation), neglecting an all-round evaluation of the computer science field. To bridge this gap, we introduce CS-Bench, the first bilingual (Chinese-English) benchmark dedicated to evaluating the performance of LLMs in computer science. CS-Bench comprises approximately 5K meticulously curated test samples, covering 26 subfields across 4 key areas of computer science, encompassing various task forms and divisions of knowledge and reasoning. Utilizing CS-Bench, we conduct a comprehensive evaluation of over 30 mainstream LLMs, revealing the relationship between CS performance and model scales. We also quantitatively analyze the reasons for failures in existing LLMs and highlight directions for improvements, including knowledge supplementation and CS-specific reasoning. Further cross-capability experiments show a high correlation between LLMs' capabilities in computer science and their abilities in mathematics and coding. Moreover, expert LLMs specialized in mathematics and coding also demonstrate strong performances in several CS subfields. Looking ahead, we envision CS-Bench serving as a cornerstone for LLM applications in the CS field and paving new avenues in assessing LLMs' diverse reasoning capabilities. The CS-Bench data and evaluation code are available at https://github.com/csbench/csbench.
6/14/2024
💬
New!SciBench: Evaluating College-Level Scientific Problem-Solving Abilities of Large Language Models
Xiaoxuan Wang, Ziniu Hu, Pan Lu, Yanqiao Zhu, Jieyu Zhang, Satyen Subramaniam, Arjun R. Loomba, Shichang Zhang, Yizhou Sun, Wei Wang
0
0
Most of the existing Large Language Model (LLM) benchmarks on scientific problem reasoning focus on problems grounded in high-school subjects and are confined to elementary algebraic operations. To systematically examine the reasoning capabilities required for solving complex scientific problems, we introduce an expansive benchmark suite SciBench for LLMs. SciBench contains a carefully curated dataset featuring a range of collegiate-level scientific problems from mathematics, chemistry, and physics domains. Based on the dataset, we conduct an in-depth benchmarking study of representative open-source and proprietary LLMs with various prompting strategies. The results reveal that the current LLMs fall short of delivering satisfactory performance, with the best overall score of merely 43.22%. Furthermore, through a detailed user study, we categorize the errors made by LLMs into ten problem-solving abilities. Our analysis indicates that no single prompting strategy significantly outperforms the others and some strategies that demonstrate improvements in certain problem-solving skills could result in declines in other skills. We envision that SciBench will catalyze further developments in the reasoning abilities of LLMs, thereby ultimately contributing to scientific research and discovery.
7/1/2024

LLMs Are Not Intelligent Thinkers: Introducing Mathematical Topic Tree Benchmark for Comprehensive Evaluation of LLMs
Arash Gholami Davoodi, Seyed Pouyan Mousavi Davoudi, Pouya Pezeshkpour
0
0
Large language models (LLMs) demonstrate impressive capabilities in mathematical reasoning. However, despite these achievements, current evaluations are mostly limited to specific mathematical topics, and it remains unclear whether LLMs are genuinely engaging in reasoning. To address these gaps, we present the Mathematical Topics Tree (MaTT) benchmark, a challenging and structured benchmark that offers 1,958 questions across a wide array of mathematical subjects, each paired with a detailed hierarchical chain of topics. Upon assessing different LLMs using the MaTT benchmark, we find that the most advanced model, GPT-4, achieved a mere 54% accuracy in a multiple-choice scenario. Interestingly, even when employing Chain-of-Thought prompting, we observe mostly no notable improvement. Moreover, LLMs accuracy dramatically reduced by up to 24.2 percentage point when the questions were presented without providing choices. Further detailed analysis of the LLMs' performance across a range of topics showed significant discrepancy even for closely related subtopics within the same general mathematical area. In an effort to pinpoint the reasons behind LLMs performances, we conducted a manual evaluation of the completeness and correctness of the explanations generated by GPT-4 when choices were available. Surprisingly, we find that in only 53.3% of the instances where the model provided a correct answer, the accompanying explanations were deemed complete and accurate, i.e., the model engaged in genuine reasoning.
6/11/2024