C$^{3}$Bench: A Comprehensive Classical Chinese Understanding Benchmark for Large Language Models
2405.17732
0
0

Abstract
Classical Chinese Understanding (CCU) holds significant value in preserving and exploration of the outstanding traditional Chinese culture. Recently, researchers have attempted to leverage the potential of Large Language Models (LLMs) for CCU by capitalizing on their remarkable comprehension and semantic capabilities. However, no comprehensive benchmark is available to assess the CCU capabilities of LLMs. To fill this gap, this paper introduces C$^{3}$bench, a Comprehensive Classical Chinese understanding benchmark, which comprises 50,000 text pairs for five primary CCU tasks, including classification, retrieval, named entity recognition, punctuation, and translation. Furthermore, the data in C$^{3}$bench originates from ten different domains, covering most of the categories in classical Chinese. Leveraging the proposed C$^{3}$bench, we extensively evaluate the quantitative performance of 15 representative LLMs on all five CCU tasks. Our results not only establish a public leaderboard of LLMs' CCU capabilities but also gain some findings. Specifically, existing LLMs are struggle with CCU tasks and still inferior to supervised models. Additionally, the results indicate that CCU is a task that requires special attention. We believe this study could provide a standard benchmark, comprehensive baselines, and valuable insights for the future advancement of LLM-based CCU research. The evaluation pipeline and dataset are available at url{https://github.com/SCUT-DLVCLab/C3bench}.
Create account to get full access
Overview
- This paper introduces C3Bench, a comprehensive benchmark for evaluating the performance of large language models on understanding classical Chinese text.
- The benchmark covers a wide range of tasks such as translation, question answering, and text summarization, allowing for a thorough assessment of a model's capabilities.
- The authors provide detailed descriptions of the benchmark's design, the datasets used, and the evaluation metrics employed.
Plain English Explanation
The researchers have created a new benchmark called C3Bench to test how well large language models can understand classical Chinese texts. Classical Chinese is an ancient form of the language that is quite different from modern Chinese, so it can be challenging for language models to grasp.
The C3Bench covers many different tasks, like translating classical Chinese into modern Chinese, answering questions about the content of classical texts, and summarizing the key points of classical writings. By testing models on this diverse set of tasks, the researchers can get a comprehensive picture of how well the models truly understand classical Chinese, rather than just recognizing a few common patterns.
The paper goes into great detail about how the benchmark was designed and the specific datasets and evaluation methods that were used. This rigorous approach ensures the benchmark provides reliable and meaningful insights into a model's classical Chinese understanding capabilities.
Technical Explanation
The C3Bench is a new benchmark developed by the authors to comprehensively evaluate the performance of large language models on classical Chinese understanding tasks. The benchmark covers a wide range of sub-tasks, including classical Chinese to modern Chinese translation, question answering on classical texts, classical text summarization, logical reasoning, and more.
The authors carefully curated datasets for each task, drawn from historical Chinese literature, philosophical works, and other classical sources. They also developed evaluation metrics tailored to each sub-task to provide a comprehensive and rigorous assessment of model performance.
The benchmark is designed to go beyond simple surface-level pattern matching, and instead evaluate a model's deeper understanding of classical Chinese language and concepts. This allows for a more nuanced assessment of a model's capabilities compared to prior Chinese language benchmarks like CFLUE.
Critical Analysis
The C3Bench represents an important advance in benchmarking the classical Chinese understanding capabilities of large language models. By covering a diverse set of sub-tasks, the benchmark provides a more comprehensive and rigorous evaluation than prior efforts.
However, the authors acknowledge some limitations of the current benchmark. The datasets, while carefully curated, may not fully capture the breadth and complexity of classical Chinese literature. Additionally, the evaluation metrics, while tailored to each sub-task, may not perfectly align with human judgments of understanding.
Further research could explore expanding the benchmark to cover an even wider range of classical Chinese texts and tasks. There may also be opportunities to incorporate more qualitative, human-centric evaluation approaches to complement the existing quantitative metrics.
Overall, the C3Bench represents a significant contribution to the field of large language model evaluation, and the insights it provides will be valuable for developers working to push the boundaries of classical Chinese understanding.
Conclusion
The C3Bench is a comprehensive benchmark designed to assess the performance of large language models on a wide range of classical Chinese understanding tasks. By covering translation, question answering, summarization, and more, the benchmark provides a thorough evaluation of a model's capabilities, going beyond simple surface-level pattern matching.
The rigorous design and evaluation methodology of the C3Bench make it a valuable tool for researchers and developers working to advance the state-of-the-art in classical Chinese natural language processing. While the benchmark has some limitations, it represents an important step forward in benchmarking the understanding of this important and challenging domain of language.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
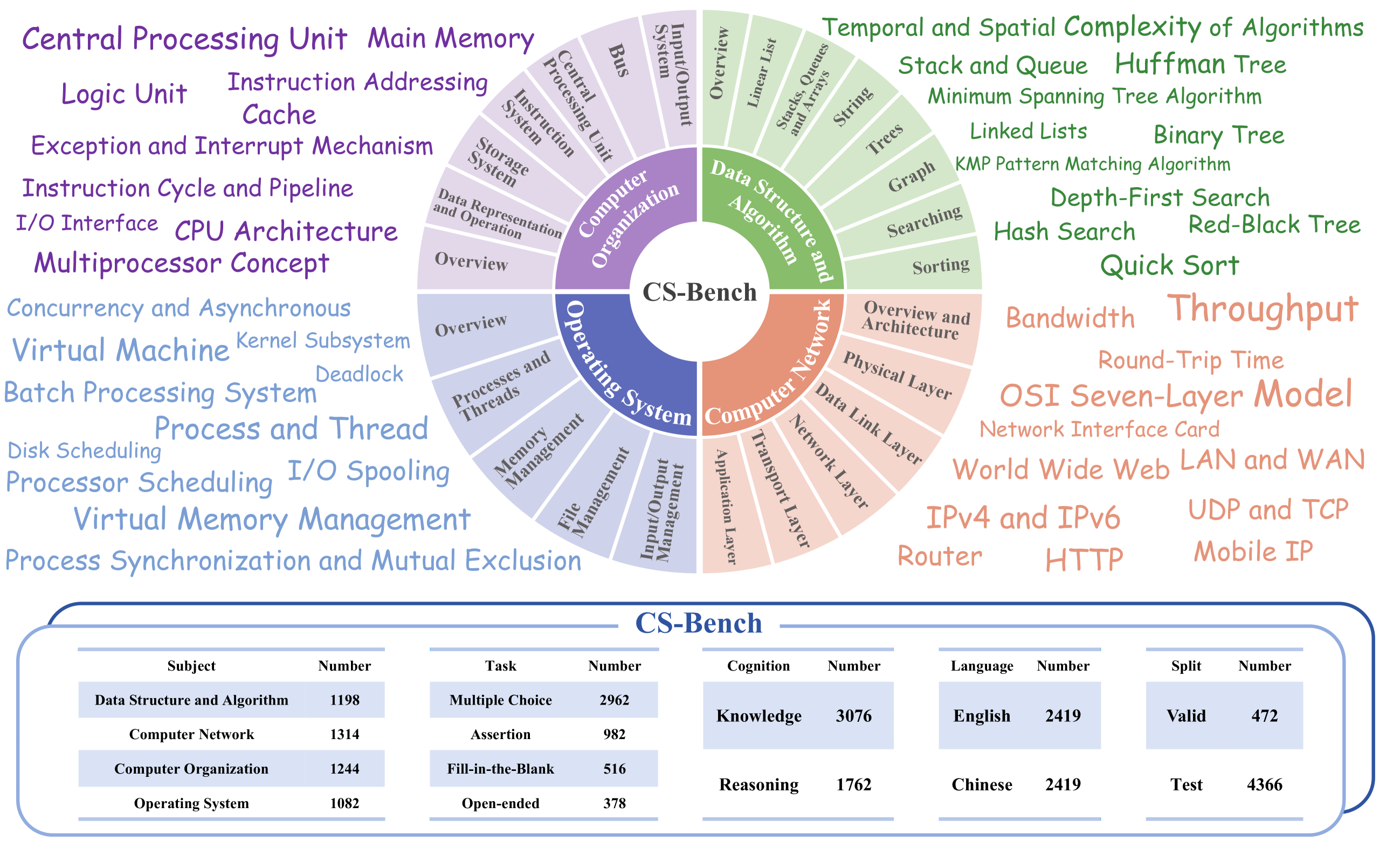
CS-Bench: A Comprehensive Benchmark for Large Language Models towards Computer Science Mastery
Xiaoshuai Song, Muxi Diao, Guanting Dong, Zhengyang Wang, Yujia Fu, Runqi Qiao, Zhexu Wang, Dayuan Fu, Huangxuan Wu, Bin Liang, Weihao Zeng, Yejie Wang, Zhuoma GongQue, Jianing Yu, Qiuna Tan, Weiran Xu
0
0
Computer Science (CS) stands as a testament to the intricacies of human intelligence, profoundly advancing the development of artificial intelligence and modern society. However, the current community of large language models (LLMs) overly focuses on benchmarks for analyzing specific foundational skills (e.g. mathematics and code generation), neglecting an all-round evaluation of the computer science field. To bridge this gap, we introduce CS-Bench, the first bilingual (Chinese-English) benchmark dedicated to evaluating the performance of LLMs in computer science. CS-Bench comprises approximately 5K meticulously curated test samples, covering 26 subfields across 4 key areas of computer science, encompassing various task forms and divisions of knowledge and reasoning. Utilizing CS-Bench, we conduct a comprehensive evaluation of over 30 mainstream LLMs, revealing the relationship between CS performance and model scales. We also quantitatively analyze the reasons for failures in existing LLMs and highlight directions for improvements, including knowledge supplementation and CS-specific reasoning. Further cross-capability experiments show a high correlation between LLMs' capabilities in computer science and their abilities in mathematics and coding. Moreover, expert LLMs specialized in mathematics and coding also demonstrate strong performances in several CS subfields. Looking ahead, we envision CS-Bench serving as a cornerstone for LLM applications in the CS field and paving new avenues in assessing LLMs' diverse reasoning capabilities. The CS-Bench data and evaluation code are available at https://github.com/csbench/csbench.
6/14/2024

TCMBench: A Comprehensive Benchmark for Evaluating Large Language Models in Traditional Chinese Medicine
Wenjing Yue, Xiaoling Wang, Wei Zhu, Ming Guan, Huanran Zheng, Pengfei Wang, Changzhi Sun, Xin Ma
0
0
Large language models (LLMs) have performed remarkably well in various natural language processing tasks by benchmarking, including in the Western medical domain. However, the professional evaluation benchmarks for LLMs have yet to be covered in the traditional Chinese medicine(TCM) domain, which has a profound history and vast influence. To address this research gap, we introduce TCM-Bench, an comprehensive benchmark for evaluating LLM performance in TCM. It comprises the TCM-ED dataset, consisting of 5,473 questions sourced from the TCM Licensing Exam (TCMLE), including 1,300 questions with authoritative analysis. It covers the core components of TCMLE, including TCM basis and clinical practice. To evaluate LLMs beyond accuracy of question answering, we propose TCMScore, a metric tailored for evaluating the quality of answers generated by LLMs for TCM related questions. It comprehensively considers the consistency of TCM semantics and knowledge. After conducting comprehensive experimental analyses from diverse perspectives, we can obtain the following findings: (1) The unsatisfactory performance of LLMs on this benchmark underscores their significant room for improvement in TCM. (2) Introducing domain knowledge can enhance LLMs' performance. However, for in-domain models like ZhongJing-TCM, the quality of generated analysis text has decreased, and we hypothesize that their fine-tuning process affects the basic LLM capabilities. (3) Traditional metrics for text generation quality like Rouge and BertScore are susceptible to text length and surface semantic ambiguity, while domain-specific metrics such as TCMScore can further supplement and explain their evaluation results. These findings highlight the capabilities and limitations of LLMs in the TCM and aim to provide a more profound assistance to medical research.
6/4/2024

Benchmarking Large Language Models on CFLUE -- A Chinese Financial Language Understanding Evaluation Dataset
Jie Zhu, Junhui Li, Yalong Wen, Lifan Guo
0
0
In light of recent breakthroughs in large language models (LLMs) that have revolutionized natural language processing (NLP), there is an urgent need for new benchmarks to keep pace with the fast development of LLMs. In this paper, we propose CFLUE, the Chinese Financial Language Understanding Evaluation benchmark, designed to assess the capability of LLMs across various dimensions. Specifically, CFLUE provides datasets tailored for both knowledge assessment and application assessment. In knowledge assessment, it consists of 38K+ multiple-choice questions with associated solution explanations. These questions serve dual purposes: answer prediction and question reasoning. In application assessment, CFLUE features 16K+ test instances across distinct groups of NLP tasks such as text classification, machine translation, relation extraction, reading comprehension, and text generation. Upon CFLUE, we conduct a thorough evaluation of representative LLMs. The results reveal that only GPT-4 and GPT-4-turbo achieve an accuracy exceeding 60% in answer prediction for knowledge assessment, suggesting that there is still substantial room for improvement in current LLMs. In application assessment, although GPT-4 and GPT-4-turbo are the top two performers, their considerable advantage over lightweight LLMs is noticeably diminished. The datasets and scripts associated with CFLUE are openly accessible at https://github.com/aliyun/cflue.
5/20/2024
🤔
LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, Juanzi Li
0
0
Although large language models (LLMs) demonstrate impressive performance for many language tasks, most of them can only handle texts a few thousand tokens long, limiting their applications on longer sequence inputs, such as books, reports, and codebases. Recent works have proposed methods to improve LLMs' long context capabilities by extending context windows and more sophisticated memory mechanisms. However, comprehensive benchmarks tailored for evaluating long context understanding are lacking. In this paper, we introduce LongBench, the first bilingual, multi-task benchmark for long context understanding, enabling a more rigorous evaluation of long context understanding. LongBench comprises 21 datasets across 6 task categories in both English and Chinese, with an average length of 6,711 words (English) and 13,386 characters (Chinese). These tasks cover key long-text application areas including single-doc QA, multi-doc QA, summarization, few-shot learning, synthetic tasks, and code completion. All datasets in LongBench are standardized into a unified format, allowing for effortless automatic evaluation of LLMs. Upon comprehensive evaluation of 8 LLMs on LongBench, we find that: (1) Commercial model (GPT-3.5-Turbo-16k) outperforms other open-sourced models, but still struggles on longer contexts. (2) Scaled position embedding and fine-tuning on longer sequences lead to substantial improvement on long context understanding. (3) Context compression technique such as retrieval brings improvement for model with weak ability on long contexts, but the performance still lags behind models that have strong long context understanding capability. The code and datasets are available at https://github.com/THUDM/LongBench.
6/21/2024